标签:line 相等 span 这一 efi getc 思考 bit namespace
DP算法对于大部分题有着良好的能力,但有些题目我们要转换思维,不能直接的设具体的转态....
最近做了两道秒题,在这里分享一下:
https://ac.nowcoder.com/acm/contest/5555/A
这是第一题,看到这道题,首先是要对m质因数分解的,然后把质因子的指数提出来,使得每个质因子只剩下一个在根号里,说白了就是要化简了.要搞出来一个系数t.
之后我们考虑n个数组成t的方案数,算是一个经典的问题了,如果直接求解的话直接组合数隔板法就上了,可要求本质不同的解,考场我傻眼了...考虑dp,设f[i][j]表示用i个数拼成j的方案数...
转移很显然,可以枚举下当前的数填几,可这也是有重合的啊,会重复计数.0 2,和2 0 会被算两次....然后,我自闭了....
好吧,最后还是用dp搞得,考虑我们重复计数的原因,因为顺序问题,所以我们可以强制使得序列是从大到小的,也就是说我们每次加的值都单调不升。
那怎么搞这个东西呢,再存一下上一个的值吗?不!不!不用,我们思考当前的状态(i,j),意思是用前i个人拼成了j的方案数,考虑我们在此基础上如何增加,使得它一定是递增的.
如图:
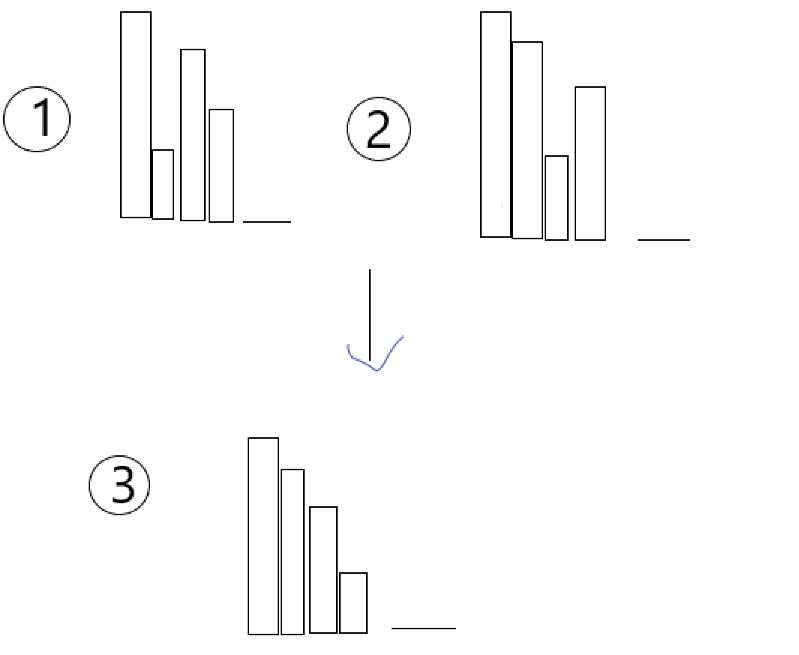
也就是说我们想让1,2两种方案只在3方案中记录一次答案,这样就能做到不重不漏了.考虑3的方案数是如何构成的.这里莫名想到算法进阶上一道线性dp的题,不过问题不大...
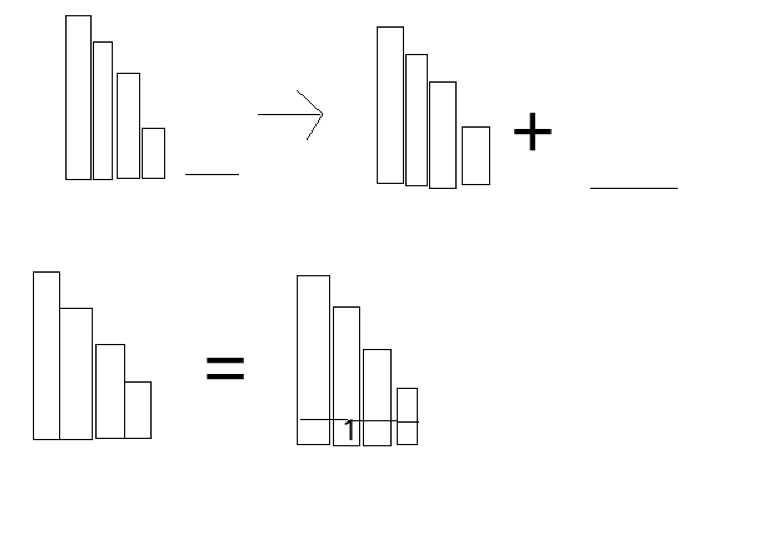
用一些巧妙的思想,若刚来的数>=1,容易发现这样的方案数和所有的数减1的方案数是相等的.因为我们只需要将所有的数加一即可.但若来的数为0的话怎么办,容易发现直接用上一维转移即可.
这里跳过了1的问题,考虑若是1的话,所有的数切掉1后第i维就没数了,那方案数不应该与i-1有关系吗?考虑这个状态下也就是第i位为1的情况,由于我们j是正序枚举的,所以这种情况已经被i这一维统计过了.所以在>=1时直接累加上即可.
由于要求总的方案数,所以这一位加啥都行..两种情况累加就行.

