JML语言是对一个方法、类、程序的外部可感知行为进行抽象表示的规格化语言,它具有两个重要的特征。第一点:JML语言是抽象的。它就如同一个方法、类、程序的说明书,它告诉你这个用这方法需要什么条件,使用了这个方法之后满足什么效果。但这样的效果任何实现,JML语言不进行描述,因为对于使用者来说,他们只需要知道如何使用即可,没必要知道内部实现;对于实现者来说,每个具体的实现方式各有优劣,JML语言也没有能力对具体实现进行描述。但JML语言与现实中的说明书还是有所差别的,这就是第二点:JML语言是形式化的。这主要是因为现实中的自然语言有歧义性和模糊性,就算使用地再小心,两个人之间也可能产生不一样的理解。但是JML语言利用逻辑化的描述,将所需要表达的内容精确化,让一万个人心中也只有一个哈姆雷特。
正是上述两个特点,让JML规格化语言有了出现的意义。比如在现实的工作中,我们很有可能要查看同事写的或是前辈留下的代码。我们当然可以直接通过查看代码的具体实现得到代码内在的逻辑,但如果这些代码的实现有一份规格,我们就可以越过代码的具体实现,直接通过规格了解代码的需求和功能,相对于直接看代码要省力许多,这利用了JML语言的抽象的特点。又比如在公司中,我们需要进行团队协作,每个人负责一部分代码实现。如果使用自然语言描述,很有可能出现团队中有人对功能的理解产生歧义,使得未来整合代码的时候出现问题,而是用规格化的语言就能够避免理解的偏差,这利用了JML语言形式化的特点。
JML语言的理论基础
在我们的实验和作业中,我们所学习和使用的是JML最核心的语言特征,属于level 0级别。在此之上可能还有许多更加高级的用法,但是最核心的用法已经能够表达大部分语义和细节。
1、JML书写形式:
首先是JML语言的书写形式。JML语言借用了当时已经成型的一款能够自动生成API文档的工具javadoc的书写形式,采用注释,并且在每行注释前加@符号的方式书写JML语言。
/*@ also @ public normal_behavior @ requires obj != null && obj instanceof Group; @ assignable \nothing; @ ensures \result == (((Group) obj).getId() == id); @ also @ public normal_behavior @ requires obj == null || !(obj instanceof Group); @ assignable \nothing; @ ensures \result == false; @*/ public /*@pure@*/ boolean equals(Object obj); //@ ensures \result.equals(name); public /*@pure@*/ String getName();
2、方法规格:
方法规格对一个方法的功能进行抽象的描述,具体分为三部分:
- 前置条件(pre-condition):前置条件通过requires子句来表示,如 @ requires P; ,其中P的逻辑表达式需要为真,表示调用者在使用该方法时应当满足的前置条件。前置条件可以有多个并列出现,表示在调用时这些需求都应当满足。
- 后置条件(post-condition):前置条件通过ensure子句来表示,如@ ensure P; ,其中P的逻辑表达式需要为真,表示调用者在使用该方法后能够实现的功能效果。前置条件相同,后置条件也可以有多个并列出现,表示在调用完成后这些功能效果都应当实现。
- 副作用(effects):副作用通过assignable子句来表示,如@ assignable x; ,其中x是在JML规格中定义的一个变量,表示调用者在调用的前后,这些变量的值可能发生变化。
