标签:不同 技巧 评价 标记 目标 col 算法 方式 nbsp
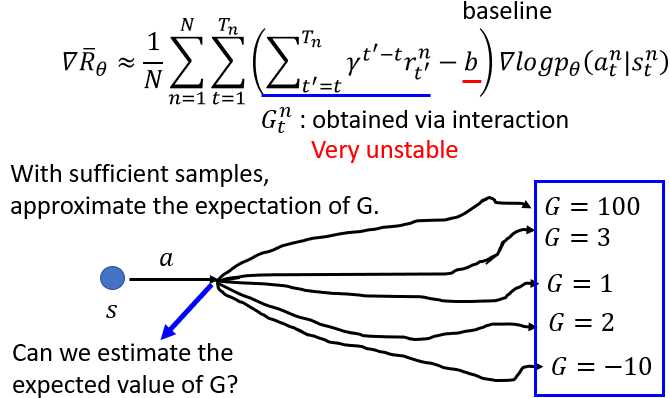
在之前的Policy Gradient算法中,其运行结果不够稳定的至少一条原因是:奖励项不够稳定。
下图中,蓝色实现标记的当前和随后的奖励累积和,作为评判??生成的轨迹的好坏度量,即通过累积和修正????????_??。
但是,该累积和受到了策略网络??的影响很大。在相同的行为下,因为概率问题,使得最终的路径大不相同,从而导致了不同的累积和。因此,该累积和无法稳定的度量,策略网络??生成的轨迹。
在Q-learning之类的算法中,使用状态值函数V(s),选择最大的状态价值对应的行为a,或使用状态行为对Q(s,a),输出对应最大奖励r的行为a。
在该链接中有一张图如下作为参考,不知道对不对:https://zhuanlan.zhihu.com/p/26308073
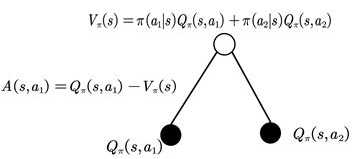
在Actor-Critic算法下,对Policy Gradient做了一些修正如下:共有两处,一处Q的期望,一处V的价值。
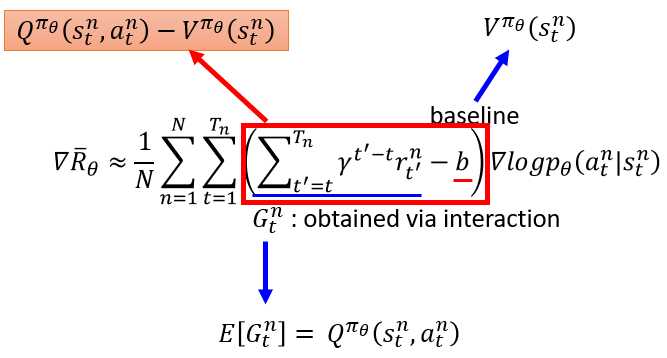
为了计算方便和一些经验判断思考,做了两处替换:
Q网络和V网络的问题是,因为Q和V在实际操作过程中,没有足够和有效的的采样,是有偏差的估计值。使用Q-V来计算,则使得两个模型的偏差值更大。因此,将Q使用V来表示。这样的表示是严谨的吗,
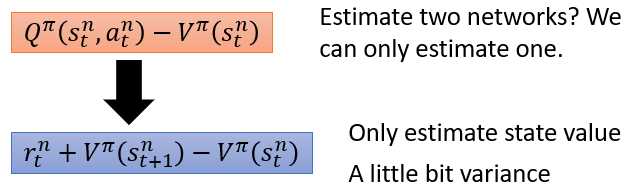
其中在之前使用的是Q的期望,但是实际操作中,实现条件和表达问题,去掉了期望部分。
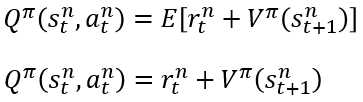
最终的更新公式如下:其中V表示一个网络,Critic网络。另外的策略网络??,输出行为,对应的????????_??部分。
Critic网络,梯度下降,最小化目标为Q-V的部分,Actor网络,梯度上升,最大化目标函数,从而增强评价中,策略输出行为更优方向,的概率。
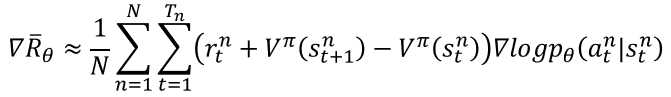
另外,有一些技巧是,如果是像素输入,则可共用卷积神经网络。另外,使用熵对??做正则化,使得动作输出的信息量更大,更有利于探索。

A3C算法,使用了异步方式。
标签:不同 技巧 评价 标记 目标 col 算法 方式 nbsp
原文地址:https://www.cnblogs.com/bai2018/p/12894187.html