标签:png max 正态分布 https csdn 因此 改进 opp 原则
1.数据竞赛流程

数据分析主要目的是分析数据原有的分布和内容;
特征工程目的是从数据中抽取出有效的特征;
模型训练与验证部分包括数据划分的方法以及数据训练的方法;
模型融合参考我的另一篇介绍模型融合的博客。
1.1.数据分析
在拿到数据之后,首先要做的就是要数据分析(Exploratory Data Analysis,EDA)。数据分析是数 据挖掘中重要的步骤,同时也在其他阶段反复进行。可以说数据分析是数据挖掘中至关重要的一步,它给之后的步骤提供了改进的方向,也是直接可以理解数据的方式。拿到数据之后,我们必须要明确以下几件事情:
(1)数据是如何产生的,数据又是如何存储的;
(2)数据是原始数据,还是经过人工处理(二次加工的);
(3)数据由那些业务背景组成的,数据字段又有什么含义;
(4)数据字段是什么类型的,每个字段的分布是怎样的;
(5)训练集和测试集的数据分布是否有差异;
(6)在分析数据的过程中,还必须要弄清楚的以下数据相关的问题:
(7)数据量是否充分,是否有外部数据可以进行补充;
(8)数据本身是否有噪音,是否需要进行数据清洗和降维操作;
(9)赛题的评价函数是什么,和数据字段有什么关系;
(10)数据字段与赛题标签的关系;
1.2数据清洗
数据清洗步骤主要是对数据的噪音进行有效剔除。
(1)对于类别变量,可以统计比较少的取值;
(2)对于数字变量,可以统计特征的分布异常值;
(3)数据缺失处理
缺失值的产生的原因多种多样,主要分为机械原因和人为原因。机械原因是由于机械原因导致的数据收集或保存的失败造成的数据缺失,比如数据存储的失败,存储器损坏,机械故障导致某段时间数据未能收集(对于定时数据采集而言)。人为原因是由于人的主观失误、历史局限或有意隐瞒造成的数据缺失,比如,在市场调查中被访人拒绝透露相关问题的答案,或者回答的问题是无效的,数据录入人员失误漏录了数据。对于缺失值的处理,从总体上来说分为删除存在缺失值的个案和缺失值插补。
(4)数据异常处理
首先我们需要对异常值有个理解,一般来说,异常值通常被称为“离群点”,对于异常值的处理,通常使用的方法有很多种,第一就是简单的统计分析,第二就是使用3∂原则处理,第三就是箱型图分析,第四就是基于模型检测,第五就是基于距离检测,第六就是基于密度检测,第七就是基于聚类。下面我们就分别为大家介绍一下这些方法。
首先给大家介绍一下简单的统计分析,当我们拿到数据后可以对数据进行一个简单的描述性统计分析,譬如最大最小值可以用来判断这个变量的取值是否超过了合理的范围,不合常理的为异常值。
第二就是3∂原则,如果数据服从正态分布,在3∂原则下,异常值为一组测定值中与平均值的偏差超过3倍标准差的值。如果数据服从正态分布,距离平均值3∂之外的值出现的概率为P(|x-u| > 3∂) <= 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
第三就是箱型图分析,一般来说,箱型图提供了识别异常值的一个标准:如果一个值小于QL01.5IQR或大于OU-1.5IQR的值,则被称为异常值。QL为下四分位数,表示全部观察值中有四分之一的数据取值比它小;QU为上四分位数,表示全部观察值中有四分之一的数据取值比它大;IQR为四分位数间距,是上四分位数QU与下四分位数QL的差值,包含了全部观察值的一半。一般来说,箱型图判断异常值的方法以四分位数和四分位距为基础,四分位数具有鲁棒性:25%的数据可以变得任意远并且不会干扰四分位数,所以异常值不能对这个标准施加影响。因此箱型图识别异常值比较客观,在识别异常值时有一定的优越性。
1.3特征预处理
1.3.1归一化(为了消除特征数据之间量纲的影响,如果不进行归一化,那么由于特征向量中不同特征的取值相差较大,会导致目标函数变“扁”。这样在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路,即训练时间过长):
(a)最大最小标准化(Min-Max Normalization):比较适用在数值比较集中的情况;
![]()
(b)Z-score标准化方法:要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕
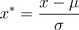
数据处理后符合标准正态分布,即均值为0,标准差为1
(c)非线性归一化:经常用在数据分化比较大的场景,有些数值很大,有些很小。该方法包括 log,正切等,需要根据数据分布的情况,决定非线性函数的曲线
1.3.2对于类别特征来说,有如下处理方式:
自然数编码(Label Encoding)、独热编码(Onehot Encoding)、哈希编码(Hash Encoding)、统计编码(Count Encoding)、目标编码(Target Encoding)、嵌入编码(Embedding Encoding)、缺失值编码(NaN Encoding)、多项式编码(Polynomial Encoding)、布尔编码(Bool Encoding)
1.3.3对于数值特征来说,有如下处理方式:
取整(Rounding)、分箱(Binning)、放缩(Scaling)、缺失值处理、用属性所有取值的平均值代替、用属性所有取值的中位数代替、用属性所有出现次数最多的值代替、丢弃属性缺失的样本、让模型处理缺失值
1.4特征工程
特征工程本质做的工作是,将数据字段转换成适合模型学习的形式,降低模型的学习难度。可以从一下几个角度构建新的特征:
(1)数据中每个字段的含义、分布、缺失情况;
(2)数据中每个字段的与赛题标签的关系;
(3)数据字段两两之间,或者三者之间的关系;
参考链接:
https://blog.csdn.net/Datawhale/article/details/100981726
https://blog.csdn.net/w47478/article/details/104874580/
https://www.cnblogs.com/zhengzhicong/p/12728491.html#_label0_2
标签:png max 正态分布 https csdn 因此 改进 opp 原则
原文地址:https://www.cnblogs.com/USTC-ZCC/p/12885523.html