标签:提高 价值 map rom 算法 大量数据 image 输入 networkx
? JML是用于对Java程序进行规格化设计的一种表示语言。使用JML,能够描述一个方法预期的功能而不管如何实现,先设计类和接口,推迟了过程性的思考。JML以javadoc注释的方式来表示规格,有两种注释方式,行注释和块注释。其中行注释的表示方式为//@annotation,块注释的方式为/* @ annotation @*/。
? 包括原子表达式、量化表达式、集合表达式、操作符等。
expr):表达式expr在相应方法执行前的取值。前置条件(pre-condition)
? 通过requires子句来表示,要求调用者确保表达式为真。
后置条件(post-condition)
? 通过ensures子句来表示,要求方法实现者确保返回结果满足表达式。
副作用范围限定(side-effects)
? 关键词assignable或者modifiable,assignble表示可赋值,modifiable则表示可修改。
抛出异常
? 通常用signals子句来表示,表示满足条件时抛出相应异常。
不变式invariant
? 要求在所有可见状态都满足该约束。
状态变化约束constraint
? 要求在变化前后满足该约束。
? 工具主要有openJML和JMLUnitNg。
? 对JML注释的程序进行检查,验证Java程序,支持静态检查和运行时检查。
? JMLUnitNG是JMLUnit的进阶版,可以基于JML规格自动生成测试样例。但实际上生成的测试样例都是一些极端的数据。
? http://insttech.secretninjaformalmethods.org/software/jmlunitng/
? 在对Person接口的实现类进行了一些修改之后测试。
? 修改后代码如下:
package test;
import java.math.BigInteger;
import java.util.ArrayList;
public class Person {
/*@ public instance model non_null int id;
@ public instance model non_null String name;
@ public instance model non_null BigInteger character;
@ public instance model non_null int age;
@ public instance model non_null Person[] acquaintance;
@ public instance model non_null int[] value;
@*/
private int myId;
private String myName;
private BigInteger myCharacter;
private int myAge;
public ArrayList<Person> myAcquaintance;
public ArrayList<Integer> myValue;
public Person(int myId, String myName, BigInteger myCharacter, int myAge) {
this.myId = myId;
this.myName = myName;
this.myCharacter = myCharacter;
this.myAge = myAge;
myAcquaintance = new ArrayList<Person>();
myValue = new ArrayList<Integer>();
}
/* @ public normal_behavior
@ ensures \result == id;
