标签:unittest 获取 mes not 页面 else 图片 style oct
代码:
1 import unittest 2 from game import Game 3 class GameTest(unittest.TestCase): 4 def test_gameOver(self): 5 self = Game(‘15‘,‘13‘) 6 def gameOver(a,b): 7 if a>=10 and b>=10: 8 if abs(a-b)==2: 9 return True 10 if a<10 or b<10: 11 if a==11 or b==11: 12 return True 13 else: 14 return False 15 from random import random 16 def printIntro(): 17 print("兵乓球比赛结果预测") 18 def getInputs(): 19 a = eval(input("请输入选手A的能力值(0-1): ")) 20 b = eval(input("请输入选手B的能力值(0-1): ")) 21 x = eval(input("模拟比赛的场次: ")) 22 return a, b, x 23 24 def simNGames(x, probA, probB): 25 winsA, winsB = 0, 0 26 for i in range(x): 27 scoreA, scoreB = simOneGame(probA, probB) 28 print(scoreA,scoreB) 29 if scoreA > scoreB: 30 winsA += 1 31 else: 32 winsB += 1 33 return winsA, winsB 34 def simOneGame(probA, probB): 35 scoreA, scoreB = 0, 0 36 serving = "A" 37 while not gameOver(scoreA, scoreB): 38 if serving == "A": 39 if random() < probA: 40 scoreA += 1 41 else: 42 serving="B" 43 else: 44 if random() < probB: 45 scoreB += 1 46 else: 47 serving="A" 48 49 return scoreA, scoreB 50 def gameOver(a,b): 51 if (a>=11 and abs(a-b)>=2) or (b>=11 and abs(a-b)>=2): 52 return True 53 54 def printSummary(winsA, winsB): 55 x = winsA + winsB 56 print("竞技分析开始,共模拟{}场比赛".format(x)) 57 print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA, winsA/x)) 58 print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB, winsB/x)) 59 def main(): 60 printIntro() 61 probA, probB, x = getInputs() 62 winsA, winsB = simNGames(x, probA, probB) 63 printSummary(winsA, winsB) 64 main() 65 66 unittest.main()
结果:

代码:
1 import requests 2 for i in range(20): 3 r = requests.get("https://www.sogou.com") 4 print("网页返回状态:{}".format(r.status_code)) 5 print("text内容为:{}".format(r.text)) 6 print("\n") 7 print("text内容长度为:{}".format(len(r.text))) 8 print("content内容长度为:{}".format(len(r.content)))
结果:

代码:
1 from bs4 import BeautifulSoup 2 import re 3 soup=BeautifulSoup(‘‘‘<!DOCTYPE html> 4 <html1> 5 <head> 6 <meta charset="utf-8"> 7 <title>菜鸟教程(runoob.com)</title> 8 </head> 9 <body> 10 <hl>我的第一标题</hl> 11 <p id="first">我的第一个段落。</p> 12 </body> 13 <table border="1"> 14 <tr> 15 <td>row 1, cell 1</td> 16 <td>row 1, cell 2</td> 17 </tr> 18 <tr> 19 <td>row 2, cell 1</td> 20 <td>row 2, cell 2</td> 21 <tr> 22 </table> 23 </html>‘‘‘) 24 print("head标签:\n",soup.head,"\n学号后两位:03") 25 print("body标签:\n",soup.body) 26 print("id为first的标签对象:\n",soup.find_all(id="first")) 27 st=soup.text 28 pp = re.findall(u‘[\u1100-\uFFFDh]+?‘,st) 29 print("html页面中的中文字符") 30 print(pp)
结果:
代码:
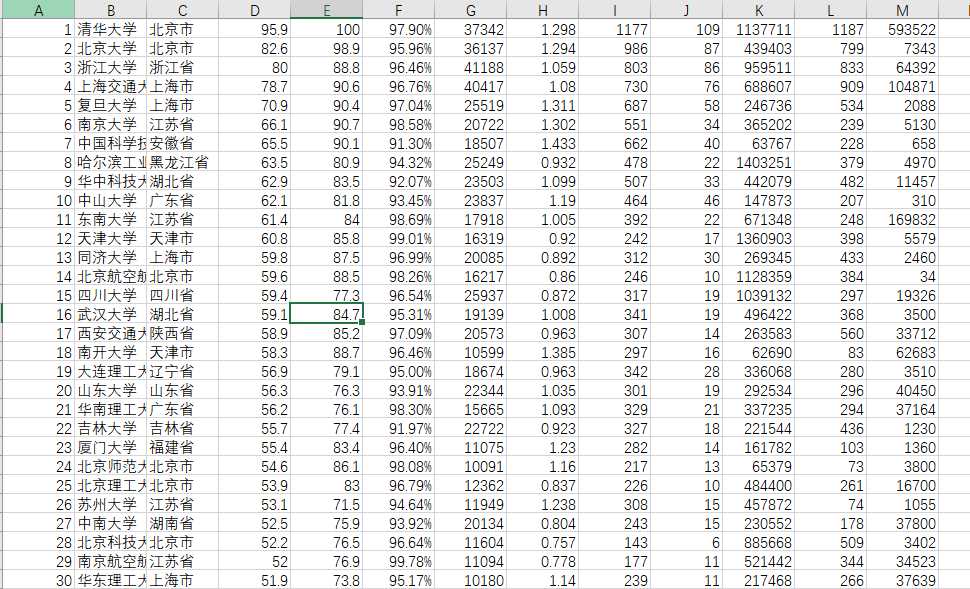
1 import csv 2 import os 3 import requests 4 from bs4 import BeautifulSoup 5 allUniv = [] 6 def getHTMLText(url): 7 try: 8 r = requests.get(url, timeout=30) 9 r.raise_for_status() 10 r.encoding =‘utf-8‘ 11 return r.text 12 except: 13 return "" 14 def fillUnivList(soup): 15 data = soup.find_all(‘tr‘) 16 for tr in data: 17 ltd = tr.find_all(‘td‘) 18 if len(ltd)==0: 19 continue 20 singleUniv = [] 21 for td in ltd: 22 singleUniv.append(td.string) 23 allUniv.append(singleUniv) 24 def writercsv(save_road,num,title): 25 if os.path.isfile(save_road): 26 with open(save_road,‘a‘,newline=‘‘)as f: 27 csv_write=csv.writer(f,dialect=‘excel‘) 28 for i in range(num): 29 u=allUniv[i] 30 csv_write.writerow(u) 31 else: 32 with open(save_road,‘w‘,newline=‘‘)as f: 33 csv_write=csv.writer(f,dialect=‘excel‘) 34 csv_write.writerow(title) 35 for i in range(num): 36 u=allUniv[i] 37 csv_write.writerow(u) 38 title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模", 39 "科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化","学生国际化"] 40 save_road="E:\\排名.csv" 41 def main(): 42 url = ‘http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html‘ 43 html = getHTMLText(url) 44 soup = BeautifulSoup(html, "html.parser") 45 fillUnivList(soup) 46 writercsv(save_road,30,title) 47 main()
结果:
标签:unittest 获取 mes not 页面 else 图片 style oct
原文地址:https://www.cnblogs.com/tantan0914/p/12884350.html