标签:hql 驱动 令行 接口 数据管理 http 自定义函数 pre code
Hive架构前面我们讲解了hive是什么,下面我们接着来看一下hive的架构。
在讲解hive的架构前,我们先看一下hadoop的生态系统图,看一下hive到底在hadoop生态系统中占据着什么位置。
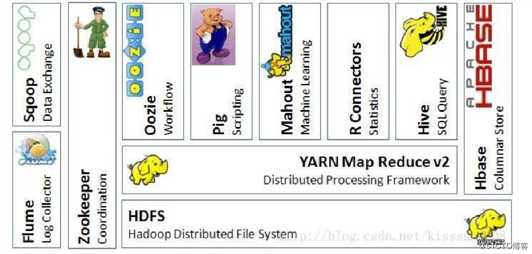
这张图上所有的框架我们在后续都会给大家介绍。
通过上图,我们可以看到hive的下面是yarn、MapReduce、HDFS,这和我们对hive的定义是一样的。在hive的右侧是Hbase,这就说明hive可以和HBase进行集成。可以看到hive在整个hadoop生态系统中还是占据着比较重要的位置的。
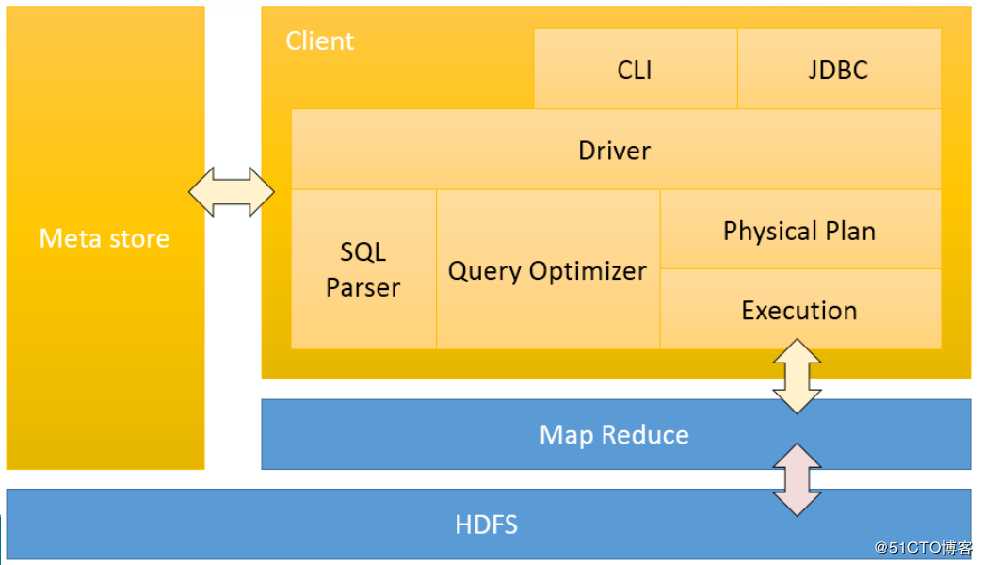
我们先看这张图的蓝色部分,我们可以看到这就是MapReduce和HDFS,这一部分我们就比较熟悉了。
在回想下hive的本质,就是讲HQL语句转换成MapReduce程序进行在yarn上执行。那么现在底层的MapReduce和HDFS我们清楚了。那用户是如何提交HQL语句到hive的呢?
这就是上图中的右上部分,用户可以通过cli(命令行)或者java调用jdbc的方式通过Hive的驱动将HQL提交给Hive。
hive在接收到HQL语句时要进行以下四部的处理:
我们看到上图的左侧还有个MetaStore,这个是什么呢?这个就是hive的元数据。我们来解释下什么是元数据。我们知道hive是讲一定的日志数据转换成数据表的形式,那是不是需要记录表的名字与存储在HDFS文件系统上文件的对应关系,是不是需要知道每一个列数据的名称。这些就组成了hive的元数据。hive通过查找元数据才能清楚的知道要去查找那个文件等等。
元数据默认存储在自带的derby数据库中,推荐使用MySQL存储Metestore。
标签:hql 驱动 令行 接口 数据管理 http 自定义函数 pre code
原文地址:https://blog.51cto.com/13452232/2495843