标签:关注 学院 机械 发布 完成 带来 实例 min 客户
《从头搭建持续集成 DevOps 流水线》由资深敏捷教练、极限编程学院高级讲师、CODING 特邀敏捷顾问李小波老师主讲,将基于 CODING 展示如何编写 Jenkinsfile 搭建 CI/CD 流水线,包括单元测试,端到端测试,代码规范检查,制品库,Docker 化部署。

大家好,今天课程的主要内容为如何从头搭建 DevOps 流水线以及其在研发工作中的意义,最后是 DevOps 流水线实践与敏捷开发的关系的总结。

最开始是在极限编程里提出了持续集成,然后 ThoughtWorks 又提出了持续交付,之后又提出了DevOps 这个概念,为什么要做这些呢?我认为原因是随着时间的增长,生产力会不断的下降。团队刚开始时效率很高,从 0 到 1,功能上线很快,但是到了后期速度就会越来越低,直到最后开发停滞。系统开发的后期往往会出现三个难点:第一,增加新特性难。随着系统功能的累积,会出现很多重复的代码以及不合理的设计,导致增加一个新特性时要改的地方非常多,改动成本非常高;第二,修复缺陷难。用户可能会报一些缺陷或 Bug,但是因为代码太乱、太复杂导致很难定位到缺陷;第三,引出新的缺陷。做新 Feature 时,很容易出现打地鼠的现象,按下一个 Bug 结果又冒出来三个 Bug,给团队带来困境。