//不等,不问,不犹豫,不回头. #include<bits/stdc++.h> #define _ 0 #define db double #define RE register #define ll long long #define P 998244353 #define INF 1000000000 #define get(x) x=read() #define PLI pair<ll,int> #define PII pair<int,int> #define max(a,b) (a>b?a:b) #define min(a,b) (a<b?a:b) #define pb(x) push_back(x) #define ull unsigned long long #define getc(c) scanf("%s",c+1) #define put(x) printf("%d\n",x) #define putl(x) printf("%lld\n",x) #define rep(i,x,y) for(RE int i=x;i<=y;++i) #define fep(i,x,y) for(RE int i=x;i>=y;--i) #define go(x) for(int i=link[x],y=a[i].y;i;y=a[i=a[i].next].y) using namespace std; const int N=1010; int p[N],c[N],n,m,num; ll f[N][N]; inline int read() { int x=0,ff=1; char ch=getchar(); while(!isdigit(ch)) {if(ch==‘-‘) ff=-1;ch=getchar();} while(isdigit(ch)) {x=(x<<1)+(x<<3)+(ch^48);ch=getchar();} return x*ff; } int main() { //freopen("1.in","r",stdin); get(n);get(m); int t=1; rep(i,2,sqrt(m)) { if(m%i==0) { p[++num]=i; while(m%i==0) c[num]++,m/=i; } } if(m>1) p[++num]=m,c[num]=1; rep(i,1,num) { if(c[i]>=2) { while(c[i]>=2) t=t*p[i],c[i]-=2; } } f[0][0]=1; rep(i,1,n) rep(j,0,t) { if(j>=i) f[i][j]=f[i][j-i]; f[i][j]=(f[i][j]+f[i-1][j])%P; } putl(f[n][t]); return (0^_^0); } //以吾之血,祭吾最后的亡魂
第二题就更稍微......算了,还是我太菜了....
https://ac.nowcoder.com/acm/contest/5208/A
翻译一下题意:这里有n个牛,每个牛有三个朋友,让你给所有的牛编号,每对朋友间会造成编号差的绝对值的代价,求最小的代价?
一看,n<=12,爆搜啊!但,!12好像是4e8左右,爆搜说:抱歉,这超出我能搜索的范围了....
小数据我第二反应是网络流,尝试把每个奶牛拆成n个点,代表同一个奶牛的不同编号,但怎么连边呢....嗯,大概想了会,不是太会...
尝试将爆搜优化下,看能否水过去,意外的发现搜索咋优化,还不就是全排列后统计答案吗?这咋优化....
好吧,小数据应该用状压DP.谁叫状压是爆搜的优化呢?
可,状压只能表示一个牛选没选或编没编号?不会记录他的编号是几啊?完了,我又自闭了....
感觉这道题类型有点像有一次模拟考的题,让一个树内的点相互配对.最后统计哪些点出来子树,而不搞出来具体的方案..
这个题怎么说呢,我们思考当我们一个点编过号后,假若他的朋友还没编号,那无论他的朋友是几都会累加下这个编号带来1的代价.所以我们其实不用确切的知道他朋友的编号是几.我们只用知道他朋友是否已经编过号了
编过号了,无需统计代价,没编号,加上1的代价!
考虑设f[j]表示当前的状态下的最小代价,枚举所有的状态,统计下所有编过号但朋友没编号的数量,然后枚举下最后编号的是几,转移一下即可.
这里为什么要统计所有编过号的但朋友没编号的点的数量呢?因为我们刚才说的是对于当前编号,如果朋友没编号的代价为1,可如果后面朋友还没编号的话,显然就对于当前编号又要累加下代价.所以要枚举所有的点.
//不等,不问,不犹豫,不回头. #include<bits/stdc++.h> #define _ 0 #define db double #define RE register #define ll long long #define P 1000000007 #define INF 1000000000 #define get(x) x=read() #define PLI pair<ll,int> #define PII pair<int,int> #define max(a,b) (a>b?a:b) #define min(a,b) (a<b?a:b) #define pb(x) push_back(x) #define ull unsigned long long #define getc(c) scanf("%s",c+1) #define put(x) printf("%d\n",x) #define putl(x) printf("%lld\n",x) #define rep(i,x,y) for(RE int i=x;i<=y;++i) #define fep(i,x,y) for(RE int i=x;i>=y;--i) #define go(x) for(int i=link[x],y=a[i].y;i;y=a[i=a[i].next].y) using namespace std; const int N=1<<13; int f[N],n,a[15][4]; inline int read() { int x=0,ff=1; char ch=getchar(); while(!isdigit(ch)) {if(ch==‘-‘) ff=-1;ch=getchar();} while(isdigit(ch)) {x=(x<<1)+(x<<3)+(ch^48);ch=getchar();} return x*ff; } int main() { //freopen("1.in","r",stdin); get(n); rep(i,1,n) get(a[i][1]),get(a[i][2]),get(a[i][3]); memset(f,0x3f,sizeof(f)); int M=(1<<n)-1;f[0]=0; rep(i,1,M)//枚举所有的状态. { int k=0; rep(j,0,n-1) if(i&1<<j) rep(l,1,3) if(!(i&1<<(a[j+1][l]-1))) ++k; rep(j,0,n-1) if(i&1<<j)//枚举最后编号的点. f[i]=min(f[i],f[i&(~(1<<j))]+k); } put(f[M]); return (0^_^0); } //以吾之血,祭吾最后的亡魂
标签:line 相等 span 这一 efi getc 思考 bit namespace
原文地址:https://www.cnblogs.com/gcfer/p/12901802.html
