标签:failure 它的 经典 expand mda width oid grid 生成
==> 有钱,无脑瞎烧 GPU。
https://blog.csdn.net/u014157632/article/details/101721343
本文解读两篇基于强化学习的开创性论文:谷歌的《Neural Architecture Search with Reinforcement Learning》和MIT的《Designing Neural Network Architectures Using Reinforcement Learning》。用到的强化学习方法分别为策略梯度(Policy Gradient)和Q-learning。 |
|
使用一个RNN作为智能体。作者考虑到神经网络的结构和连接可以用一个可变长度的字符串表示,这样可以用RNN生成这样的字符串。RNN采样生成了这样的字符串,一个网络,即子网络(child network)就被确定了。训练这个子网络,得到验证集在这个网络上的准确率,作为奖励信号。然后根据奖励计算策略梯度,更新RNN。在下一轮迭代,RNN会给出可能在验证集上准确率高的一个网络结构。也就是说,RNN会随着时间提升它的搜索质量。
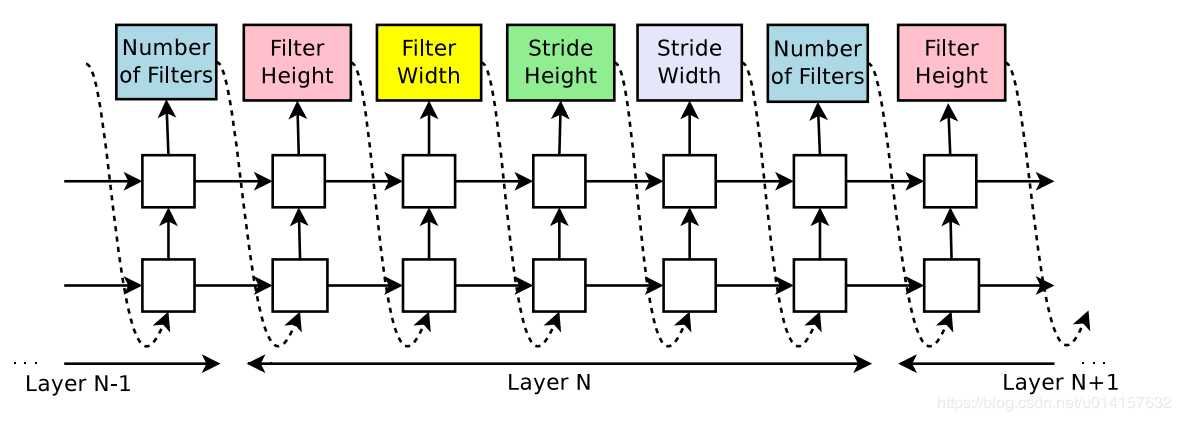
首先作者假设要生成一个前向的只包含卷积的网络(没有跨连接)。使用RNN可以生成卷积层的超参数,超参数表示为一个标记序列:RNN会预测每一层的滤波器的高度、宽度,步长的高度、宽度,和滤波器个数,一个5个参数。每一个预测是通过softmax分类器实现的,这个时间步的预测会作为下个时间步的输入。当层数达到一个特定的值,这个生成的过程就会停止。这个值会随着训练过程增加。一旦RNN生成了一个结构,即子网络,这个子网络就会被训练,验证集的准确率被记录下来被作为奖励。然后控制器RNN的参数θc\theta _{c}θc被更新以生成期望验证集准确率最大的结构。
————————————————

现代网基本都会有跨连接层,比如残差网络和谷歌网络。为了能生成类似这样的网络结构,作者用了基于注意力机制的set-selection。
主要做法就是,在RNN的预测上多加一个锚点(anchor point)。比如,在第N层的预测中,锚点会指示连接前N-1层中的哪几个。相当于有N-1个sigmoid函数,每个sigmoid是当前RNN隐藏状态和前N-1个锚点隐藏状态的函数:
然后从这些sigmoid中参与决定当前层和前几层中的哪些连接。
上面的做法可能会导致“compilation failures”。第一,如果一个层有很多个输入,那么这些输入会在特征图的深度这个维度上被连接,这可能导致各个输入特征图的尺寸不兼容。第二,有些层可能没有输入或输出。作者使用了三个技巧:(1)如果一个层没有输入,那么最一开始的图片作为输入;(2)在最后一层,我们将所有没有被连接的输出都连接起来,然后送入分类器;(3)如果输入特征图的尺寸不一致,,那就填充他们使其有相同的尺寸。
————————————————

此方法使用强化学习去搜索网络结构,由于每生成一种结构都要训练一遍并评估,而且强化学习需要采样很多很多次,整个搜索会非常耗时。在CIRAR-10数据及上搜索网络,作者用了800块GPU同时训练,可见其有多耗时耗力。NAS的方法如果都这么耗时的话是非常不划算的,如何快速有效地搜索是AutoDL努力的方向之一。
————————————————
--> 这里RL相当于 Grid search 了,哪几类、哪些结构的网络结构有效,得加启发式先验

智能体循序地选择神经网络层。选择层的过程是马尔科夫决策过程,假设在一个网络中表现最好的层在另一个网络中应该也是表现最好的。智能体通过?\epsilon?贪婪策略选择层,直到终止条件。训练在此路径下构建的网络,得到验证集上的准确率。验证集准确率和结构描述被存储起来,用于经验回放。智能体遵循着?\epsilon?变化表,从探索阶段过渡到利用阶段。
3、状态空间
每个状态被定义为相关层的所有参数组成的元组,。这里采用五种不同的层:卷积层(C),池化层(P),全连接层(FC),全局平均池化(GAP),和softmax(SM)。
————————————————
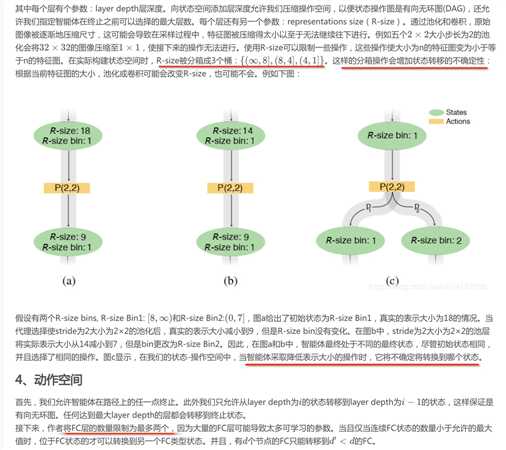
然后是一些其他的限制。卷积层可以转移到其他任何类型的层,池化层可以转移到除池化层以外的其他任何层,因为连续的池化相当于一个不在可选状态空间里的大尺寸池化层。只有R-size为(8, 4]和(4, 1]的状态才能转移到FC层,这样保证权重参数不会特别巨大。
上述所有就是此论文的核心方法,此方法也是非常耗时,对于每个数据集,作者使用10块GPU训练了8-10天。(这篇论文在写作上感觉要比上篇的好,细节清楚)
标签:failure 它的 经典 expand mda width oid grid 生成
原文地址:https://www.cnblogs.com/cx2016/p/12903185.html