标签:ssi one ima global 训练 pos mic 计算 enc
自然语言处理,NLP,接下来的几篇博客将从四方面来展开:
自然语言处理,NLP,接下来的几篇博客将从四方面来展开:
(一)基本概念和基础知识
(二)Embedding
(三)Text classification
(四)Language Models
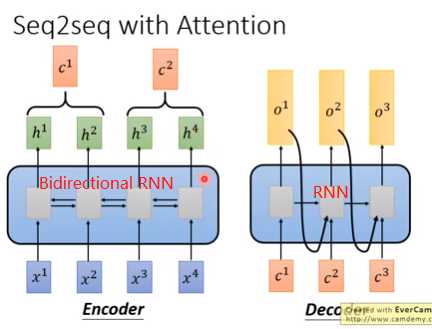
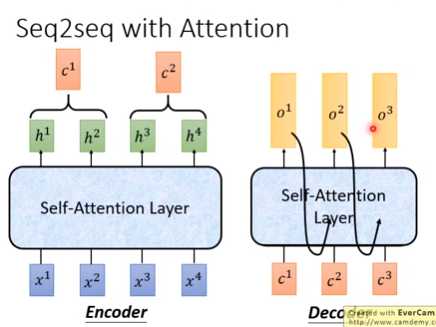
(五)Seq2seq/Attention
(六)Expectation-Maximization
(七)Machine Translation
attention可以知道大概内容,需要更详细内容适合,去Decoder找。
attention可以认为是一种Soft对齐。
顺序依赖,无法并行,速度慢;
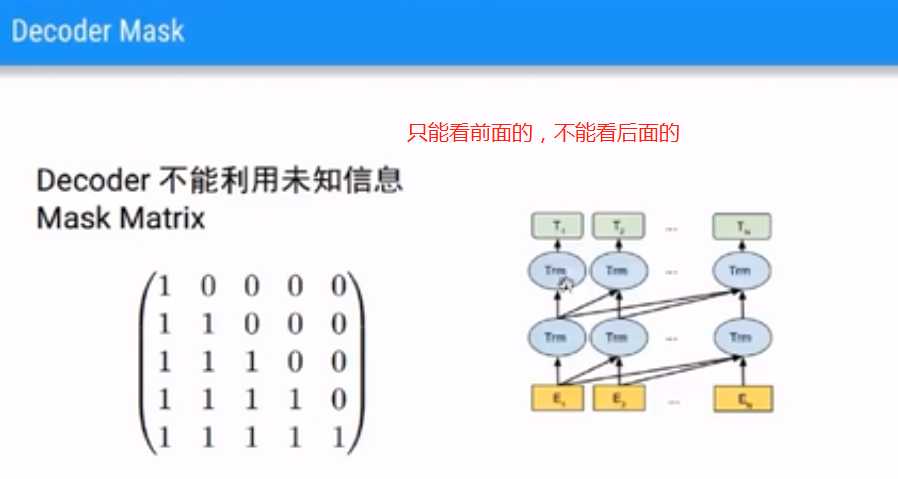
单向信息流。编码一个词的时候,需要看前后。
普通attention需要外部“驱动”,来做内容提取。
①自驱动,编码第t个词,用当前状态驱动。
②Self-attention和全连接网络FNN区别
Self-attention每一个输出需要全部输入,而FNN不需要全部输入,只要有a1就可以计算b1,不需要a2。
③Self-attention与普通attention对比
可以认为普通attention是Self-attention的一种特例。
普通attention中,query是decoder的隐状态。key和value是encoder的输出。
Self-attention中,query、key和value都是来自当前的向量,都是通过变换矩阵来学习的。
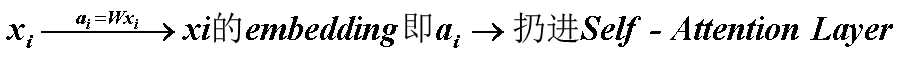