@ */
public /*@ pure @*/ int getId() {
return myId;
}
/* @ public normal_behavior
@ ensures \result.equals(name);
@ */
public /*@ pure @*/ String getName() {
return myName;
}
/* @ public normal_behavior
@ ensures \result.equals(character);
@ */
public /*@ pure @*/ BigInteger getCharacter() {
return myCharacter;
}
/* @ public normal_behavior
@ ensures \result == age;
@ */
public /*@ pure @*/ int getAge() {
return myAge;
}
/*@ also
@ public normal_behavior
@ requires obj != null && obj instanceof Person;
@ assignable \nothing;
@ ensures \result == (((Person) obj).getId() == id);
@ also
@ public normal_behavior
@ requires obj == null || !(obj instanceof Person);
@ assignable \nothing;
@ ensures \result == false;
@*/
public /*@ pure @*/ boolean equals(Object obj) {
if ((obj != null) && (obj instanceof Person)) {
return (((Person) obj).getId() == myId);
} else {
return false;
}
}
/*@ public normal_behavior
@ assignable \nothing;
@ ensures \result == (\exists int i; 0 <= i && i < acquaintance.length;
@ acquaintance[i].getId() == person.getId()) || person.getId() == id;
@*/
public /*@ pure @*/ boolean isLinked(Person person) {
if (person.getId() == myId) {
return true;
}
for (int i = 0; i < myAcquaintance.size(); i++) {
if (myAcquaintance.get(i).getId() == person.getId()
|| person.getId() == myId) {
return true;
}
}
return false;
}
/*@ public normal_behavior
@ requires (\exists int i; 0 <= i && i < acquaintance.length;
@ acquaintance[i].getId() == person.getId());
@ assignable \nothing;
@ ensures (\exists int i; 0 <= i && i < acquaintance.length;
@ acquaintance[i].getId() == person.getId() && \result == value[i]);
