标签:dash imp tin 出现 ref tab tar cto sel



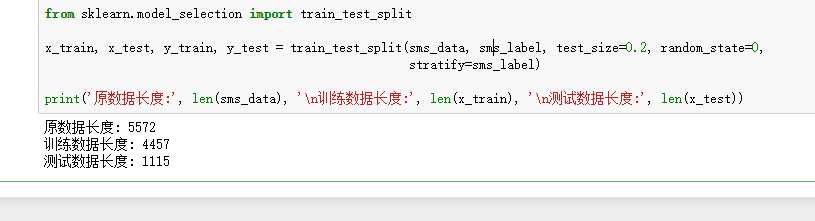
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0, stratify=y_train)
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
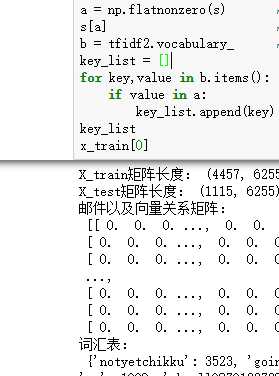
观察邮件与向量的关系
向量还原为邮件

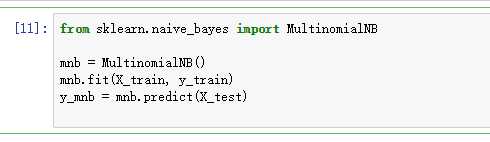
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?
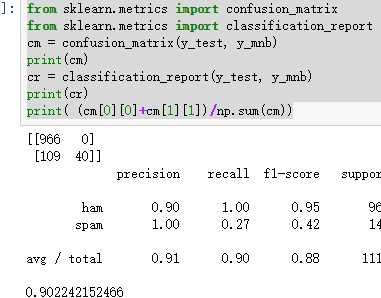
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
说明混淆矩阵的含义
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
CountVectorizer:特征数值计算类,文本特征提取方法。
对于每一个训练文本,CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语在该训练文本出现的次数。
TfidfVectorizer:可以把原始文本转化为tf-idf的特征矩阵,从而为后续的文本相似度计算,还关注其他包含这个词的文本,挖掘更有意义的特征。
后者比较灵活。
标签:dash imp tin 出现 ref tab tar cto sel
原文地址:https://www.cnblogs.com/yuyuyuyuyuyuyuyuuyuyuyuyuyuyuy/p/12944600.html