标签:正式 put 抽取 end 细粒度 节点 分布式协调 隔离级别 生产
Kafka快速入门(三)——Kafka核心技术压缩(compression)是用时间换空间的经典trade-off思想,使用CPU时间换磁盘空间或网络I/O传输量,以较小的CPU开销带来更少的磁盘占用或更少的网络I/O传输。
Kafka有两类消息格式,V1版本和V2版本,V2 版本在Kafka 0.11.0.0中正式引入。
Kafka的消息层次都分为两层:消息集合(message set)以及消息(message)。消息集合中包含若干条日志项(record item),而日志项才是真正封装消息数据的实体。Kafka底层的消息日志由一系列消息集合日志项组成。Kafka通常不会直接操作具体的一条条消息,而是在消息集合层面上进行写入操作。V2版本主要针对V1版本的缺陷进行修正,将消息的公共部分抽取出来放到外层的消息集合里,不用每条消息都保存。比如,在V1版本中,每条消息都需要执行CRC校验,但在Broker端可能会对消息时间戳字段进行更新,CRC值也会相应更新;比如Broker端在执行消息格式转换时(兼容老版本客户端程序),CRC值也会变化。逐条消息执行CRC校验不仅浪费空间还浪费CPU资源,因此在V2版本中,消息CRC校验被移到消息集合。
在Kafka中,消息压缩可能发生在生产者端和Broker端。生产者程序中配置compression.type参数即表示启用指定类型的压缩算法。构建一个开启GZIP压缩算法的Producer对象的Java代码如下:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 开启GZIP压缩
props.put("compression.type", "gzip");
Producer<String, String> producer = new KafkaProducer<>(props);Producer启动后生产的每个消息集合都是经GZIP压缩过的,可以很好地节省网络传输带宽以及Kafka Broker端的磁盘占用。
通常,Broker从Producer端接收到消息后会原封不动地保存而不会对其进行任何修改,但有两种情况会进行解压缩操作。
(1)Broker端和Producer端指定了不同的压缩算法。如Producer指定要使用GZIP进行压缩,但Broker指定必须使用Snappy算法进行压缩。因此,Broker接收到GZIP压缩消息后,只能解压缩然后使用Snappy重新压缩一遍。Broker端的compression.type参数用于指定压缩算法,默认值是producer,表示Broker端会使用Producer端使用的压缩算法。如果在Broker端设置了不同的compression.type值,可能会发生预料外的压缩/解压缩操作,通常表现为Broker端CPU使用率飙升。
(2)Broker端发生消息格式转换。消息格式转换主要是为了兼容老版本的消费者程序。生产环境中,Kafka集群中同时保存多种版本的消息格式非常常见。为了兼容老版本的消息格式,Broker端会对新版本消息执行向老版本格式的转换。转换过程中会涉及消息的解压缩和重新压缩。消息格式转换对性能是有很大影响的,除了压缩导致的性能损失,Kafka也会丧失Zero Copy特性。
解压缩通常发生在消费者程序中,Producer发送压缩消息到Broker后,Broker会原封不动保存。当Consumer程序请求消息时,Broker 会原样发出,当消息到达Consumer端后,Consumer自行解压缩消息。Kafka会将使用的压缩算法封装进消息集合中,当Consumer读取到消息集合时,会知道消息使用的压缩算法。除了在Consumer端解压缩,Broker端也会进行解压缩,每个压缩过的消息集合在Broker端写入时都要发生解压缩操作,对消息执行各种验证。解压缩对Broker端性能是有一定影响的。
Kafka 2.1.0 版本前,Kafka支持GZIP、Snappy、LZ4三种压缩算法。Kafka 2.1.0开始,Kafka正式支持Zstandard算法(简写为zstd),是 Facebook开源的一个压缩算法,能够提供超高的压缩比(compression ratio)。压缩算法可以使用压缩比和压缩/解压缩吞吐量两个指标进行衡量。不同压缩算法的性能比较如下: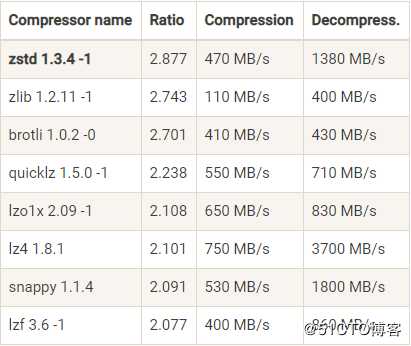