@ also
@ public normal_behavior
@ requires (\forall int i; 0 <= i && i < acquaintance.length;
@ acquaintance[i].getId() != person.getId());
@ ensures \result == 0;
@*/
public /*@ pure @*/ int queryValue(Person person) {
for (int i = 0; i < myAcquaintance.size(); i++) {
if (myAcquaintance.get(i).getId() == person.getId()) {
return myValue.get(i);
}
}
return 0;
}
/* @ public normal_behavior
@ ensures \result == acquaintance.length;
@ */
public /*@ pure @*/ int getAcquaintanceSum() {
return myAcquaintance.size();
}
/*@ also
@ public normal_behavior
@ ensures \result == name.compareTo(p2.getName());
@*/
public /*@ pure @*/ int compareTo(Person p2) {
return myName.compareTo(p2.getName());
}
}
结果也从最开始,有许多错误:
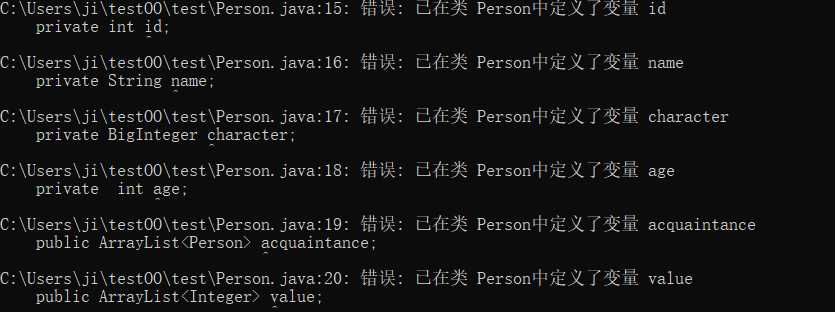
到没有错误但有很多警告:
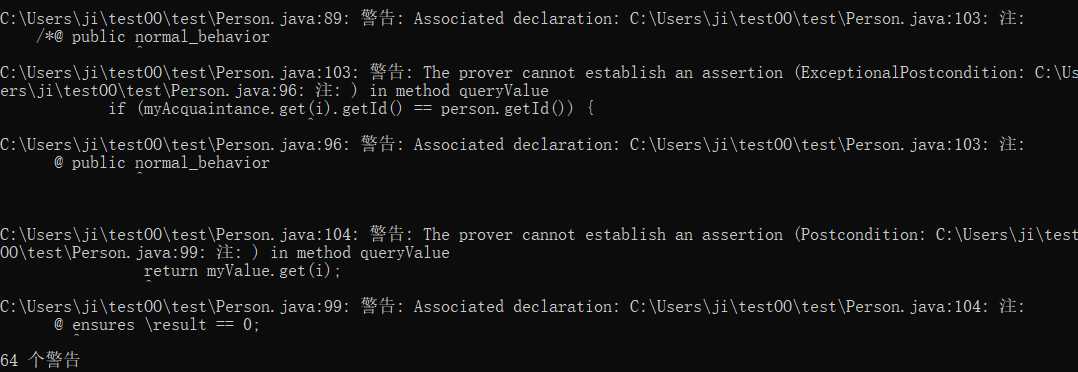
逐步修改到警告相对来说较少:
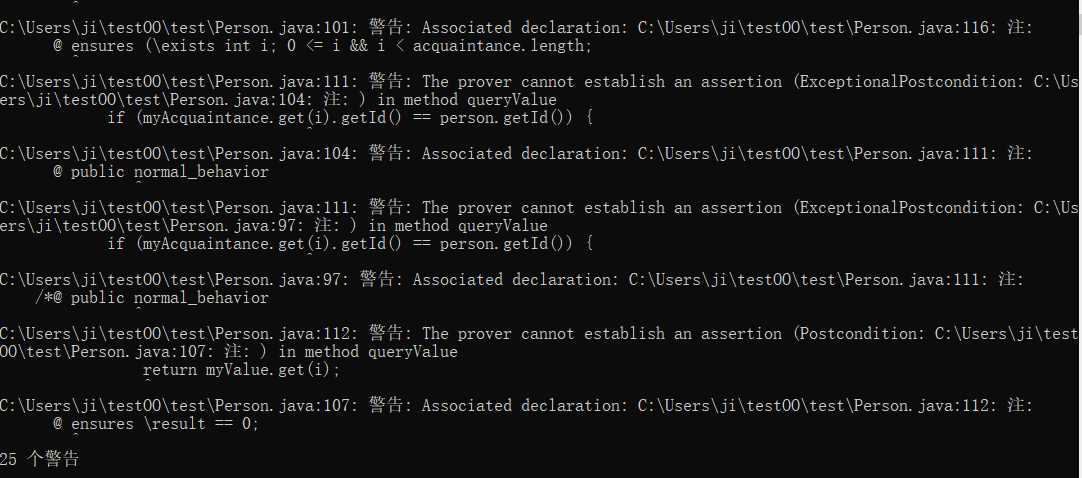
但是个人觉得这些修改对于代码的正确性、可读性或是性能都没有什么价值,对JML规格语法的正确性和规范性可能有一定帮助,但对于代码实现的检查比较弱。在一些简单函数加了一些错误之后部分可以查出来,比如没有抛出异常,但大部分无法验证,可能与The prover cannot establish an assertion的警告有关。
总之还是没太领悟到这个工具的奥义。
用JMLUnitNG对Person接口和Group接口的实现自动生成了测试样例。
结果如下:
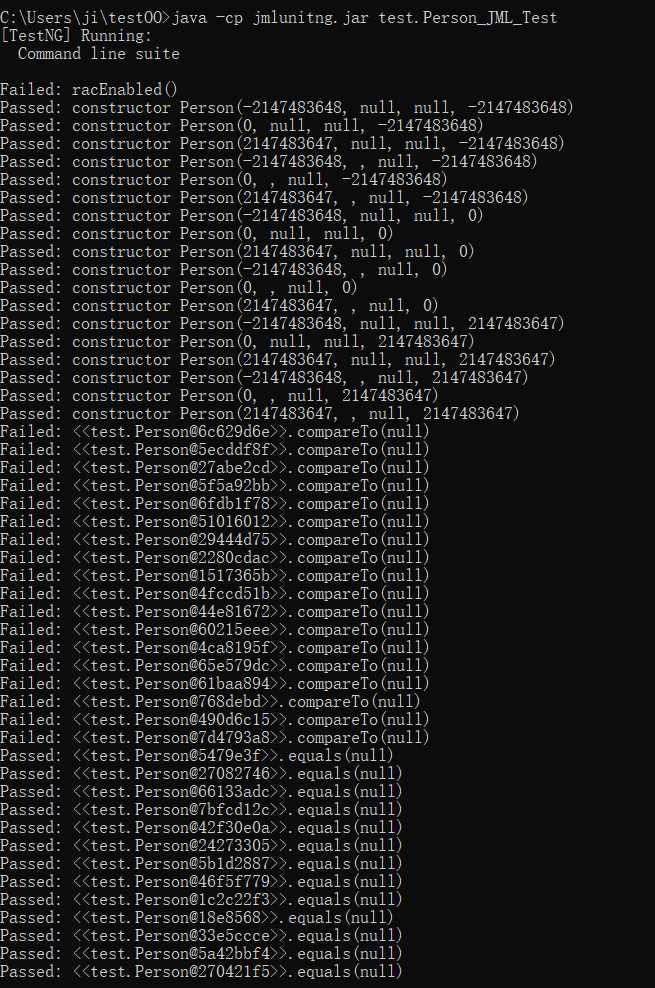
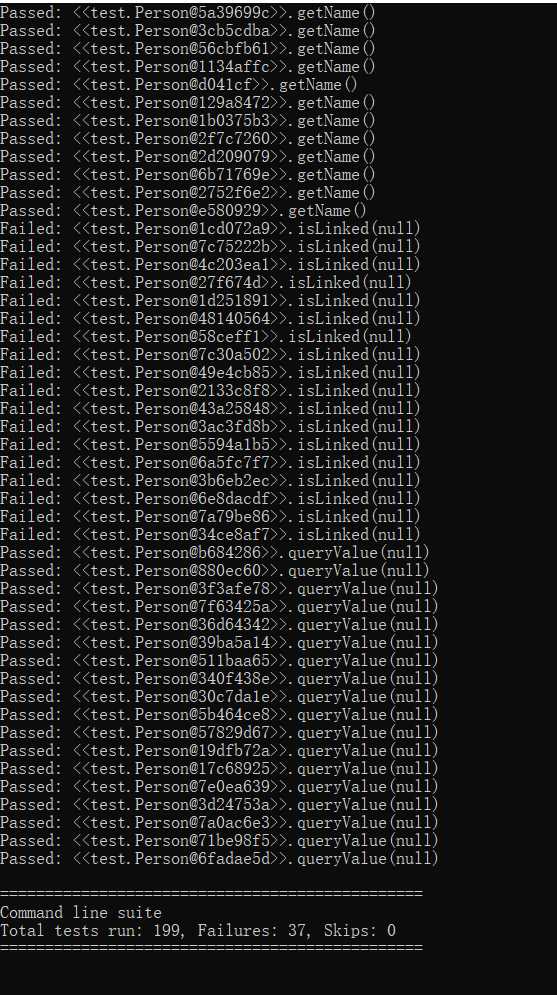
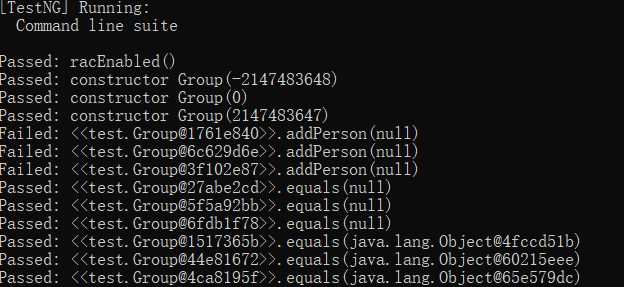
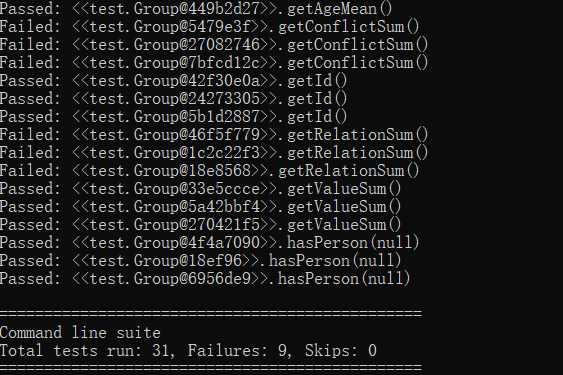
? 可以看出,大部分测试样例都是一些极端情况,数字是:-2147483648、0、2147483647,其余则是:null,所以结果也就是,没有对输入是null进行处理的方法,如compareTo()结果是False,对输入是null进行了处理的方法,如equals()结果是True。
? 但是这些极端情况,在部分方法中不会出现,无需测试,即便需要测试,手动测也要方便得多,而且这个工具多次测试生成的数据也是相同的,对于代码正确性验证的帮助很小。
? 总之,也是没太领悟到这个工具的奥义。
? 第九次作业基本都是按照JML规格实现代码,以id为key,采用了Hashmap存储各类属性。
? isCircle()采用了dfs。
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| unithree.MainClass.main(String[]) | 1 | 3 | 6 |