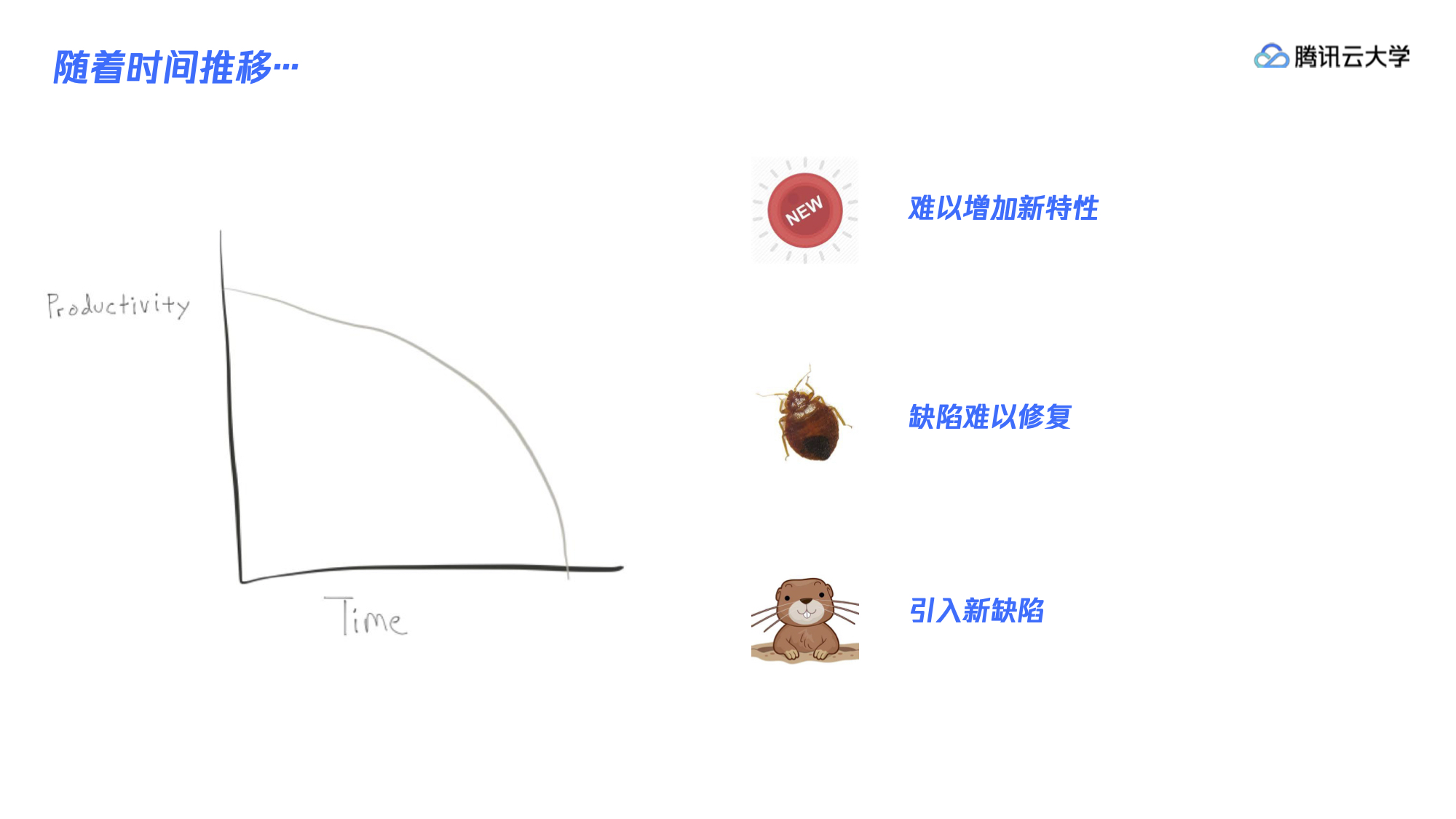
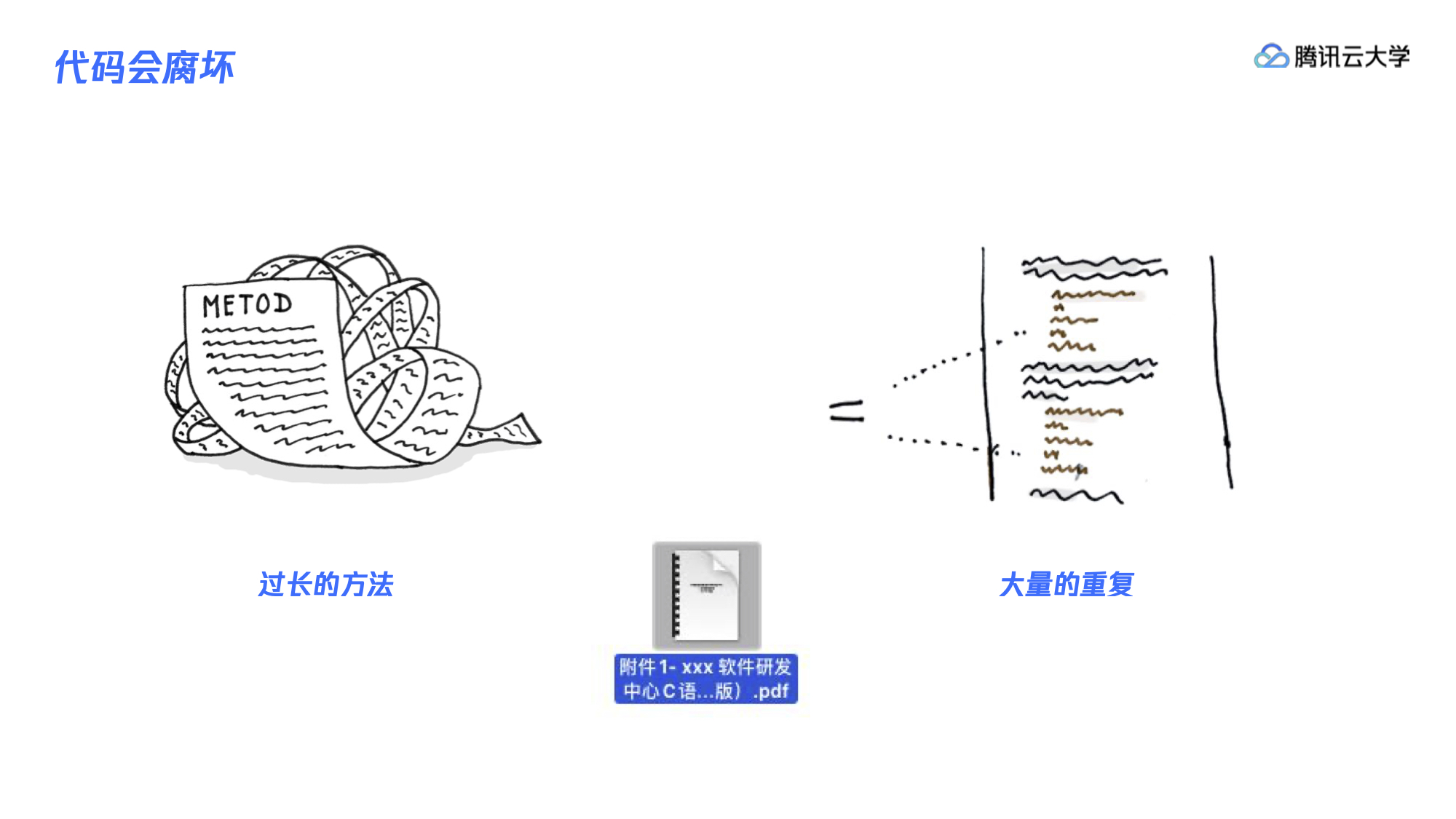
出现这些现象的原因首先是在需求演变的过程中,有的代码会不断地腐坏,方法会越来越长,类会变得越来越大,代码出现大量的重复。虽然有些团队会制定代码规范,但在实际应用中,可能基本上都在 Word 或 PDF 里“躺着”,检查执行难以长期坚持。
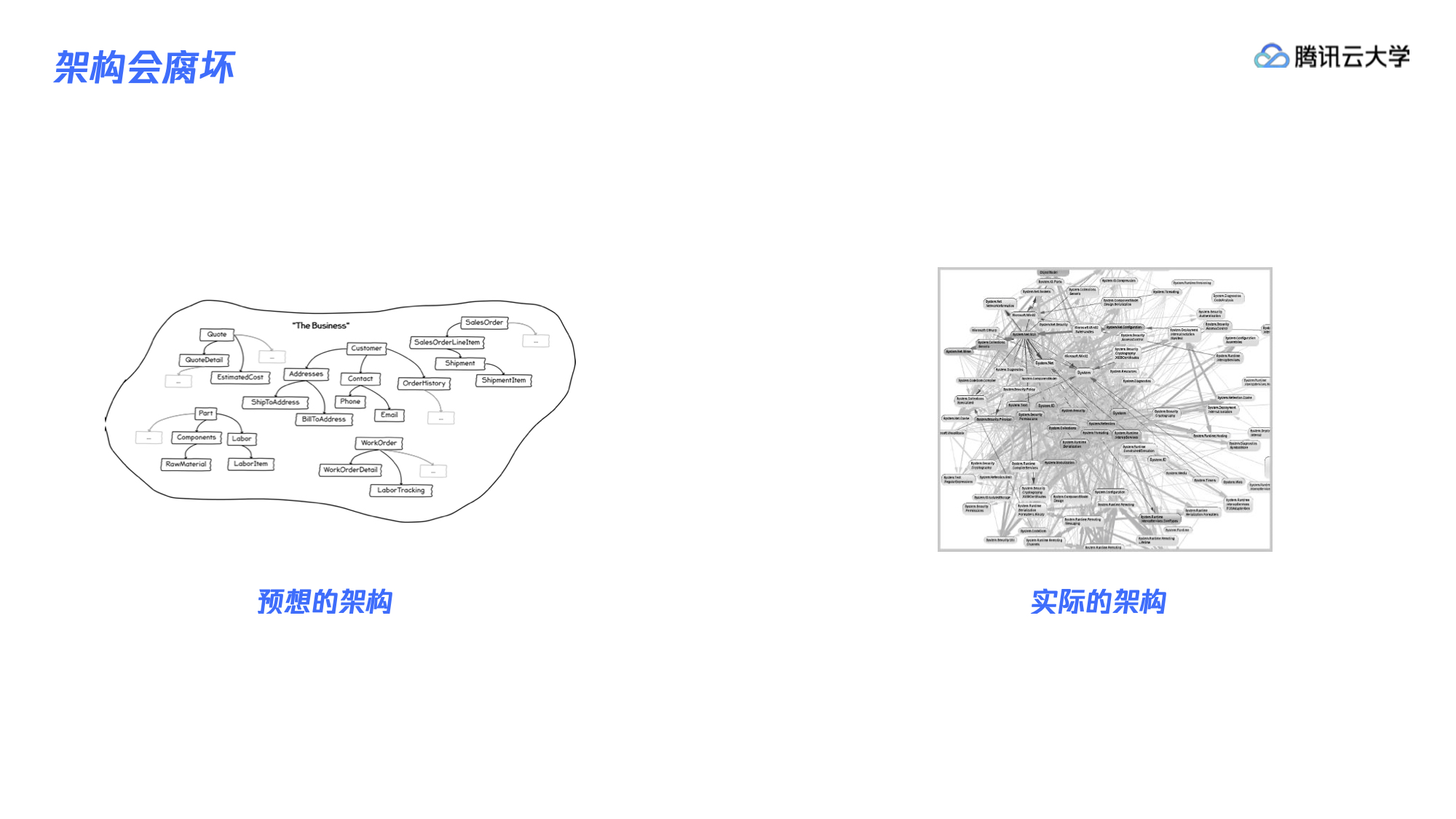
其次是架构也会腐坏。项目开始时架构师通常会根据业务设计好架构,有多少个模块、对象,分到几层,哪层可以调,哪层不能调,怎么依赖关系,这些都会很清楚,但在不断的演变过程中,架构往往会变得乱七八糟。
戴明(William Edwards Deming)提出了质量内建的概念,即产品的质量在建设过程中就已经嵌入,并不是靠后期的检测来发现的。后期的检测并不能增进代码质量,也不能提升产品质量,问题发现的越早修复的成本越低。所以我们希望每一次往代码库提交代码时,都能够马上获得反馈:这次修改是好的还是不好的,是不是增加了重复的代码,是不是降低了测试覆盖率,是不是破坏了某一些功能等等。有了这样的评判标准,就能够始终保证每个人每次提交代码都是在产品上增加价值,而不是破坏它。在这个背景下就引入了流水线这个概念。