但有的时候,调用者可能输入不满足我们设计需求的数据,我们还需要对不满足需求的输入抛出异常。为了使抛出异常这一行为也能够在JML规格中有所体现,JML语法又将方法规格分为两种:
- 正常行为(normal_behavior):对于所有满足需求设计的输入,我们用正常行为的块对他进行描述。块中可以包含前置条件、后置条件和副作用来表达对于这种输入,我们应当完成相应的功能。一个方法可以包含多个正常行为的块,用also进行连接。需要注意的是,多个并列的块的前置条件不能有重合,否则会产生逻辑矛盾。
- 异常行为(exceptional_behavior):对于所有不满足需求设计并需要抛出异常的输入,我们用异常行为的块对它进行描述。异常行为块中的其他表达形式与正常行为块相同,但是异常行为块中不再使用ensure 作为后置条件,而是采用@ signals (Exception e) P; 的形式表达在这种输入下需要抛出的异常,其中P的逻辑表达式需要为真,表示要抛出异常e需要满足的条件。多个异常行为块用also连接,但异常行为块的前置条件不能有重叠。
下面是一个较为完成的方法规格:
/*@ public normal_behavior @ requires (\exists int i; 0 <= i && i < groups.length; groups[i].getId() == id); @ ensures \result == getGroup(id).people.length; @ also @ public exceptional_behavior @ signals (GroupIdNotFoundException e) !(\exists int i; 0 <= i && i < groups.length; @ groups[i].getId() == id); @*/ public /*@pure@*/ int queryGroupPeopleSum(int id) throws GroupIdNotFoundException;
3、类规格:
与其称之为类规格,不如叫做类的数据规格更贴切些。类规格则是对某个具体类中的数据类型设计限制规则,具体分为两种类型:
- 不变式(invariant):即在这个类的数据的静态的规定。除了在数据变化的过程中,其他一切情况下,所有的数据都应当满足不变式中所规定的数据条件。
- 状态变化约束(constraint):即在这个类的数据的变化的规定。在不变式中,我们已经定义了除了变化过程中的数据应当满足的条件,而在变化的时候,则应当满足状态变化约束所规定的条件,应当用约束中所规定的变化方式进行数据的改变和添加。
下面是一个较为完整的类规格:
//@ public instance model non_null Object[] elementData; /*@ invariant (\forall int i; 0 <= i && 2 * i + 1 < elementData.length; elementData[i].compareTo(elementData[2 * i + 1]) < 0) @ && (\forall int i; 0 <= i && 2 * i + 2 < elementData.length; elementData[i].compareTo(elementData[2 * i + 2]) < 0) @ && (\forall int i; 0 < i && 2 * i + 2 < elementData.length; elementData[2 * i + 1].compareTo(elementData[2 * i + 2]) < 0); @*/