| unithree.MyNetwork.DFS(int,int) | 5 | 4 | 5 |
| unithree.MyNetwork.MyNetwork() | 1 | 1 | 1 |
| unithree.MyNetwork.addPerson(Person) | 2 | 2 | 2 |
| unithree.MyNetwork.addRelation(int,int,int) | 4 | 8 | 9 |
| unithree.MyNetwork.compareAge(int,int) | 2 | 3 | 3 |
| unithree.MyNetwork.compareName(int,int) | 2 | 3 | 3 |
| unithree.MyNetwork.contains(int) | 1 | 1 | 1 |
| unithree.MyNetwork.getPerson(int) | 2 | 2 | 2 |
| unithree.MyNetwork.isCircle(int,int) | 3 | 4 | 4 |
| unithree.MyNetwork.queryAcquaintanceSum(int) | 2 | 2 | 2 |
| unithree.MyNetwork.queryConflict(int,int) | 2 | 3 | 3 |
| unithree.MyNetwork.queryNameRank(int) | 2 | 3 | 4 |
| unithree.MyNetwork.queryPeopleSum() | 1 | 1 | 1 |
| unithree.MyNetwork.queryValue(int,int) | 3 | 5 | 6 |
| unithree.MyPerson.MyPerson(int,String,BigInteger,int) | 1 | 1 | 1 |
| unithree.MyPerson.addAcquaintance(int,Person,int) | 1 | 1 | 1 |
| unithree.MyPerson.compareTo(Person) | 1 | 1 | 1 |
| unithree.MyPerson.equals(Object) | 2 | 2 | 3 |
| unithree.MyPerson.getAcquaintance() | 1 | 1 | 1 |
| unithree.MyPerson.getAcquaintanceSum() | 1 | 1 | 1 |
| unithree.MyPerson.getAge() | 1 | 1 | 1 |
| unithree.MyPerson.getCharacter() | 1 | 1 | 1 |
| unithree.MyPerson.getId() | 1 | 1 | 1 |
| unithree.MyPerson.getName() | 1 | 1 | 1 |
| unithree.MyPerson.isLinked(Person) | 3 | 2 | 3 |
| unithree.MyPerson.queryValue(Person) | 2 | 2 | 2 |
? 因为按照JML规格进行实现,方法复杂度较低。
? 第十次作业中,在MyPerson类和MyNetWork类中依旧采用id为key的HashMap存储,在MyGroup类中ArrayList与HashMap结合,因为在该类中,遍历和查询都较多。
? 因为在上次作业中出现了严重的超时,所以将isCircle()的实现改为了并查集,也是用HashMap存储pre和rank,对于geConflictSum()、getAgeMean()、getAgeVar()等方法都采用了缓存机制,即在MyGroup类中addPerson()的时候就改变这些函数相应的成员变量。