生产环境中,GZIP、Snappy、LZ4、zstd性能表现各有千秋,在吞吐量方面:LZ4 > Snappy > zstd > GZIP;在压缩比方面,zstd > LZ4 > GZIP > Snappy。
如果要启用Producer端的压缩,Producer程序运行机器上的CPU资源必须充足。除了CPU资源充足,如果生产环境中带宽资源有限,也建议Producer端开启压缩。通常,带宽比CPU和内存要昂贵的多,因此千兆网络中Kafka集群带宽资源耗尽很容易出现。如果客户端机器CPU资源富余,建议Producer端开启zstd压缩,可以极大地节省网络资源消耗。对于解压缩,需要避免非正常的解压缩,如消息格式转换的解压缩操作、Broker与Producer解压缩算法不一致。
消息交付可靠性保障是指Kafka对Producer和Consumer要处理的消息提供什么样的承诺。常见的承诺有以下三种:
最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
至少一次(at least once):消息不会丢失,但有可能被重复发送。精确一次(exactly once):消息不会丢失,也不会被重复发送。
目前,Kafka 默认提供的交付可靠性保障是至少一次。消息已提交的含义,即只有Broker成功提交消息且Producer接到Broker的应答才会认为消息成功发送。但如果消息成功提交,但Broker的应答没有成功发送回Producer端(如网络出现瞬时抖动),那么Producer就无法确定消息是否真的提交成功。因此,Producer只能选择重试,再次发送相同的消息。
Kafka也可以提供最多一次交付保障,只需要让Producer禁止重试即可,此时消息要么写入成功,要么写入失败,但绝不会重复发送。
Kafka的精确一次处理语义是通过幂等性(Idempotence)和事务(Transaction)两种机制实现的。幂等性Producer和事务型Producer是Kafka为实现精确一次处理语义所提供的工具,但作用范围是不同的。幂等性Producer只能保证单分区、单会话上的消息幂等性;而事务能够保证跨分区、跨会话间的幂等性。
幂等性在数学领域中指某些操作或函数能够被执行多次,但每次得到的结果都是不变的。幂等性最大的优势在于可以安全地重试任何幂等性操作,不会破坏系统状态。
在Kafka中,Producer默认不是幂等性的,但可以创建幂等性Producer。Kafka 0.11.0.0版本引入的幂等性,指定Producer幂等性的方法只需要设置一个参数即可,即props.put(“enable.idempotence”, true),或props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)。enable.idempotence被设置成true后,Producer自动升级成幂等性Producer,其它所有的代码逻辑都不需要改变。Kafka自动进行消息的重复去重。
幂等性Producer的作用范围:只能保证单分区上的幂等性,即一个幂等性Producer能够保证某个主题的一个分区上不出现重复消息,无法实现多个分区的幂等性;只能实现单会话上的幂等性,不能实现跨会话的幂等性。
在数据库领域,事务提供的安全性保障是经典的 ACID,即原子性(Atomicity)、一致性 (Consistency)、隔离性 (Isolation) 和持久性 (Durability)。很多数据库厂商对于隔离级别的有不同的实现,如有的数据库提供Snapshot隔离级别,但在其它数据库称为可重复读(repeatable read)。但对于已提交读(read committed)隔离级别,主流数据库厂商都比较统一。read committed指当读取数据库时,只能看到已提交的数据,即无脏读;当写入数据库时,只能覆盖掉已提交的数据,即无脏写。
Kafka 0.11版本开始提供了对事务的支持,目前主要在read committed隔离级别上做事情,能保证多条消息原子性地写入到目标分区,同时也能保证Consumer只能看到事务成功提交的消息。