4、常用原子表达式:
- \result表达式:表示这个方法对应的返回值。
- \old( expr )表达式:表示expr表达式在方法执行前的值。特别需要注意的是, \old(people).length 和 \old(people.length) 是完全不一样的,一般使用\old的时候都会将整个表达式放置在括号中来避免错误。
- \not_assigned(x,y,...):表示括号内的变量在该方法中没有被赋值。
5、常用量化表达式:
- \forall表达式:相当于离散数学中的对于任意的。用 (\forall x;P;Q); 来表示,x为所涉及的变量,P为变量需要满足的条件,Q为满足条件时需要满足的结果。
- \exists表达式:相当于离散数学中的存在。用 (\exists x;P;Q); 来表示,x为所涉及的变量,P为变量需要满足的条件,Q为满足条件时需要满足的结果。
- \sum表达式:相当于累加。用 (\sum x;P;y); 来表示,x为涉及的变量,P为变量需要满足的条件,y为满足条件时累加的数字。
- \max,\min表达式:相当于求最大最小值。用 (\max x;P;y); 和 (\min x;P;y); 来表示,x为涉及的变量,P为变量需要满足的条件,y为满足条件时参与大小比较的数字。
JML应用工具链
JML的工具链似乎不多:
-
OpenJml,用来检查JML规格合法性。
- SMT Solver,用来判断JML规格与具体代码实现是否符合。
- JML UnitNG,用来根据JML规格自动构造数据。
二、JML应用工具链的使用
在这里还是得谢谢几位整理并分享这些工具如何使用的同学,看了他们写的教程确实节省了不少时间。
但由于JML应用工具链似乎并不是特别完善,对于一些语法以及变量名的限制较多,因此我将原本作业中的代码进行了简化和修改,去除了一些类型重复的代码,并简化了一些代码的实现。最终使用的代码如下:
package test; import java.math.BigInteger; public class MyPerson{ /*@ public instance model non_null int id1; @ public instance model non_null String name1; @ public instance model non_null BigInteger character1; @ public instance model non_null int age1; @ public instance model non_null MyPerson[] acquaintance1; @*/ public int id2; public String name2; public BigInteger character2; public int age2; public MyPerson[] acquaintance2=new MyPerson[10000]; public MyPerson(int id3, String name3, BigInteger character3, int age3) { this.id2 = id3; this.name2 = name3; this.character2 = character3; this.age2 = age3; } //@ ensures \result == id1; public /*@pure@*/ int getId2() { return id2; } //@ ensures \result.equals(name1); public /*@pure@*/ String getName2() { return name2; } //@ ensures \result.equals(character1); public /*@pure@*/ BigInteger getCharacter2() { return character2; } //@ ensures \result == age1; public /*@pure@*/ int getAge2() { return age2; } /*@ also @ public normal_behavior @ requires obj != null && obj instanceof MyPerson; @ assignable \nothing; @ ensures \result == (((MyPerson) obj).getId2() == id1); @ also @ public normal_behavior @ requires obj == null || !(obj instanceof MyPerson); @ assignable \nothing; @ ensures \result == false; @*/ public /*@pure@*/ boolean equals(Object obj) { if (obj != null && obj instanceof MyPerson) { return (((MyPerson) obj).getId2() == id2); } else { return false; } } /*@ public normal_behavior @ assignable \nothing; @ ensures \result == (\exists int i; 0 <= i && i < acquaintance1.length; @ acquaintance1[i].getId2() == person.getId2()) || person.getId2() == id1; @*/ public /*@pure@*/ boolean isLinked(MyPerson person) { if (person.getId2() == this.id2) { return true; } for (int i=0;i<10000;i++) { if (acquaintance2[i].getId2() == person.getId2()) { return true; } } return false; } //@ ensures \result == acquaintance1.length; public /*@pure@*/ int getAcquaintanceSum() { return acquaintance2.length; } /*@ also @ public normal_behavior @ ensures \result == name1.compareTo(p2.getName2()); @*/ public /*@pure@*/ int compareTo(MyPerson p2) { return name2.compareTo(p2.getName2()); } }