流水线是一个隐喻,意思是将软件研发的各个环节衔接起来。我认为流水线在研发管理过程中扮演了三个角色:不辞辛劳的临时工、铁面无私的守护者以及快速精准的操作员。
流水线是不辞辛劳的临时工。现在的构建流水线都可以按需创建。比如说 CODING,这么多的企业在用它的持续集成功能,不可能给每一个用户分配固定的计算、存储等资源。如果要能线性的增长,策略应该是当用户需要构建时会按需进行创建,并且用完之后进行销毁。从这一点上看,流水线就很像一个临时工。除此之外,流水线还可以不厌其烦地做重复的事情,尤其是持续集成的团队每天都要提交很多次代码,每一次提交都人工做一次检查就很痛苦,但机器就能重复机械运动。
流水线是铁面无私的守护者。首先是代码规范。很多开发团队的代码规范都“活”在 Word 或 PDF 里,即使有资深教练或者技术 Leader 偶尔会做一些代码评审,这种执行力度也是远远不够的。但是通过集成到流水线中的方式,比如指定一个方法不能超过多少行,一个类不能超过多少行,代码重复率不能超过多少,代码的宽度及命名等,进行自动化、标准化的检测,就可以有效的保证代码规范的落地;第二是测试覆盖率。在日常的开发工作中会有单元测试、组件测试、接口测试、集成测试、端到端测试等多种测试,每一次提交代码都需要检查测试覆盖率有没有下降。但很多团队这一块是缺失的,他们在流水线上只是做了构建、打包、部署等动作,并没有跑测试覆盖率,而是靠大规模的手工测试来保证质量,导致无法快速迭代;第三是架构约束。