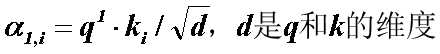
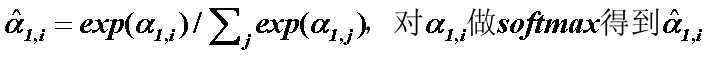
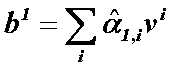
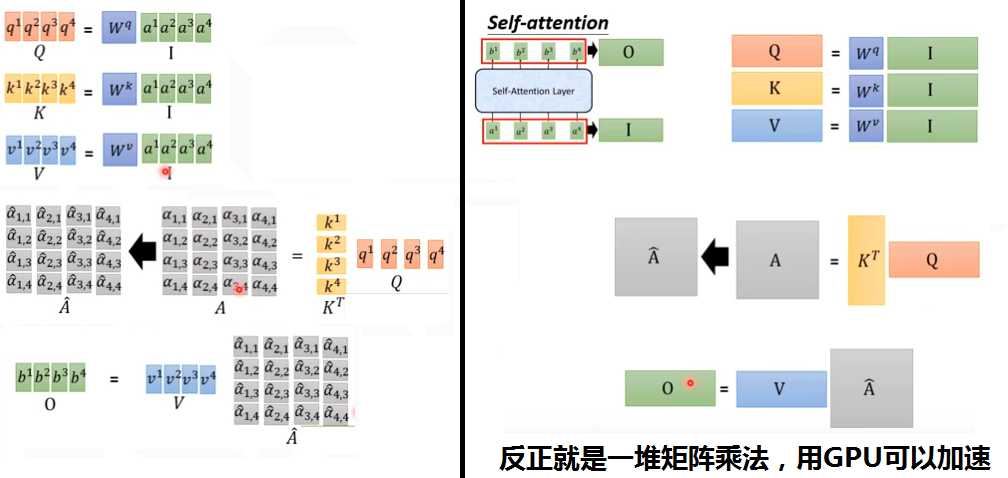
①多个Attention(Q,K,V)。
②也可能一种Attention head是给it做消解的,一种关注上下位的,一种关注首都国家对应关系的。每一种attention都可以把向量变成Q K V。
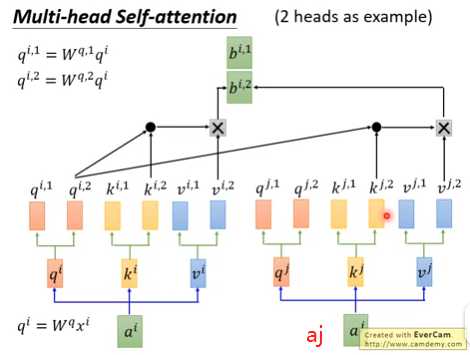
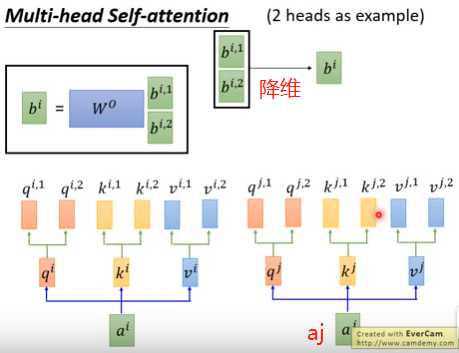
③如果有8个head,3个输入单词a1 a2 a3,则有8个bi1~bi8,拼成一个8维的向量,信息有冗余,需要降维。需要乘一个8*1的矩阵,压缩成1个数bi,最后输出是3个数b1 b2 b3。
④下图是2个head的示意图。
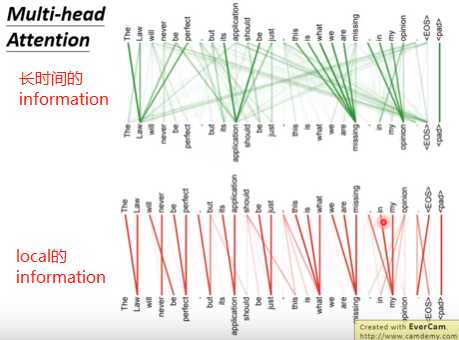
①不同head关注点不一样,每个head可以专注于自己的任务。下图,有的attention head关注local的邻居的资讯,有的关注的是global的长时间的资讯。
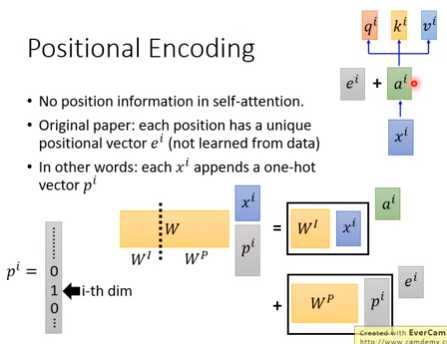
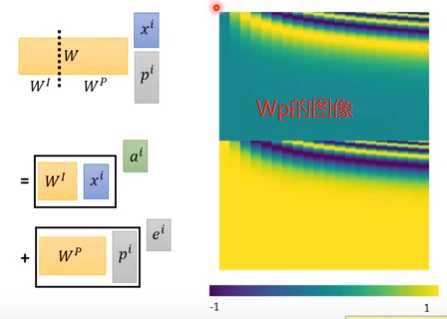
Self-attention不考虑顺序/位置因素,因此需要加入位置信息。
把ei加到ai里面。ei是手动设计的。
每一个xi接上一个one-hot向量pi,W·xi之后,就得到ai+ei,而Wp需要手工设计。