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| unithree.MainClass.main(String[]) | 1 | 6 | 6 |
| unithree.MyGroup.MyGroup(int) | 1 | 1 | 1 |
| unithree.MyGroup.addPerson(Person) | 1 | 4 | 5 |
| unithree.MyGroup.addValueSum(Person,Person,int) | 2 | 2 | 3 |
| unithree.MyGroup.equals(Object) | 2 | 2 | 3 |
| unithree.MyGroup.getAgeMean() | 2 | 1 | 2 |
| unithree.MyGroup.getAgeVar() | 2 | 1 | 2 |
| unithree.MyGroup.getConflictSum() | 2 | 1 | 2 |
| unithree.MyGroup.getId() | 1 | 1 | 1 |
| unithree.MyGroup.getPeopleSum() | 1 | 1 | 1 |
| unithree.MyGroup.getRelationSum() | 1 | 1 | 1 |
| unithree.MyGroup.getValueSum() | 1 | 1 | 1 |
| unithree.MyGroup.hasPerson(Person) | 1 | 1 | 1 |
| unithree.MyGroup.hashCode() | 1 | 1 | 1 |
| unithree.MyNetwork.MyNetwork() | 1 | 1 | 1 |
| unithree.MyNetwork.addGroup(Group) | 2 | 2 | 2 |
| unithree.MyNetwork.addPerson(Person) | 2 | 2 | 2 |
| unithree.MyNetwork.addRelation(int,int,int) | 5 | 8 | 15 |
| unithree.MyNetwork.addtoGroup(int,int) | 5 | 7 | 10 |
| unithree.MyNetwork.compareAge(int,int) | 2 | 2 | 5 |
| unithree.MyNetwork.compareName(int,int) | 2 | 2 | 5 |
| unithree.MyNetwork.contains(int) | 1 | 1 | 1 |
| unithree.MyNetwork.find(int) | 2 | 2 | 2 |
| unithree.MyNetwork.getGroup(int) | 1 | 1 | 1 |
| unithree.MyNetwork.getPerson(int) | 2 | 2 | 2 |
| unithree.MyNetwork.isCircle(int,int) | 3 | 4 | 4 |
| unithree.MyNetwork.queryAcquaintanceSum(int) | 2 | 2 | 3 |
| unithree.MyNetwork.queryConflict(int,int) | 2 | 2 | 5 |
| unithree.MyNetwork.queryGroupAgeMean(int) | 2 | 2 | 3 |
| unithree.MyNetwork.queryGroupAgeVar(int) | 2 | 2 | 3 |
