标签:信息 写代码 ado pid full gc heap sele 就会 文件
某天晚上,收到系统CPU占用过高报警,立刻登录服务器查看cpu信息(top,命令即可),此时CPU占用率高达750%+, 查看GC日志,频繁的发生Full GC, 并且一次Full GC市场可达到6s,立刻使用jmap命令dump文件(命令:jmap -dump:file=heap.bin
把dump的文件从服务器弄下来,然后使用MAT工具分析(dump的文件有点大,注意调整MAT内存大小,对MAT不熟悉的老铁,看看这个网址 MAT 官方文档)。
使用MAT文件,看大这个首页,通过这个首页可以看到dump的时候,系统是什么情况,什么线程持有多大对象,都可以看出来。
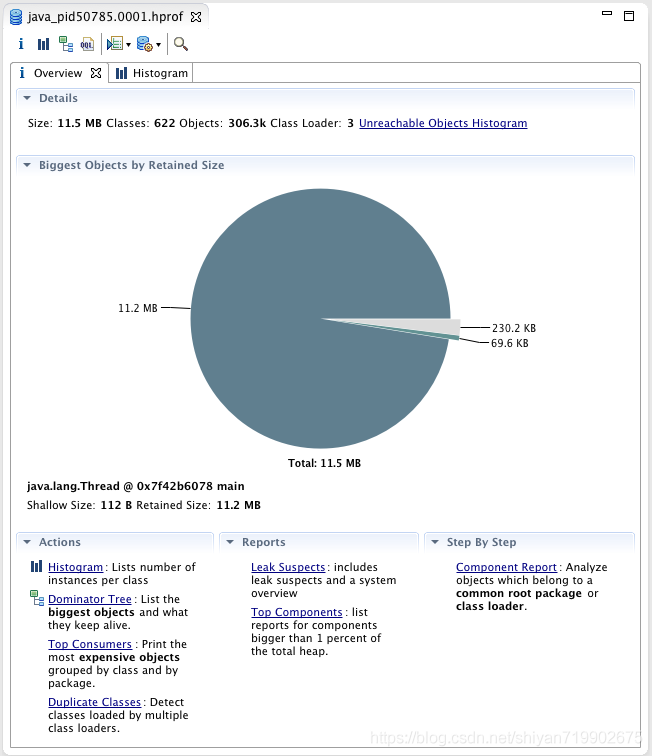
这个当然不是主要对,点击进入Histogran,可以看到内存中,什么对象最多。如图:
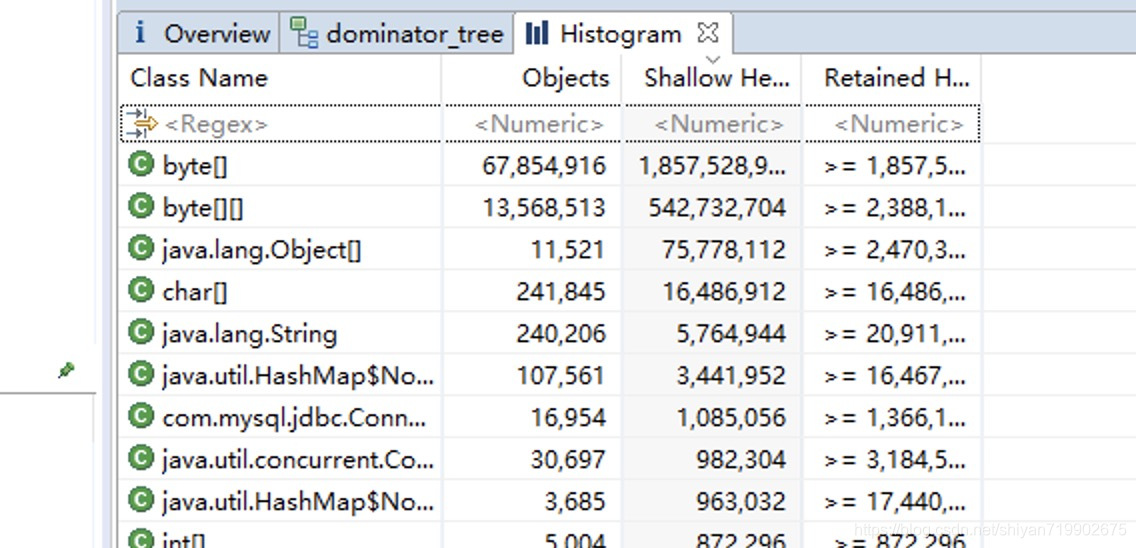
很惨,只能看到是byte[]数组最多,没有特别多的有用价值,接着打开Dominator Tree, 这个里面有大致请求
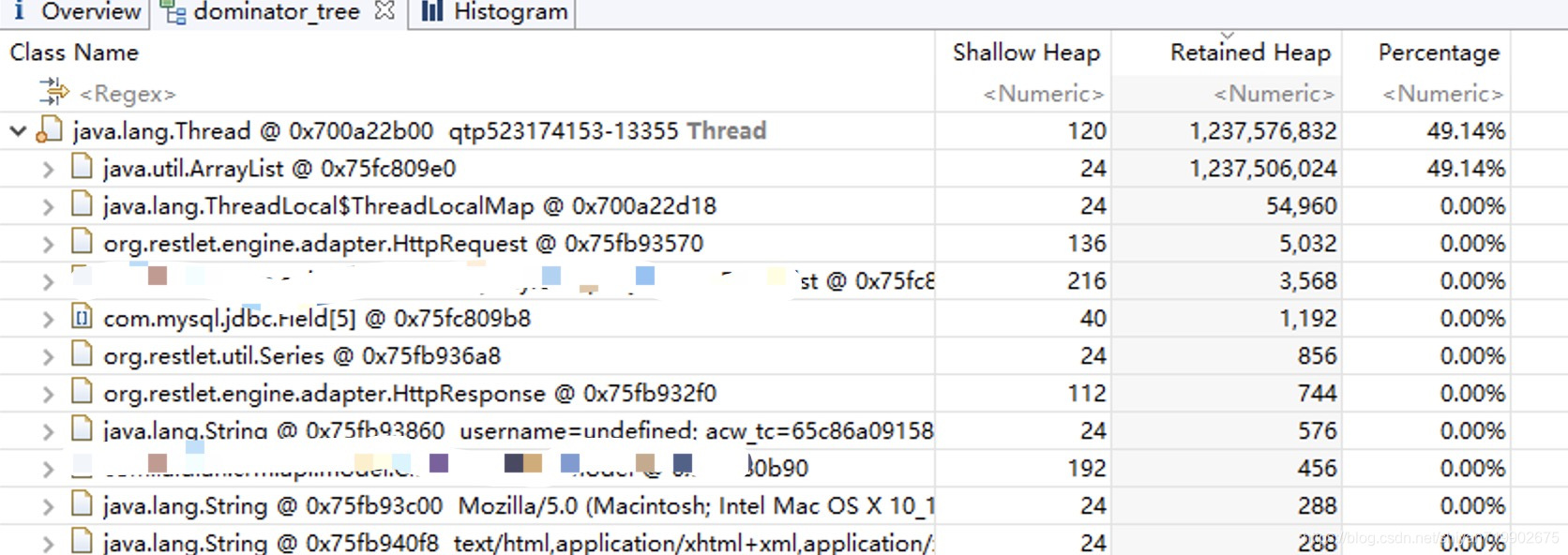
很惨,只是发现了是ArrayList对象过大,里面存了很多东西,咋办呢?