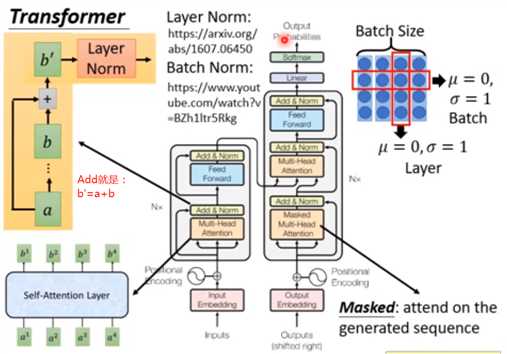
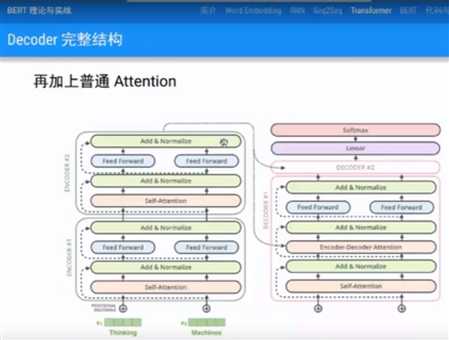
多层Encoder和Decoder,可以并行计算,因此可以训练很深。
每一层有,Encoder,Decoder。Encoder有Self-Attention层和Feed Forward全连接层;Decoder比Encoder多一个普通的Encoder-Decoder Attention,翻译时候用来考虑Encoder输出做普通Attention。
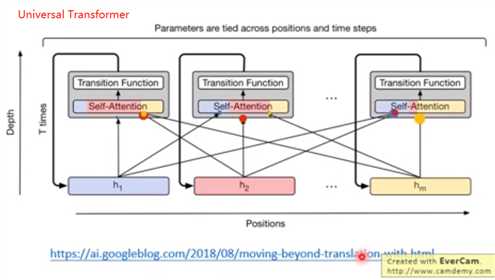
横向,时间上是m个Transformer,纵向是RNN。

RNN问题:没有双向信息流,不能并行计算。Transformer通过Self-attention和Positional encoding解决了RNN的问题。
缺点:数据稀疏问题仍然未解决
数据稀疏仍是个问题。机器翻译可以有很多语料,但是其他任务没有语料,Transformer可以学习,但是需要监督数据来驱动,数据还是太少。
问题:Word Embedding无上下文;监督数据太少。
解决方案:用Contextual Word Embedding。考虑上下文的Embedding;无监督。
https://www.bilibili.com/video/BV1GE411o7XE?from=search&seid=8158434315525640721
https://www.bilibili.com/video/BV1H441187js?p=4
标签:ssi one ima global 训练 pos mic 计算 enc
原文地址:https://www.cnblogs.com/sybil-hxl/p/12883083.html