package test; public class MyGroup{ public int id; public MyPerson[] people=new MyPerson[10000]; public MyGroup(int id) { this.id = id; } //@ ensures \result == id; public /*@pure@*/ int getId() { return id; } /*@ also @ public normal_behavior @ requires obj != null && obj instanceof MyGroup; @ assignable \nothing; @ ensures \result == (((MyGroup) obj).getId() == id); @ also @ public normal_behavior @ requires obj == null || !(obj instanceof MyGroup); @ assignable \nothing; @ ensures \result == false; @*/ public /*@pure@*/ boolean equals(Object obj) { if (obj != null && obj instanceof MyGroup) { return (((MyGroup) obj).getId() == id); } else { return false; } } //@ ensures \result == (\exists int i; 0 <= i && i < people.length; people[i].equals(person)); public /*@pure@*/ boolean hasPerson(MyPerson person) { for (int i=0;i<10000;i++) { if (people[i].getId2() == person.getId2()) { return true; } } return false; } /*@ ensures \result == ( @ ((\sum int i; 0 <= i && i < people.length && people.length != 0; people[i].getAge2()) / people.length)); @ ensures people.length==0 ==> \result==0; @*/ public /*@pure@*/ int getAgeMean() { int tmp=0; if (people.length==0){ return 0; } for (int i=0;i<people.length;i++){ tmp+=people[i].getAge2(); } return tmp/people.length; } /*@ ensures \result == (((\sum int i; 0 <= i && i < people.length && people.length != 0; @ (people[i].getAge2() - getAgeMean()) * (people[i].getAge2() - getAgeMean())) / @ people.length)); @ ensures people.length==0 ==> \result==0; @*/ public /*@pure@*/ int getAgeVar() { int tmp=0; if (people.length==0){ return 0; } for (int i=0;i<10000;i++){ tmp+=(people[i].getAge2() - getAgeMean()) * (people[i].getAge2() - getAgeMean()); } return tmp/people.length; } }