代码一般有分层,每一层里应该放什么文件,哪个文件能够调哪个文件,这些都是有约束的,需要一套自动化的机制来保证落地;其次还有安全性检查。比如做 Web 开发会引入一些第三方的开源代码,这些开源代码往往会有安全缺陷,需要在每次引入新内容时进行安全性检查。
流水线是快速精准的操作员。越复杂的系统,环境就越多,包括开发联调环境、测试环境、预发布环境等,到正式的环境还会有多个实例。每个环境上访问数据库的 URL 不一样,访问其他服务的环境也会不一样,如何保证在操作过程中都不出错?可以依靠流水线来标准化、流程化、自动化地完成这些动作,每次代码提交时都检查规范,针对不同的环境打出不同的包,持续的部署到不同的环境上面。
那么如何搭建一条流水线?有一种方式叫做流水线即代码(Pipeline as Code),即把流水线放到代码里。我认为这样做的好处是版本化,传统的搭建方式问题在于操作没有记录,也无法强制 Review,当一台服务器挂掉,换一台服务器时需要把原来流水线的配置重新操作一遍。如果将流水线变成代码,就可以跟踪及重复创建,提高生产效率。另外补充一点,流水线在构建时主要有两种方式,一个叫声明式,一个叫指令式。声明式就是规定好环节与步骤,需要怎样的东西。而指定式需要写很多的条件判断,是逻辑式的,维护成本也会高一些,所以声明式是目前普遍采用的一种方式。

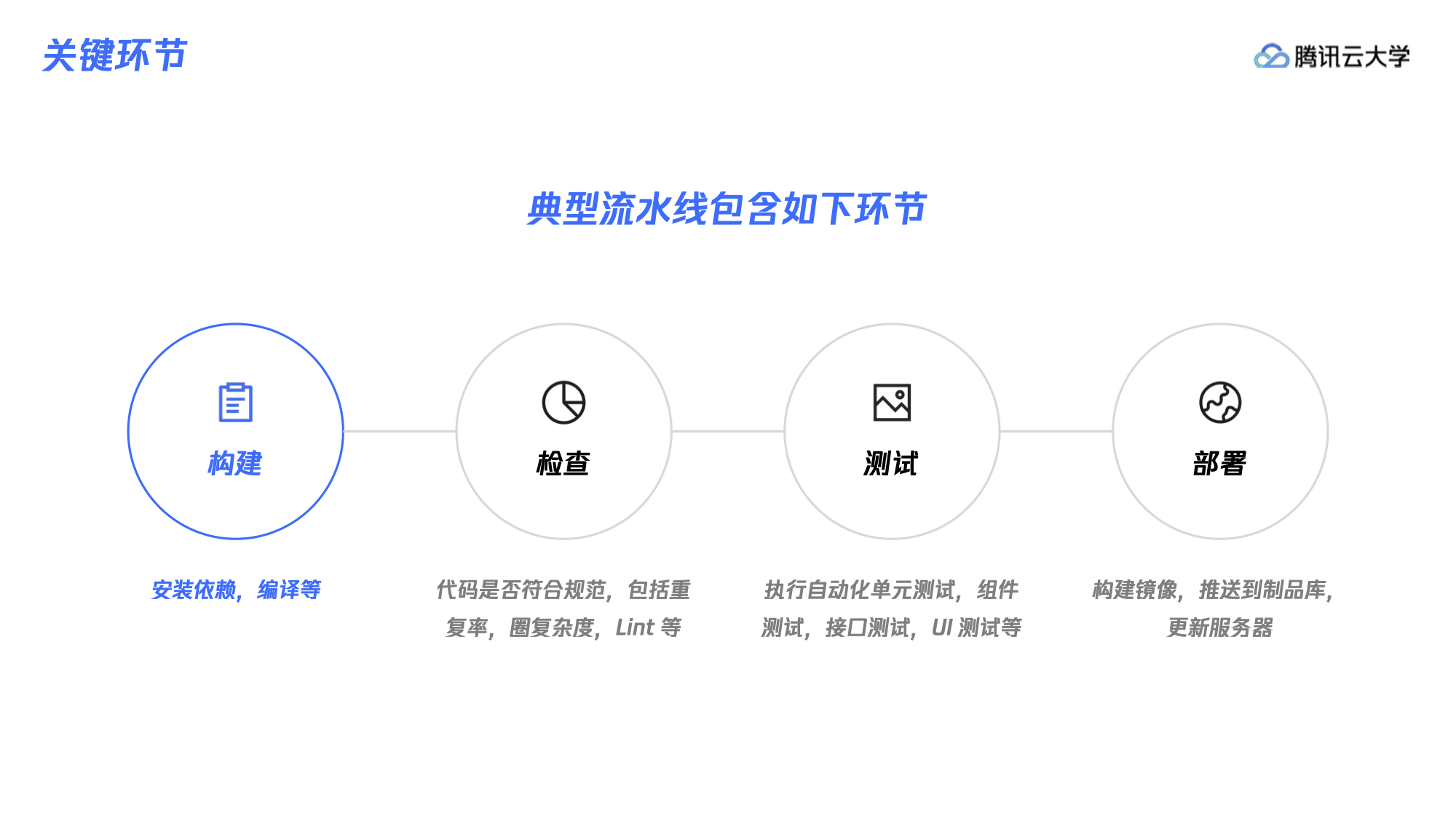
