标签:mic 数据 说明 程序 操作 个人 非阻塞io 不同的 volatil
redis号称单机QPS可达10万。为什单线程的redis竟然能达到这么高的qps?
网上有很多大佬已经给我们总结好了:
1、完全是内存操作
2、单线程处理
3、高效的数据结构,redis有自己的一套数据结构
4、使用多路复用i/o模型,非阻塞
5、其他方面的优化
我想多问几个问题:
第一点,redis完全是内存操作,我不否认内存操作很快,但是这一点能成为redis比memcache快的原因吗?显然不能,因为memcache也是内存操作。
第二点,redis单线程处理(主要指的是redis的核心部件文件事件处理器是单线程设计的)。这个地方有点意思了,memcache是多线程的,二者可以对比一下。而且在多核cpu的机器中,大部分情况下,多线程对cpu的利用率肯定是玩爆单线程的。那为什么多线程的memcache在大部分情况下qps没有单线程redis的数据好看呢?这个时候我觉得应该看看在缓存处理这种应用场景下,多线程和单线程分别的优缺点:
多线程的优点是可以利用多核cpu,提高效率,缺点是:需要考虑线程安全,加锁的复杂度和效率会有下降。单线程的优缺点恰恰与之相反。
现在根本的矛盾就是:
多线程模式下:多核cpu利用后提升的效率 VS 线程安全降低的效率。
单线程模式下:无法利用多核cpu损失的效率 VS 线程安全提升的效率。
相同的任务,执行的事件越短,说明你的效率越高。
简单的说:我们要把缓存中的字符串abcdefj修改为abcdef,完成这个操作的时间越短,说明效率越高。
模拟一下多线程处理方式:
redis使用的是事件驱动模型,每来一个连接回话,服务端都当成一个事件处理。这里简单介绍一下事件驱动,事件驱动有三要素:1、事件源;2、事件监听器;3、事件处理器;
redis文件事件处理器分为四部分:
套接字、i/o多路复用、事件分发器、事件处理器
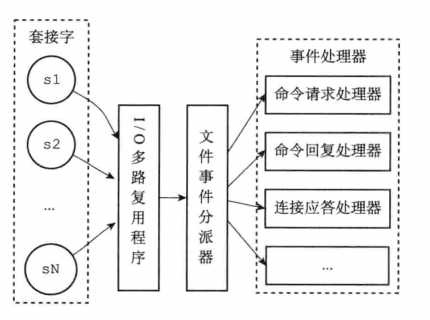
redis连接使用的是非阻塞io多路复用,将每个连接事件放入队列中,然后由一个单线程去消费这个队列并将事件根据状态分发给不同的事件处理器,这个单线程也叫事件分发器。被事件处理器处理后的事件状态会被改变,这个时候此事件会被事件分发器再次根据事件状态分发给对应的事件处理器。结合上面的事件驱动模型,redis客户端是事件源,事件分发处理器是事件监听器,事件处理器对应redis的事件处理器。
redis对数据结构做了很好的优化,在存储100k一下的数据时候,效率很高,memcahe不是对手。
单线程不能充分利用多核cpu的优势,上面这些内容最多可以解释redis为什么这么快,并不能解释为什么redis的线程模型要设计成单线程的,个人觉得既然设计者当初设计成单线程的,应该有一个很合适的理由。
官网的解答:
在多线程redis出现之前,redis官方的FAQ针对 单线程模型的redis如何利用多核cpu的解答,大概意思是:单线程的redis已经很快了,没必要使用多线程,如果先要使用多核cpu,可以在同一台机器上创建多个redis实例。
上面是早期的redis版本,现在都0202年了,截止到今天2020-05-23,redis官网公布的最新稳定版是redis6.0.3,redis的读支持了多线程,但是默认不开启,需要配置io-threads-do-reads yes
单线程处理任务的好处:
1、避免了锁的竞争(因为redis读写操作可能是同一个数据,单线程巧妙的避开了锁)
2、避免了线程上下文的切换
参考:
https://blog.csdn.net/xlgen157387/article/details/79470556
https://www.cnblogs.com/gz666666/p/12901507.html
《redis设计与实现》
https://www.javazhiyin.com/22943.html
https://www.javazhiyin.com/28400.html
https://juejin.im/post/5eb23787f265da7bb87727f7
https://www.cnblogs.com/jaycekon/p/6227442.html
标签:mic 数据 说明 程序 操作 个人 非阻塞io 不同的 volatil
原文地址:https://www.cnblogs.com/poorloser/p/12939651.html