事务型Producer能够保证将消息原子性地写入到多个分区中。消息集合的消息要么全部写入成功,要么全部失败。
事务型Producer可以进行进程重启,Producer重启后,Kafka Broker依然保证发送消息的精确一次处理。
设置事务型Producer需要开启 enable.idempotence = true,并设置 Producer端参数 transactional. id。
事务型Producer会调用一些事务API,如initTransaction、beginTransaction、commitTransaction 和 abortTransaction,分别对应事务的初始化、事务开始、事务提交以及事务终止。Java实例代码如下:
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}上述代码能够保证record1和record2被当作一个事务统一提交到Kafka,要么全部提交成功,要么全部写入失败。但即使写入失败,Kafka也会把消息写入到底层的日志中,即Consumer还是会看到消息。因此在Consumer端,读取事务型Producer发送的消息需要做一些修改,需要设置isolation.level参数的值。isolation.level参数值可选如下:
read_uncommitted:默认值,表明Consumer能够读取到Kafka写入的任何消息,不论事务型Producer提交事务还是终止事务,其写入的消息都可以读取。
read_committed:Consumer只会读取事务型Producer成功提交事务写入的消息,但Consumer也能看到非事务型Producer写入的所有消息。
Reactor模式是事件驱动架构的一种实现方式,特别适合应用于处理多个客户端并发向服务器端发送请求的场景。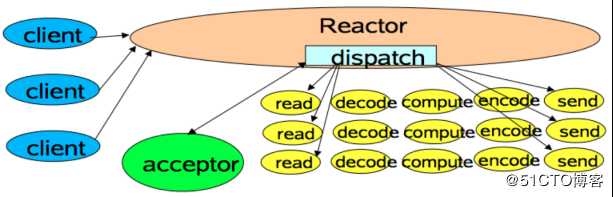
多个客户端会发送请求给到Reactor,Reactor的请求分发线程Dispatcher(Acceptor)会将不同的请求下发到多个工作线程中处理。Acceptor线程只是用于请求分发,不涉及具体的逻辑处理,非常轻量级,因此有很高的吞吐量表现;工作线程可以根据实际业务处理需要任意增减,从而动态调节系统负载能力。
Apache Kafka定义了一组请求协议,用于实现各种各样的交互操作。比如PRODUCE请求是用于生产消息的,FETCH请求是用于消费消息的,METADATA请求是用于请求Kafka集群元数据信息的。Kafka 2.3 版本共定义了多达45种请求格式。
Kafka使用Reactor模式处理请求。
Kafka的Broker端的SocketServer组件是Reactor模式中的Dispatcher角色,有对应的Acceptor线程和一个网络线程池。Kafka的Broker端参数num.network.threads用于调整网络线程池的线程数,默认值是3,表示每台Broker启动时会创建3个网络线程,专门处理客户端发送的请求。Acceptor线程采用轮询的方式将入站请求公平地发到所有网络线程中。当网络线程接收到请求后,进入异步线程池的处理。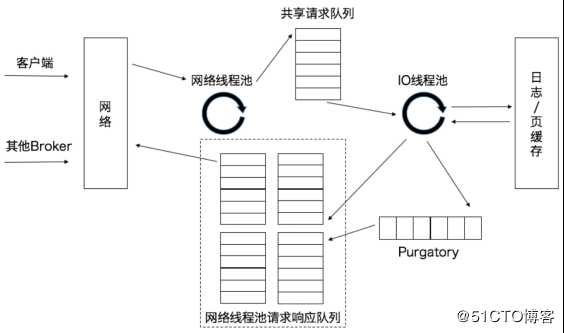
当网络线程收到请求后,会将请求放入到一个共享请求队列中。Broker端的IO线程池,负责从共享请求队列中取出请求,执行真正的处理。对于PRODUCE生产请求,则将消息写入到底层的磁盘日志中;对于FETCH请求,则从磁盘或页缓存中读取消息。IO线程池中的线程是执行请求逻辑的线程。Broker端参数num.io.threads用于控制线程池中的线程数,参数默认值是8,表示每台Broker启动后自动创建8个IO线程处理请求,可以根据实际硬件条件设置IO线程池的个数。当IO线程处理完请求后,会将生成的响应发送到网络线程池的响应队列中,然后由对应的网络线程负责将Response返还给客户端。
请求队列是所有网络线程共享的,而响应队列则是每个网络线程专属的,因为Dispatcher只是用于请求分发而不负责响应回传,因此只能让每个网络线程自己发送Response给客户端。