一条典型流水线应该包含四个关键环节。第一是构建。前端、后端的代码都需要编译,前端比如 HTML、JS、CSS 等,可能还会用到一些模板,需要做编译工作将其转成浏览器能够支持的格式;第二是检查。编译完成之后需要检查代码是不是符合规范,是不是有很多的重复代码,重复率超过了多少等等;第三是测试。测试环节很重要,会影响团队对于产品发布的信心。这里讲一个测试金字塔理论:底层是大量的单元测试,中间是组件测试或者接口测试,顶部是端到端测试。因为大量的逻辑都是在各种 If else 分支里,单元测试可以覆盖到这些分支,那么上层的测试就不需要再覆盖下层已经覆盖过的逻辑了。而上层测试的价值在于把这些代码集成起来,站在用户的角度去使用它,看看能否正常工作。上层和下层的测试关注点不一样,解决的问题也不一样;第四是部署。最后需要构建镜像,并推到制品库里面去,更新服务器,做完这一系列的事情之后,流水线实例就会销毁。
最后总结一下,为什么会衍生出 DevOps 实践及其跟敏捷开发的关系:
第一,我们最重要的目标是通过持续不断地及早交付有价值的软件使客户满意。我认为这跟敏捷是一脉相承的。敏捷的原则里说可工作的软件高于详尽的文档,客户更希望看到的是可用的软件,而不仅仅是文档说明,但是由于开发过程的不透明,造成了客户喜欢做微观管理的现象,同时也会让开发团队变得很被动。