
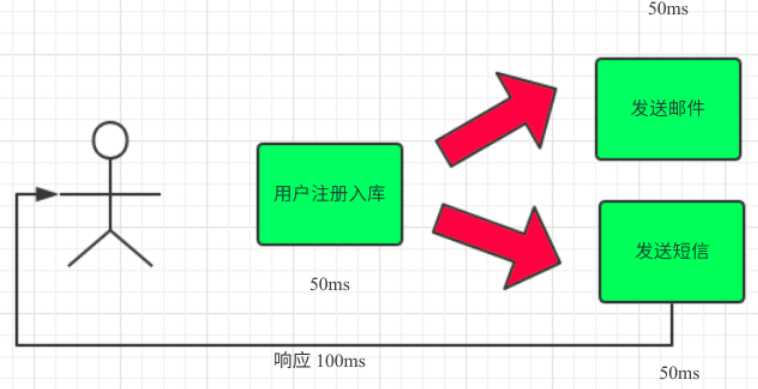
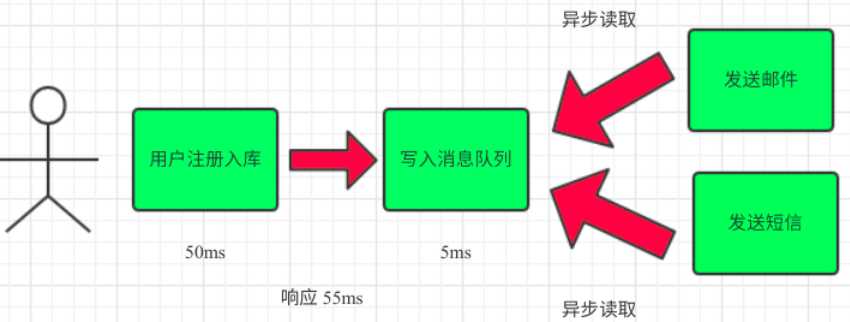

RabbitMQ集群配置
前面配置了RabbitMQ在本地的部署,现在来尝试集群配置
集群的配置比较简单,但是有一个要求就是必须在同一网段内
假设有两台机器,Rabbit0和Rabbit1做集群
首先将2台机器的.erlang.cookie统一,任选一台为标准就可以
sudo vim /var/lib/rabbitmq/.erlang.cookie
修改hosts文件
sudo vim /etc/hosts
加入以下字段
172.16.18.159 Rabbit0 172.16.18.83 Rabbit1
同时自己的机器的主机名务必要给成和你的这个是一样的,不然机器重启后,不是这个主机名,加入到集群会出现问题的.
可以通过修改vim /etc/sysconfig/network中的HOSTNAME选项来修改,同时hostname Rabbit0 也是可以临时修改的.
在Rabbit0上,执行如下命令
sudo rabbitmqctl stop_app sudo rabbitmqctl reset sudo rabbitmqctl join_cluster --ram rabbit@Rabbit1 sudo rabbitmqctl start_app
如果添加成功的话,在每台机器上查看集群状态
sudo rabbitmqctl cluster_status
成功的话两边应该是相同的内容,类似于
Cluster status of node rabbit@Rabbit0 ...
[{nodes,[{disc,[rabbit@Rabbit1]},{ram,[rabbit@Rabbit0]}]},
{running_nodes,[rabbit@Rabbit1,rabbit@Rabbit0]},
{partitions,[]}]
这样配置的结果是,Rabbit0作为内存节点,Rabbit1作为磁盘节点
RabbitMQ集群中必须至少存在一台磁盘节点
不想要内存节点的话,只需要将--ram参数去掉即可
存在多节点的情况,推荐在主节点中,执行
sudo rabbitmqctl stop_app sudo rabbitmqctl reset sudo rabbitmqctl start_app
在其余的节点执行
sudo rabbitmqctl stop_app sudo rabbitmqctl reset sudo rabbitmqctl join_cluster --ram rabbit@RabbitMain sudo rabbitmqctl start_app
这样做的结果是主节点为磁盘节点,其余节点为内存节点
集群同步配置
一个集群只需要一台机器配置,会自动扩散到集群
在集群任意一台web管理页面的Overview信息中均可以看到所有节点的情况
在admin中的Policies可以添加镜像队列规则
例如
Name随便,Pattern填入"^ha" 表示匹配所有ha开头的队列
Definition填入ha-mode,后面填入all
保存在queues里可以看到效果,节点名后面会有一个+1
同效果配置可以用命令来实现
sudo rabbitmqctl set_policy ha-all "^ha\." ‘{"ha-mode":"all"}‘
RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。不过,如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
良好的设计架构可以如下:在一个集群里,有3台以上机器,其中1台使用磁盘模式,其它使用内存模式。其它几台为内存模式的节点,无疑速度更快,因此客户端(consumer、producer)连接访问它们。而磁盘模式的节点,由于磁盘IO相对较慢,因此仅作数据备份使用。
参考文章:
《rabbitmq配置集群和镜像队列》http://www.bbtang.info/linux/fuwu/610.html
《【APP】RabbitMQ集群环境生产实例部署》http://opsmysql.blog.51cto.com/2238445/1030832
《Highly Available Queues》http://www.rabbitmq.com/ha.html