标签:text submit 不能 exec serve ext bit ali 官方
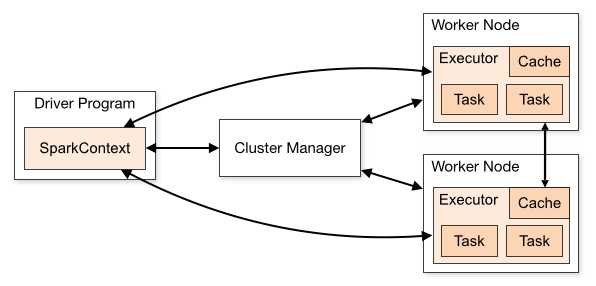
Client 提交 Spark 应用后,会在 Client 所在节点或由 Manager 选择的节点(取决于提交的方式)启动 Driver,在 Driver 需要构建 SparkContext,通过 SparkContext 构建要执行的任务,然后 SparkContext 会向 Manager 申请资源(Executor 个数、内存等),由 Manager 在各个 Worker Node 分配启动 Executor,然后 SparkContext 会计算如何调度任务,并将程序传给 Executor,并调度 Executor 执行
Spark 现在支持几种部署模式
这里只介绍 Spark on Yarn 模式
Hadoop/Yarn 集群已经安装好
https://archive.apache.org/dist/spark/spark-2.2.0/
选择 spark-2.2.0-bin-without-hadoop.tgz
> sudo tar -zxf spark-2.2.0-bin-without-hadoop.tgz -C /usr/local/
> cd /usr/local
> sudo mv ./spark-2.2.0-bin-without-hadoop/ ./spark
> sudo chown -R hadoop:hadoop ./spark
> vi ~/.bashrc ## 添加 PATH=$PATH:/usr/local/spark/bin:/usr/local/spark/sbin
> source ~/.bashrc
Spark 自带 Scala,所以不需要再额外安装
cd /usr/local/spark
sudo cp ./conf/spark-env.sh.template ./conf/spark-env.sh
sudo vi ./conf/spark-env.sh
# 添加下面内容
# export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
# export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
有了上面的配置,Spark 就可以读取 Hadoop 的信息
在所有节点上安装配置 Spark
配置完成后就可以直接使用,不需要像 Hadoop 运行启动命令
pyspark --version
run-example SparkPi
spark-shell ## scala
pyspark ## python
spark-shell 和 pyspark 都是交互界面,其中 spark-shell 用 scala 语言,pyspark 用 python 语言
pyspark
>>> from pyspark.sql import SQLContext
>>> sqlc = SQLContext(sc)
>>> columnName = ["name", "type", "value"]
>>> values = [["n1",1,123],["n2",2,456]]
>>> df = sqlc.createDataFrame(values, columnName)
>>> df.write.parquet("/user/hadoop/test.parquet", mode="overwrite")
>>> sqlc.read.parquet("/user/hadoop/test.parquet").show()
+----+----+-----+
|name|type|value|
+----+----+-----+
| n1| 1| 123|
| n2| 2| 456|
+----+----+-----+
spark-submit
# spark_test.py
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext(appName="Spark_Test")
sqlc = SQLContext(sc)
columnName = ["name", "type", "value"]
values = [["n1",1,123],["n2",2,456]]
df = sqlc.createDataFrame(values, columnName)
df.write.parquet("/user/hadoop/test.parquet", mode="overwrite")
sqlc.read.parquet("/user/hadoop/test.parquet").show()
spark-submit --master local ./spark_test.py
spark-submit --master yarn ./spark_test.py
local 模式不会提交到 Yarn 而是在本地运行
yarn 模式会把程序提交到 Yarn,在 Yarn 的 UI 或 yarn application -list 可以查看程序
Spark 2.0 开始建议用 SparkSession 做入口,SparkSession 封装了 SparkContext 和 SQLContext
# spark_test.py
from pyspark.sql import SparkSession
spark = SparkSession .builder .appName("Python Spark SQL basic example") #.config("spark.some.config.option", "some-value") .getOrCreate()
sc = spark.sparkContext
rdd_1 = sc.parallelize([0, 2, 3, [6, 8], "Test"])
rdd_2 = rdd_1.map(lambda x : x*2)
print rdd_2.collect()
df = spark.read.load("/user/hadoop/test.parquet")
df.createOrReplaceTempView("test")
sqlDF = spark.sql("SELECT * FROM test")
sqlDF.show()
spark-submit 的参数
--master local ## 单机模式,使用 1 个 worker 线程
--master local[K] ## 单机模式,使用 K 个 worker 线程
--master yarn ## 集群模式(基于 yarn)
--master yarn --deploy-mode client ## driver 跑在本机,默认 client
--master yarn --deploy-mode cluster ## driver 跑在集群的任意节点,注意 log 不一定存在本机
--master yarn-client ## 等同于 --master yarn --deploy-mode client
--master yarn-cluster ## 等同于 --master yarn --deploy-mode cluster
--jars JARS ## Comma-separated list of local jars to include on driver/executor classpaths.
--py-files PY_FILES ## Comma-separated list of .zip, .egg, or .py files to place
## on the PYTHONPATH for Python apps.
--files FILES ## 逗号分隔的文件列表,会放到每个 executor 的工作目录
## Spark 使用下面几种 URI 来处理文件的传播:
## file://,由 driver 的 HTTP server 提供文件服务,executor 从 driver 上拉回文件
## hdfs:, http:, https:, ftp:, executor 直接从 URL 拉回文件
## local:, executor 本地本身存在的文件,不需要拉回
## --files 是放到 local:
--driver-cores NUM ## Number of cores used by the driver, only in cluster mode (Default: 1)
--driver-memory MEM ## Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options ## Extra Java options to pass to the driver.
--driver-library-path ## Extra library path entries to pass to the driver.
--driver-class-path ## Extra class path entries to pass to the driver.
## Note:jars added with --jars are automatically included in the classpath.
## 所以 --jars 有的就不用写到 --dirver-class-path 了
--executor-memory MEM ## Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--executor-cores NUM ## Number of cores per executor.
## (Default: 1 in YARN, or all available cores on the worker in standalone)
--num-executors NUM ## Number of executors to launch, only in YARN mode (Default: 2)
--queue QUEUE_NAME ## The YARN queue to submit to (Default: "default").
--conf PROP=VALUE ## Arbitrary Spark configuration property.
--properties-file FILE ## Path to a file from which to load extra properties.
## If not specified, this will look for conf/spark-defaults.conf
--class CLASS_NAME ## Your application‘s main class (for Java / Scala apps)
只用过基于 Yarn 的,不清楚其他模式是否有所不同
RDD(Resilient Distributed Dataset,弹性分布式数据集)
DataFrame
DataSet
Spark 2 大体上是兼容 Spark 1.6 的,主要的改变有
Programming APIs
type DataFrame = Dataset[Row]SQL
New Features
Performance and Runtime
MLlib New features
Streaming
标签:text submit 不能 exec serve ext bit ali 官方
原文地址:https://www.cnblogs.com/moonlight-lin/p/12934736.html