敏捷里有个价值观叫尊重,这种尊重是需要团队自己去赢得的。通过建立一套流程,提高开发过程的透明度,从而建立客户与团队之间的信任。另外跟敏捷原则相契合的一点是响应变化高于遵循计划。这不是一句口号,而是一种能力,它包含:项目管理能力、需求管理能力、配置管理能力以及质量保障能力。这四种能力建设起来之后,团队才能拥有响应变化的能力。持续集成、自动化测试、自动部署等这些核心能力,搭配上代码规范、CodeReview、TDD等这些实践,才能真正提升开发团队的实力,而不是仅仅把 Scrum 导入进来,开开计划会、站立会就行了。
第二,可工作的软件是进度的首要度量标准。不是每天站会或者每周写个邮件告诉客户这周完成了多少工作,而一定是部署完成后,变成了可以看到的、可以体验的功能才算是真正的进度。
第三,坚持不懈的追求技术卓越和良好的设计,敏捷能力由此增强。开发团队拥有了代码规范检查、自动化测试等这些质量门禁以后,才有底气去不断的做优化,得到可持续的、快速迭代的速率。实践都会随着技术的变化而变化,团队能力也在持续的变化,但能不能持续地保持敏捷,那就要看价值观、原则是不是能够持续地符合。

CODING 敏捷实战系列课第四讲:从头搭建持续集成 DevOps 流水线
标签:关注 学院 机械 发布 完成 带来 实例 min 客户
原文地址:https://www.cnblogs.com/codingdevops/p/12894062.html