| unithree.MyNetwork.queryGroupConflictSum(int) | 2 | 2 | 3 |
| unithree.MyNetwork.queryGroupPeopleSum(int) | 2 | 2 | 2 |
| unithree.MyNetwork.queryGroupRelationSum(int) | 2 | 2 | 3 |
| unithree.MyNetwork.queryGroupSum() | 1 | 1 | 1 |
| unithree.MyNetwork.queryGroupValueSum(int) | 2 | 2 | 3 |
| unithree.MyNetwork.queryNameRank(int) | 2 | 3 | 5 |
| unithree.MyNetwork.queryPeopleSum() | 1 | 1 | 1 |
| unithree.MyNetwork.queryValue(int,int) | 3 | 4 | 8 |
? 因为并查集的实现和缓存机制,使addGroup()、addPerson()的复杂度较高,其余方法的复杂度较低。
? 第十一次作业采用的容器及原有函数的实现没有变化,主要问题在于queryMinPath()、queryStrongLinked()、queryBlockSum()三个函数的实现。
? 因为原本isCircle()的实现就采取了并查集,所以queryBlockSum()的实现较为简单,设置成员变量blockSum,在addPerson()时加一,在addRelation()时,若find()函数结果相同则减一。
? queryMinPath()采用堆优化的dijkstra算法,利用优先队列实现堆,存储PersonEdge,并在该类中实现Comparable接口。找到最小距离后return,不记录结果。
? queryStrongLinked()采用了Tarjian算法。最开始采用了两次dfs,删掉第一次找到的路径的方法,发现存在bug之后,改为了Tarjian算法,记录了每个连通分量,判断连通分量中是否包含起始点和终止点。并且在一开始就对相连的两个点进行特判。
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| unithree.Dijkstra.dijkstra(Person,Person) | 6 | 5 | 8 |
| unithree.Edge.Edge(int,int) | 1 | 1 | 1 |
| unithree.Edge.getFrom() | 1 | 1 | 1 |
| unithree.Edge.getTo() | 1 | 1 | 1 |
| unithree.MainClass.main(String[]) | 1 | 6 | 6 |
| unithree.MyGroup.delPerson(Person) | 1 | 4 | 5 |
| unithree.MyNetwork.borrowFrom(int,int,int) | 3 | 2 | 8 |
| unithree.MyNetwork.delFromGroup(int,int) | 4 | 4 | 8 |
| unithree.MyNetwork.queryBlockSum() | 1 | 1 | 1 |
| unithree.MyNetwork.queryMinPath(int,int) | 4 | 2 | 12 |
| unithree.MyNetwork.queryMoney(int) | 2 | 1 | 3 |
| unithree.MyNetwork.queryStrongLinked(int,int) | 5 | 5 | 11 |