好了,我们不卖关子了, 上面是分析的一部分,有时候可以直接看出什么对象过多,便于确定问题,接下来是我认为重要的部分。线程堆栈信息。
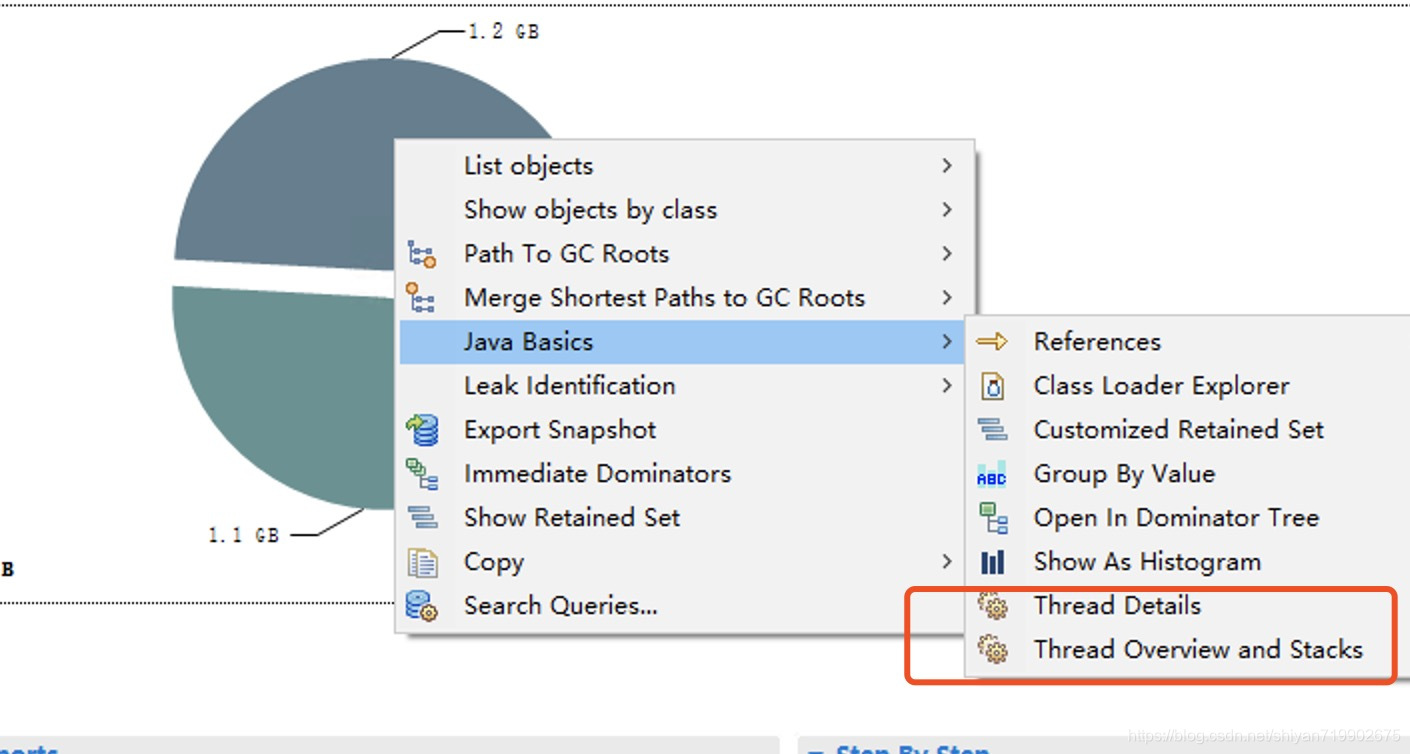
点击首页这个线程信息,找到Java Basics,可以看到有两个关于线程堆栈信息的, 点进去我们,我们就可以看到当前线程的信息。话不多说,点进去。
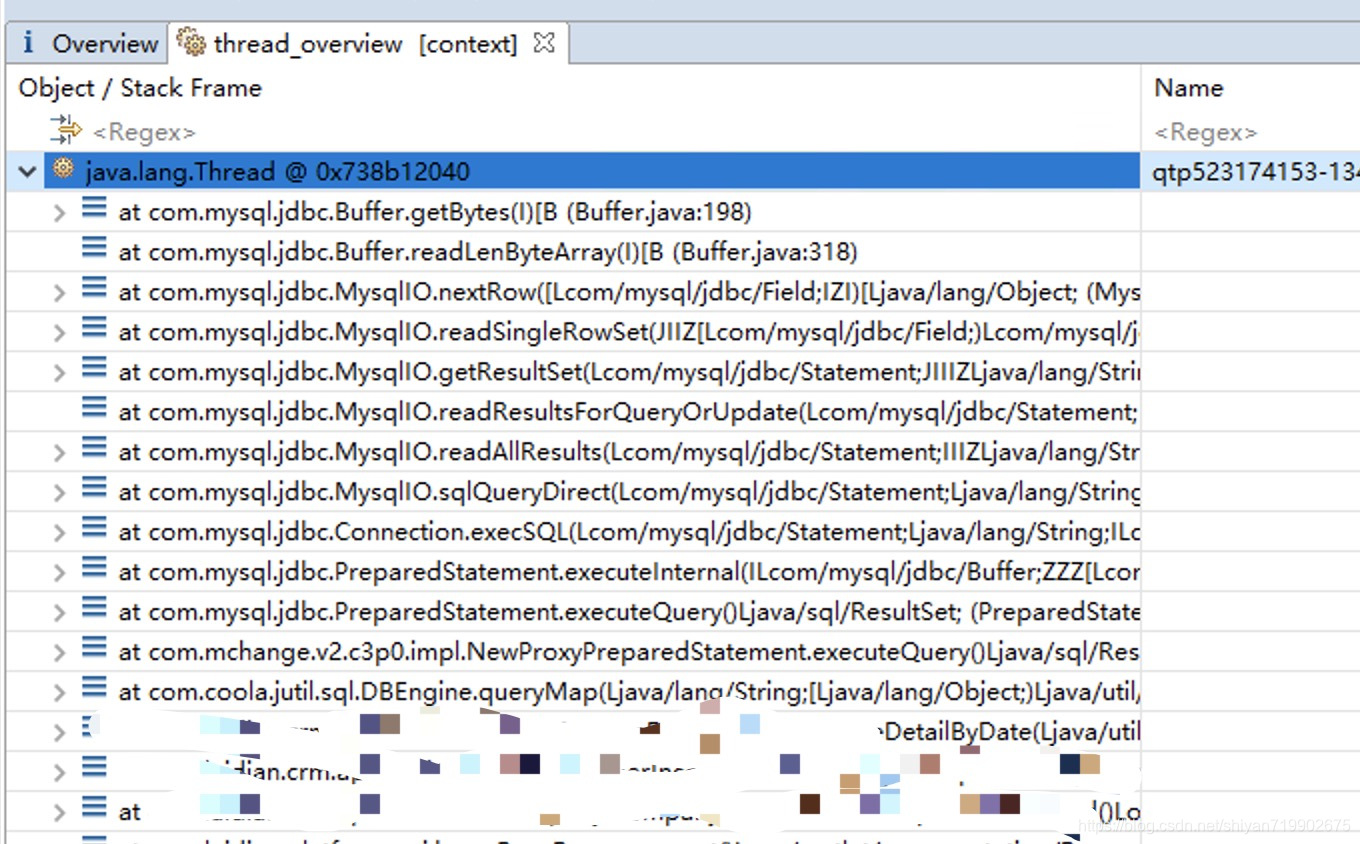
好家伙,点进来发现了线程的堆栈信息,这么多链接,一看就是数据库操作的问题了,找到具体的代码调用栈(图中马赛克是具体代码信息)。找到具体的代码信息,就可以去研究代码了。
至此,我们找到了出现问题的地方,就可以具体到代码中出现问题的原因了。
通过分析代码, 我们发现,是代码在拼接sql的过程中,由于条件缺失,导致sql的查询条件被无线放大,所以,查询出来数据表中的超级多数据( ̄□ ̄||)。给大家举个例子,如下。
public void example() {
// tb_name 表里 create_time > ‘2020-01-01‘ 有几百万条记录
String sql = "select * from tb_name where 1 =1 and create_time > ‘2020-01-01‘ ";
int a = 0;
int b = 10;
if (a < -1) {
sql += " and user_id = " + a;
}
if (b > 5) {
sql += "and age > " + b;
}
q.query(sql);
}
最后修改代码,重新上线, 问题得到彻底解决。
大家在写代码的时候,特别注意条件的判断,对传入的数据进行一定的校验,通过自己判断,及早的返回结果,否则小心就会进行如上事故了。当然,有的老铁自己公司,对sql进行aop拦截,涉及到查询的,一般会有一个最大返回量(mybatis plus 3.+版本好像有实现,太久没注意哈),这种也是一种可取的方案。
MAT工具是要梯子下载的哈,没有的老铁可以多找找
标签:信息 写代码 ado pid full gc heap sele 就会 文件
原文地址:https://www.cnblogs.com/lifacheng/p/12892121.html