标签:mpi vat RoCE 发布 mic idt 速度 info exp
昨天写的因为没有及时发布,又丢失了,现在重写一遍重点。
1. activation functions

1) 总结:一般都用ReLu,因为在x>0时,不会出现梯度消失
可以尝试Leakly ReLu ELU Maxout(参数加倍) tanh(0-centered)
不要用Sigmoid
2)Sigmoid: 3个缺点
1 当x太大或者太小时,函数切线斜率接近于0,在ChainRule,梯度传递时会出现梯度消失。
2 不是0-centered,会导致Loss收敛速度慢,特别是sigmoid输出值都是正数 [ 0,1 ],导致input总是 all postive or all negative,在梯度选择时候不会选择下图的蓝线,而是红线。(这点不是很懂)
3 exp() 函数 比较 compitational-expensive

3)tanh: 1pos 1neg
1 梯度消失
2 0-centered
4) ReLu 4pos 2neg
1 x>0时不会出现梯度消失
2 f(x) = max(0,x) computationally efficient
3 比 sigmoid tanh 收敛快6倍
4. 比sigmoid 更符合生物学原理
1 x<0时 梯度消失
2 不是0-centered
5) Leaky ReLu / PReLu /ELU / MAXOUT
在 x<0时 不会梯度消失
2. Data Preprocessing
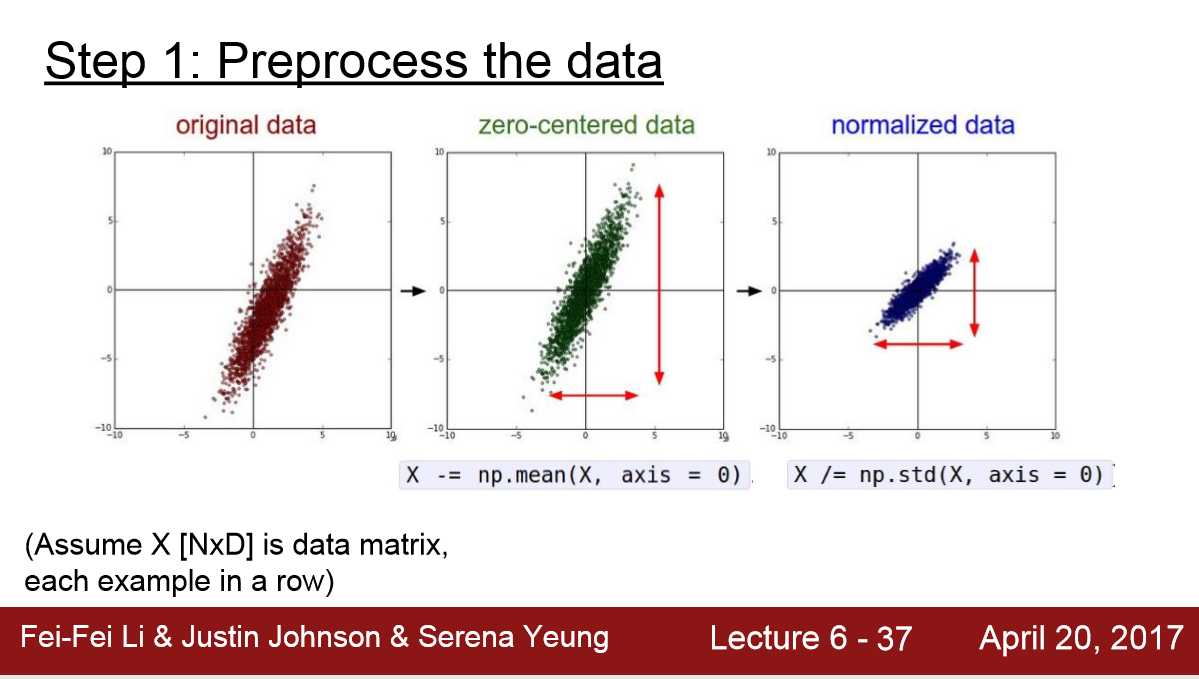
1) 一般只做 0-centered 不做 Normalization。
因为对于image的像素点来说 取值都属于[ 0,255 ]
2) 可以按整张图来做平均,也可以按RGB三通道来做平均,但是平均值是所有输入的像素平均

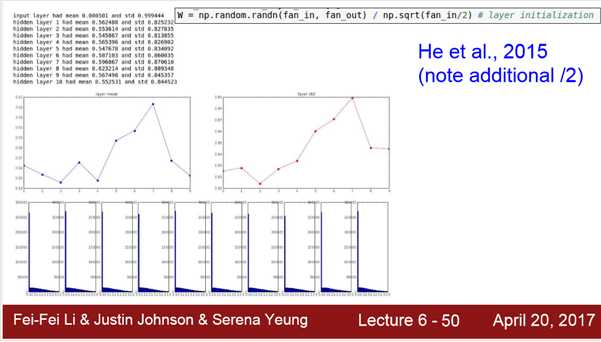
3.Weight Initialization
numpy.random.randn()可以生成高斯分布的数
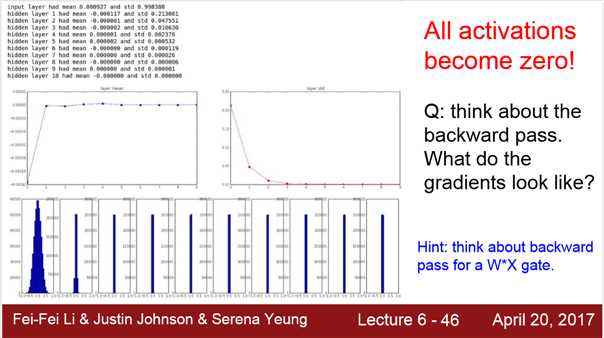
1)W = 0.01*np.random.randn(D,H)
1. 对 small networks可以, 对于deeper networks不太行
2)W = 1.0*np.random.randn(D,H)
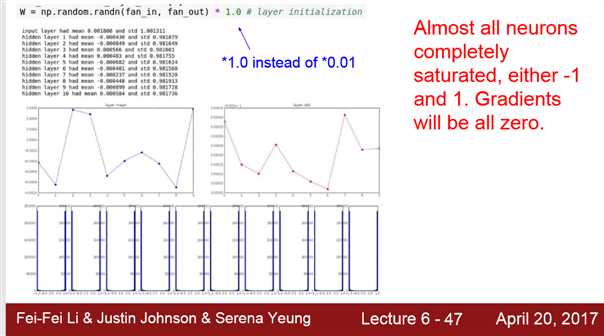
3) 需要 ‘/2’ 是因为ReLu在x<0初饱和,出现梯度消失
标签:mpi vat RoCE 发布 mic idt 速度 info exp
原文地址:https://www.cnblogs.com/ChevisZhang/p/12942656.html