标签:决策 平台 机器 图文 联网 font tree 包含 城市
几种软件架构
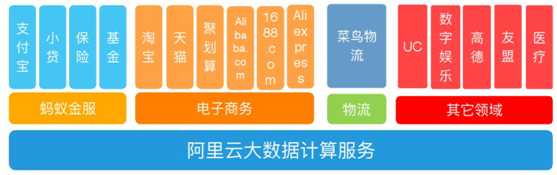
一.阿里云大数据架构
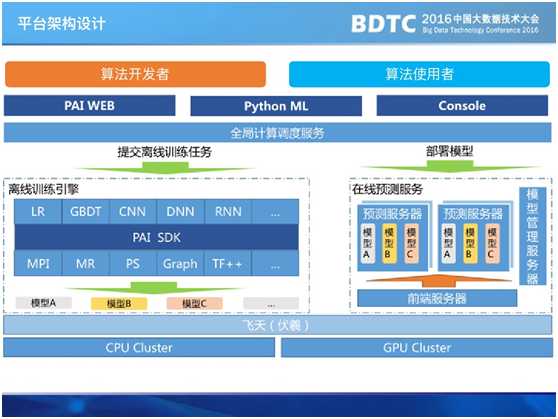
二.今日头条推荐算法架构
推荐系统,如果用形式化的方式去描述实际上是拟合一个用户对内容满意度的函数,这个函数需要输入三个维度的变量。第一个维度是内容。头条现在已经是一个综合内容平台,图文、视频、UGC小视频、问答、微头条,每种内容有很多自己的特征,需要考虑怎样提取不同内容类型的特征做好推荐。第二个维度是用户特征。包括各种兴趣标签,职业、年龄、性别等,还有很多模型刻划出的隐式用户兴趣等。第三个维度是环境特征。这是移动互联网时代推荐的特点,用户随时随地移动,在工作场合、通勤、旅游等不同的场景,信息偏好有所偏移。结合三方面的维度,模型会给出一个预估,即推测推荐内容在这一场景下对这一用户是否合适。

三.AI 的架构
人工智能的架构分为三层:应用层、技术层和基础层。
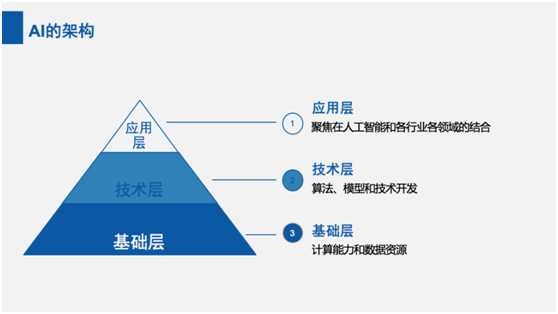
应用层聚焦在人工智能和各行业各领域的结合。技术层是算法、模型和技术开发。基础层则是计算能力和数据资源。
各层架构再进行细分如下:
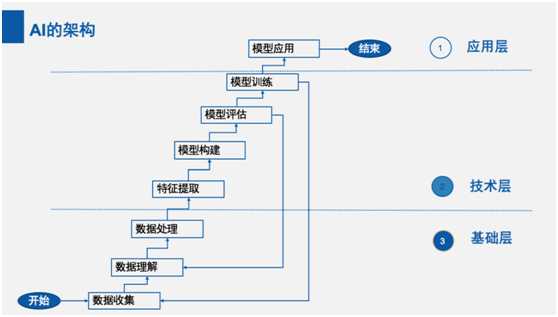
数据收集:获取什么类型的数据,数据可以通过那些途径获取。常见的数据来源是采集、购买或其他方式获取现有数据。
比如中山大学的资深机器学习研究专家梁浩林就分享到,城市地理学领域的数据采集渠道,可以同步获取一些社交APP,比如Yahoo Flickr、Sina Webo的checkin数据,手机的信号数据,用户GPS的轨迹数据等等。
数据理解:获取到原始数据之后,分析数据里面有什么内容、数据准确性如何,为下一步的预处理做准备。
比如我们拍摄的各种照片,需要从中识别出包含人脸的照片。
数据预处理:原始数据可能会有环境影响或者干扰因素,格式化也不好,所以为了保证预测的准确性和有效性,需要进行数据的预处理。
常见的比如调整照片亮度、对比度、锐化等等。
特征提取:将数据里有用的,有典型特征的抽取出来。
比如,对几千张有效照片进行分类,特征包括性别、头发眼睛皮肤颜色、轮廓、脸型等等。
模型构建:使用适当的算法,获取预期准确的值。
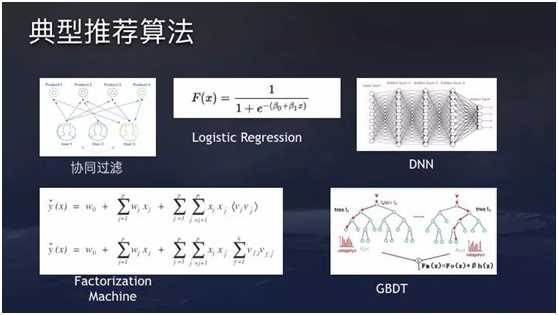
常用的分类算法包括:决策树分类法(Decision Tree),朴素贝叶斯分类算法(Native Bayesian Classifier)、基于支持向量机(SVM)的分类器、神经网络法(Neural Network)、k-最近邻法(k-nearest neighbor,kNN) 语义树、知识库、各种视觉算法等等等。至于各种算法的区别,我还在学习中。
模型评估:通常对一个模型进行评估的标准有准确率、查全率。
查准率 =检索出的相关信息量/检索出的信息总量
查全率=检索出的相关信息量/系统中的相关信息总量
狭义上的理解拿人脸识别来讲,假设数据库中存在的10个用户的照片,我对这10个用户进行拍照,识别出来库中包含的人脸有7个,这7个中识别正确的有5个,那么查准率=5/10=50%;查全率就是7/10=70%。另外就是,假设我对1个用户,操作十次,出来的结果是否十次均和实际匹配。我认为也是模型评估的一个标准。
模型训练:根据模型评估的结果,对模型进行不断的训练甚至是调整,以达到更好的效果。
模型应用:将模型部署、应用到实际场景中。
可以回到AI 基本概念和应用中的人脸识别开门场景,来看看如何跟我们的 AI 架构对应的。
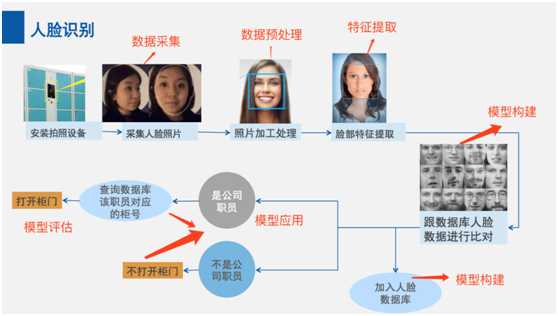
从AI 的结构很容易可以看出来。
人工智能的核心是基础层,即计算能力和refreshing data flow (持续的数据流)。
所以大公司愿意投入人工智能和发展人工智能,因为大公司有数据,尤其是Google、Facebook、亚马逊、苹果,还有国内的BAT。数据是大公司的一个优势。
于是现在有一个声音会认为:大公司不具备的医疗、基金、金融等数据,可能会是小公司、人工智能初创企业突破的机会。
技术层的核心主要在于:特征提取,模型与算法选择。
标签:决策 平台 机器 图文 联网 font tree 包含 城市
原文地址:https://www.cnblogs.com/wujianming-110117/p/12890612.html