SMT Solver
SMT Solvers是一款检测JML规格和对应的代码是否符合的工具。这个工具目前的完成度并不高,对于java中容器的支持存在问题,对于JML中的一部分语法也不支持,而且最关键的是JML规格中的变量名定义不能和代码中的变量名相同,因此需要对作业中的代码进行较大程度的修改才能利用这款工具进行验证。在处理了大量的错误之后,我将原来的代码修改成上述的简单版本,然后对这部分代码进行验证。使用工具时在cmd中输入下面的代码就可以运行:
java -jar E:\oo_jmltest\openjml.jar -exec E:\oo_jmltest\Solvers\z3-4.7.1.exe -esc E:\oo_jmltest\*.java
运行的结果如下:
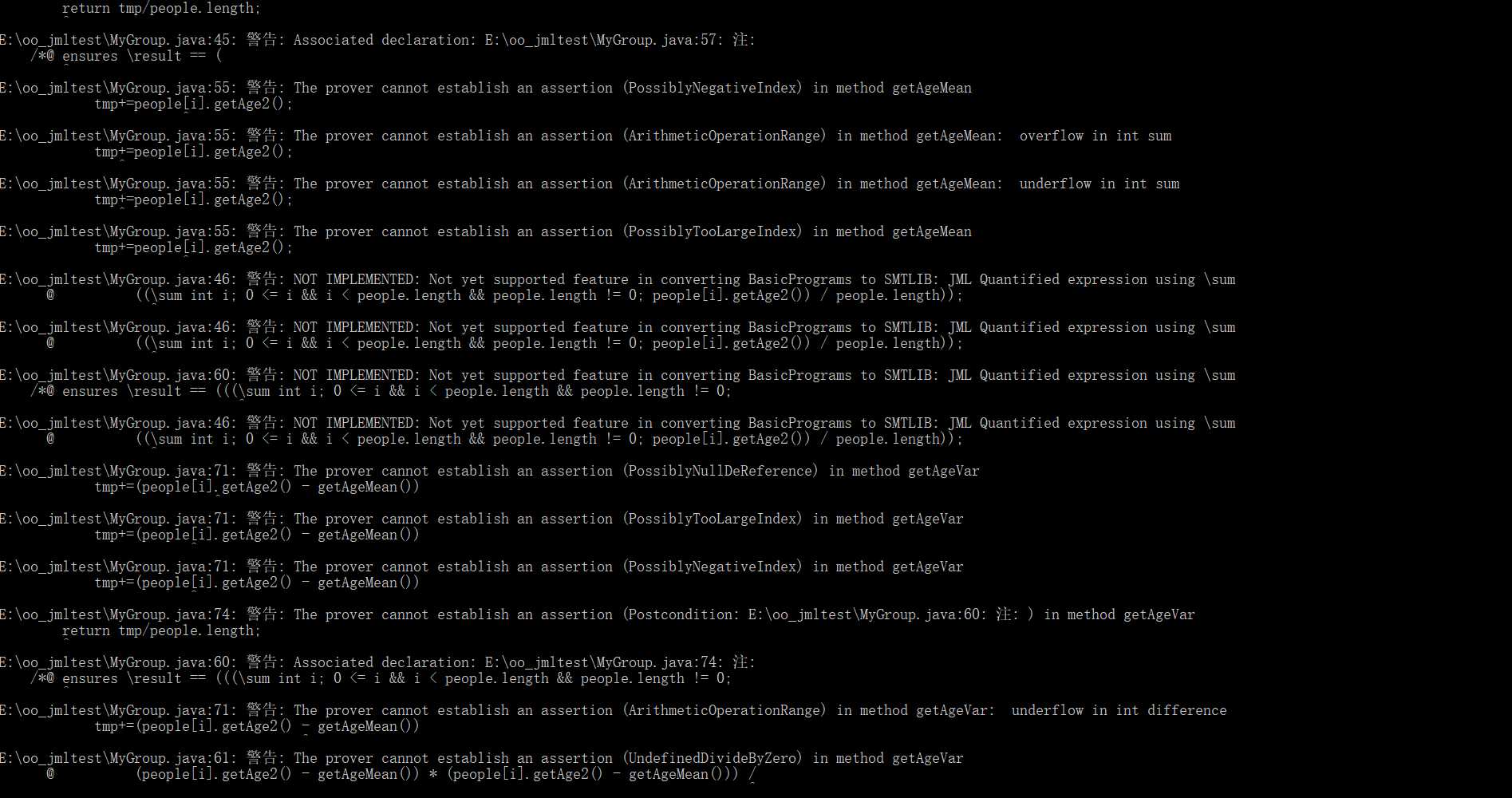
在消除了大量报告的错误之后,运行的结果出现了大量的警告。从警告中可以看到,这里大量的代码似乎都无法建立相应的相应的验证机制,还有少部分的代码因为JML规格中使用了工具不支持的语法\sum导致无法识别。这还是经过精简后的代码版本,若是希望验证作业中的代码和JML规格,可能需要将代码进行整体的调整。因此没有再对自己的代码和这个工具进行进一步的调整和研究。
JMLUnitNG
JMLUnitNG是一款根据JML规格自动创建测试用例的工具。相比于上面那款工具,JMLUnitNG的体验稍好一些,至少运行完毕后等待你的不是一大串警告,而是确实提供了一部分数据并进行验证。使用这款工具的时候在cmd中按顺序输入下面四条代码就能够运行:
java -jar E:\oo_jmltest\jmlunitng.jar E:\oo_jmltest\test\MyGroup.java javac -cp E:\oo_jmltest\jmlunitng.jar E:\oo_jmltest\test\*.java java -jar E:\oo_jmltest\jmlunitng.jar -rac E:\oo_jmltest\test\MyGroup.java E:\oo_jmltest\test\MyPerson.java java -cp E:\oo_jmltest\jmlunitng.jar test.MyGroup_JML_Test
指令输入完成后会在目标文件夹生成大量JAVA文件和CLASS文件:
运行的结果如下:
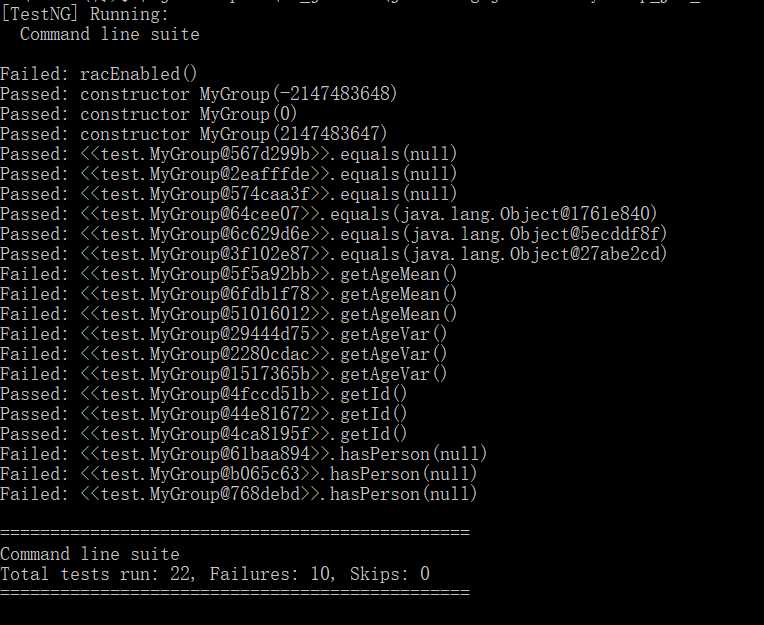
可以看到,这款工具确实对我们的代码构造了数据并进行反馈,但仔细观察我们可以发现一些规律:对于数字参数的方法,测试数据为[+-]maxint和0;对于输入某个对象的方法,会测试null和一个随机对象;对于没有参数的函数,从getId方法能够通过测试可以看出,JMLUnitNG是可以根据JML规格来对代码进行验证的,但是具体的验证方式到底是逻辑证明还是数据代入就不清楚了。
总的来说,这款验证工具会对代码进行边界数据以及null等常规的易错数据进行测试,也会对没有参数输入的方法进行JML规格和代码的简单验证。这固然挺好,但是我更希望能够有一款更加强大的工具,能够根据JML规格描述有针对性地构建专门的测试用例进行测试。目前看来,JMLUnitNG的功能显得有些鸡肋,与其将代码修改成JMLUnitNG可以接受的形式再用这款工具进行验证,还不如自己写一个JUnit单元测试来得方便一些。
当然,也有可能是因为我简化的代码中存在一些问题,导致工具无法根据JML规格构建其他测试用例。
三、架构设计
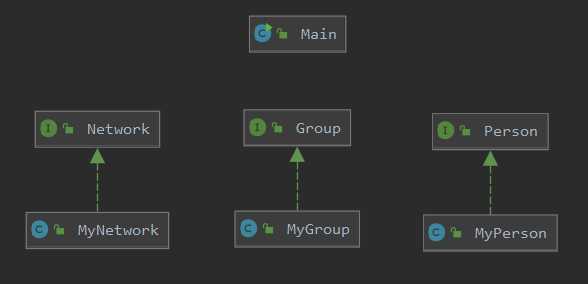