| unithree.PersonEdge.PersonEdge(Person,int) | 1 | 1 | 1 |
| unithree.PersonEdge.compareTo(PersonEdge) | 1 | 1 | 1 |
| unithree.PersonEdge.getPerson() | 1 | 1 | 1 |
| unithree.PersonEdge.getValue() | 1 | 1 | 1 |
| unithree.Tarjian.Tarjian() | 1 | 1 | 1 |
| unithree.Tarjian.containEdge(HashSet |
2 | 2 | 3 |
| unithree.Tarjian.tarjan(Person,Person,int,int) | 11 | 11 | 16 |
| unithree.Tarjian.tarjianLink(Person,Person,int,int) | 5 | 4 | 6 |
? 可以看出dijkstra算法、Tarjian算法的复杂度较高。
? 在第九次作业中,dfs方法的实现出现错误,导致了许多TLE,强测比较惨,互测也被hack得很惨。
? 因为只利用Junit做了简单的测试,没有用大规模数据进行测试,导致测试时没有发现超时的严重问题。
? 在bug修复中,改为了并查集,所有测试点通过。
? 在第十次作业开始,用python进行自动化测试。随机生成大量数据,并用networkx包建相应的图,调用方法即可测试isCircle(),对于其他函数的测试,则直接对应JML规格在python程序中循环,检查结果是否一致。
G = nx.Graph()
G.add_node(i)
G.add_edge(i1,i2,weight=value)
a = nx.single_source_shortest_path(G, i1)
a = nx.dijkstra_path_length(G,source=i1,target=i2)
a = nx.dijkstra_path(G,source=i1,target=i2)
? 同时用time.perf_counter()计算程序运行时间,使程序运行时间大致上不出现太大的偏差。
? 在这次作业中,强测因为getValueSum()采取了双重循环TLE了一个点,互测也因此被hack。
? 在bug修复中,增加了valueSum成员变量,在addPerson()和addRelation()时修改该成员变量,所有测试点通过。
? 依旧采用python进行自动化测试,queryMinPath()可调用nx.dijkstra_path_length(G,source=id1,target=id2)对随机生成的数据进行验证,其余函数采用与JML规格相同的循环对程序进行测试。
? 终于在这次作业中,强测没有TLE。
? 第九次作业到第十一次作业,从强测的结果(第九次大片TLE,第十次TLE一个点,第十一次都通过)就可以看出,对我来说是一个逐渐进步的过程,从看着JML规格直接写,到开始思考容器的选择和函数的实现对性能的影响,寻找性能比较优的算法,从构造一些简单的测试样例,到用python进行各种极端情况的测试。
? 经过三次的作业,对JML的语法和根据JML规格实现代码有了一定的了解,在有规格之后写代码,能很大程度上提高效率,而且使代码的结构更好,复杂度也更低。更好地理解需求,使代码的正确性提高,从而能更好地专注于性能的提升。对于多人协作,描述各自的任务是一个非常好的工具。对于个人来说,要在代码前设计好类和方法,并写出规格,还是比较困难,但是今后在动手前,也会更多地思考自己的架构。
标签:提高 价值 map rom 算法 大量数据 image 输入 networkx
原文地址:https://www.cnblogs.com/AhaSokach/p/12943555.html