说实话,在这一单元,我丝毫没有考虑过架构设计这一件事。三次作业代码的架构设计用一句话就能够概括:分别创建自己的类实现发放的三个接口文件,然后写一个main函数调用Runner方法。用下面一张图可以更清晰的表示。
但当我对第三次作业进行checkstyle的时候,超过500行的Network类让我明白了这次作业的架构肯定出了问题,Network类经过几次作业的功能累加已经成为了“上帝类”,但作业提交ddl在即,已经来不及修改,就先以通过测试为主了。现在是单元总结的时候,面对之前三次作业无脑对着JML进行实现的代码,我觉得没有分析它们架构的必要。下面是我对如何更加优雅地实现这几次作业的代码架构设计的思考。
首先我们可以明确几点:1、Person类和Group类没必要讨论架构,因为这两个类本身就是存放数据和进行基础操作的属性类,需要进行架构设计的是Network类。2、由于Network接口的存在,我们必须要完整地实现这个接口才能满足语法要求,因此无法像前几个单元一样,简单地按照功能把Network类进行拆分来达到简化Network类的目的。因此我在这里给出两种架构的方式,虽然不一定是最优雅、最精妙的,但能够有效地解决Network类中功能过于复杂的问题。
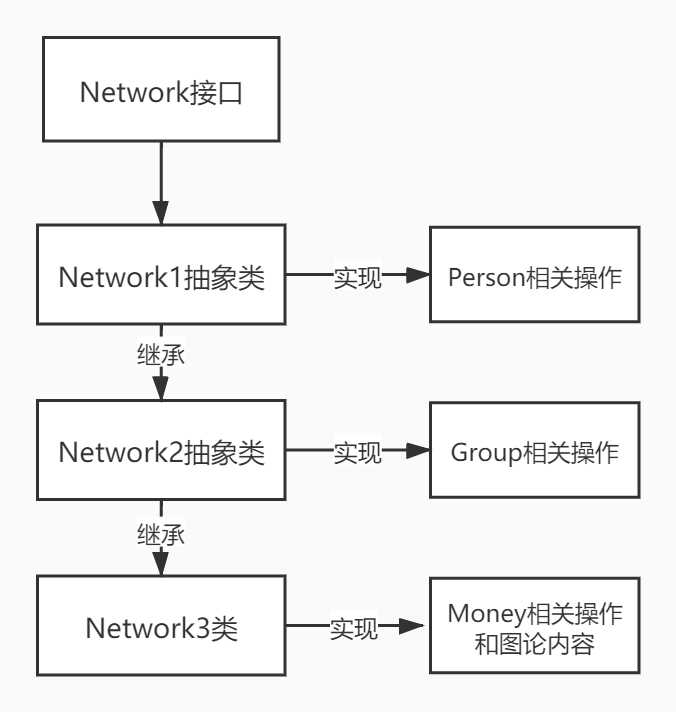
第一种方式是按照几次作业的顺序,令这一次的作业中的Network类继承上一次作业的Network,并将上一次作业的Network类改为抽象类,使得每次作业都只需要在一个新的Network类中实现本次作业新增的那部分功能,而不是在原来的Network类下方继续添加新的方法。这样一来就能够按照作业布置的次序将Network类中的代码以实现时间的不同进行了分离,从而有效地减少单个类中实现功能的数量和代码量。能够利用这种方式进行功能分离的原因在于,每次新作业很少修改原来已经完成的功能,主要以添加新的功能和方法为主,因此以时间顺序对代码进行划分是符合现实逻辑并且比较容易实现的,并且还挺符合架构设计中的OCP(开放封闭原则)的,架构如下图所示。
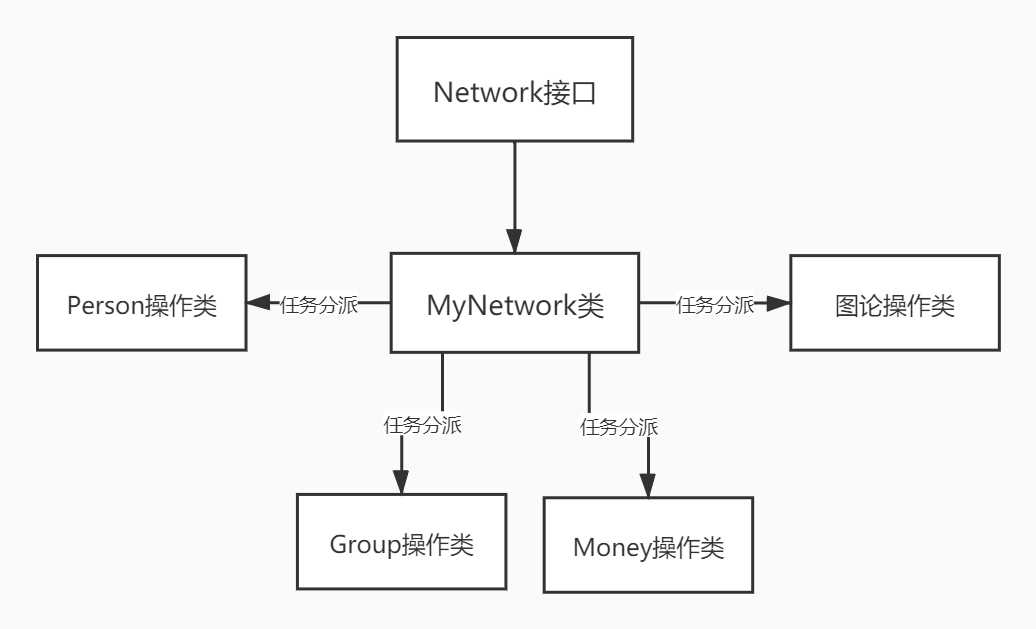
第二种方式则是做一个间接的功能分类,把Network类从大量公共的实现者变成工作的分发者,类似上个单元中的调度器类。我们先将Network类中的功能进行分类,比如图论的功能实现、Person操作实现、Group操作实现等等,然后分别在不同的类中实现这些功能。Network类最后要做的,就是识别需要实现何种功能,然后将参数发送给对应的类中进行处理,最后再将处理完得到的返回值或是异常返回出去。一旦不涉及具体实现,那么Network类中的代码量将大大减少。
四、Bug分析
自己的Bug
这三次作业中bug出现的较多,这主要是由于无脑照着JML规格硬写代码以及对一些简单的算法生疏导致的。
第一次作业:第一次作业中对JML规格不大熟悉,再加上同学“这次作业贼简单”的话语影响,实现的代码几乎全部都是对JML规格的生搬硬套,isCircle方法完全没去理解,就直接把规格中的数组复制到代码中了。结果第一次作业中最重要的isCircle函数被我写成了毫无意义、没有任何功能的一串代码。由于中测时没有对isCircle方法进行测试,我也偷懒没对代码进行单元测试,甚至连普通的黑箱测试都没做,结果强测成功爆零。第一次作业的巨大失败也给我敲响了警钟,首先是JML代码本身和实现无关,是对代码功能抽象的表示,不加理解与思考,对着规格硬写代码必然会出问题。第二点是自我测试真的非常重要,依靠中测帮忙发现bug的行为是绝对不可取的。
第二次作业:第二次作业吸取了第一次作业的教训,仔细分析了所有的规格和实现,避免对功能的错误理解。由于我在第二次功能实现中还使用了在线更新的方式实现查询,因此还特地敲了对拍程序进行验证。最终这次作业没有出现bug,在时间限制上也比较宽裕。
第三次作业:第三次作业又出现了问题。由于实在太久没有写深搜了,因此在实现两个点之间是否连通的深搜时,错误地写成了寻找两点之间所有通路的深搜,使得复杂度从O(n)变为O(n!),然后不出意外的超时了。其他部分的功能实现由于在课下都进行了单元测试以及黑箱测试,正确性都能够达到保障。
别人的Bug
这三次作业中,发现的他人的bug主要出现在超时上。第二次作业中,对于一些Group属性的询问,有的同学没有采用在线更新的策略,而是采用每次询问都遍历一遍数组,并重新计算所需要的值。这样的方式在极限数据的情况下会导致超时。第三次作业时,最短路算法有的同学没有使用堆对迪杰斯特拉算法进行优化,还有的同学在连通块的求解上采用了一些奇怪的土方法导致超时。还有极少部分同学改变了原有的架构,希望用自己的方式实现一些功能,结果在特殊情况的处理细节上出现了差错,不符合JML规格规定的返回值,结果导致出现bug。
五、心得体会
这个单元我们主要学习了JML规格化语言,了解了面向对象语言不仅利用了类和接口建立了结构抽象和行为抽象,还能够根据JML建立的方法规格的抽象。我认为JML语言的想法非常好,每一个编程人员在编写代码的时候,内心肯定都有一个面对正在实现的代码的规格抽象。但如果不将这隐藏在大脑中的抽象规格表达出来,自己在实现的时候就有可能会因为一时大意而出现自身难以检查的错误,将代码交给别人时也不方便他人对自己写的代码的理解。但如果使用现有的自然语言对抽象规格进行描述,又有可能出现歧义和模糊的状况,因此发明了JML语言这种形式化的方式,将内心的代码规格抽象精确地表达出来。
但JML规格化语言目前的问题也非常大。首先是工具链的严重不足。从前文对JML工具链的体验可以看出,目前JML相关工具链的完成度和鲁棒性都不够好。一旦工具出现了问题,JML的缺陷就暴露出来了:尽管人们拥有逻辑思考的能力,但正常生活中主要的表达方式还是自然语言,当需要使用逻辑严密的形式化语言的时候,往往会有缺漏。一旦失去工具链的支持,人凭借自身很难写出严密的逻辑表达。再加上形式化的表达本身的一个特点,就在于它会将自然语言中默认和隐藏的逻辑内容表达出来,这提升了语句的准确性,也加大了语句的复杂性。“如果容器中没有这个元素,就添加元素,否则抛出异常”,一句简单的话用JML语言实现起来,可能需要20行。上述的种种原因,也使得JML语言在很多表达歧义性和模糊性没这么严重的情境下,使用起来的方便程度还不如自然语言。我认为这可能是很多同学对JML语言发出抱怨的原因。
但是在这个单元中,我依旧有很多收获。首先是JML语言的思想还是很有潜力的,使用一种绝对精准的描述方法,让所有人明白我们的目标和需求是什么,在未来更多人的协作、更大团队的合作中可能会成为必要。而这种方法广泛推广的关键,就在于一个好用、完整的工具链,使得人们将自然语言转化为形式化语言的时候,能够有一个平稳、舒服的过渡和转化过程。
另外,在这个单元中,我从第一次作业的爆零中有一次体会到了测试和测试数据积累的重要性。在这个单元中,我了解了单元测试,并学会了Junit单元测试的使用。根据我的体会,我觉得Junit单元测试比较适合对一些计算类的、功能型的方法进行测试,相比于黑箱测试,单元测试更加精准,能够隔离开其他方法对测试方法的影响,一个一个验证每一个方法的正确性,达到逐一击破的目的。当然,如果没有测试数据,那么一切单元测试都是白谈。因此平时作业中,如果发现了容易错误的点,或者题目中特地标明的边界点,都应当根据他们构造一些简单的数据进行积累,到时候进行单元测试的时候,就能够用这些比较有代表性的数据进行有效的单元测试。