Purgatory组件是用来缓存延时请求(Delayed Request)的。延时请求是一时未满足条件不能立刻处理的请求,如设置了acks=all的PRODUCE请求,一旦设置了acks=all,那么请求就必须等待ISR中所有副本都接收消息后才能返回,此时处理请求的IO线程就必须等待其他 Broker的写入结果。当请求不能立刻处理时,就会暂存在Purgatory 中。一旦满足完成条件,IO线程会继续处理请求,并将Response放入对应网络线程的响应队列中。
Kafka Broker对所有请求是一视同仁的。但Kafka内部除了客户端发送的PRODUCE请求和FETCH请求外,还有很多执行其他操作的请求类型,如负责更新Leader副本、Follower副本以及ISR集合的LeaderAndIsr请求,负责勒令副本下线的StopReplica请求等。Kafka把PRODUCE和FETCH请求称为数据类请求,把LeaderAndIsr、StopReplica请求称为控制类请求。
Controller是Apache Kafka的核心组件,用于在Apache ZooKeeper的帮助下管理和协调整个Kafka集群,集群中任意一台Broker都能充当Controller的角色,但在运行过程中,只能有一个Broker成为控制器,行使其管理和协调的职责。每个正常运转的Kafka集群,在任意时刻都有且只有一个Controller。JMX指标activeController可以帮助实时监控控制器的存活状态,在实际运维操作过程中需要实时查看。
Kafka集群的多个Broker中,其中一个会被选举为Controller,负责管理整个集群中Partition和Replicas的状态。负责Leader的选举。
只有Broker Controller会向Zookeeper中注册Watcher,其他Broker及分区无需注册,即Zookeeper仅需监听Broker Controller的状态变化即可。
Apache ZooKeeper是一个提供高可靠性的分布式协调服务框架,所使用的数据模型类似于文件系统的树形结构,根目录也是以“/”开始。树形结构上的每个节点被称为znode,用来保存一些元数据协调信息。如果以znode持久性来划分,znode可分为持久性znode和临时znode。持久性znode不会因为ZooKeeper集群重启而消失,而临时znode则与创建其的ZooKeeper会话绑定,一旦会话结束,节点会被自动删除。
ZooKeeper赋予客户端监控znode变更的能力,即Watch通知功能。一旦znode节点被创建、删除,子节点数量发生变化,抑或是znode所存的数据本身变更,ZooKeeper会通过节点变更监听器 (ChangeHandler) 的方式显式通知客户端。ZooKeeper常被用来实现集群成员管理、分布式锁、领导者选举等功能。Kafka Controoler大量使用Watch功能实现对集群的协调管理。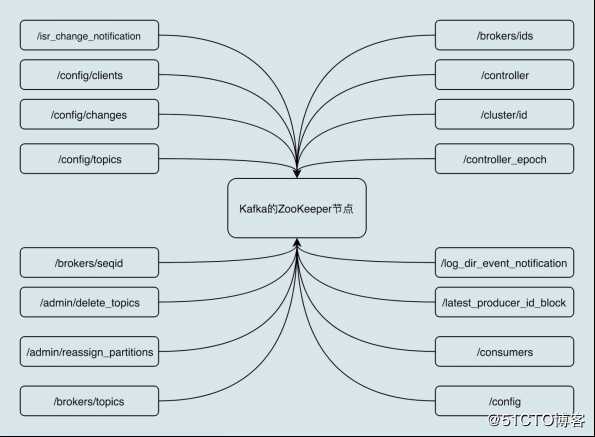
Broker在启动时,会尝试去ZooKeeper中创建/controller节点。Kafka选举Controller的规则是:第一个成功创建/controller节点的Broker会被指定为Controller。
(1)主题管理(创建、删除、增加分区)。主题管理是指Controller帮助完成对Kafka主题的创建、删除以及分区增加的操作。当执行kafka-topics脚本时,大部分的后台工作是由Controller完成的。
(2)分区再分配。分区再分配是指kafka-reassign-partitions脚本提供的对已有主题分区进行细粒度的分配功能。
(3)Preferred领导者选举。Preferred领导者选举主要是Kafka为避免部分Broker负载过重而提供的一种换Leader的方案。
(4)集群成员管理(新增Broker、Broker主动关闭、Broker宕机),包括自动检测新增Broker、Broker主动关闭及被动宕机。自动检测是依赖于Watch功能和ZooKeeper临时节点组合实现的。Controller会利用Watch机制检查ZooKeeper的/brokers/ids节点下的子节点数量变更。当有新Broker启动后,会在/brokers下创建专属的znode节点。一旦创建完毕,ZooKeeper会通过Watch机制将消息通知推送给Controller,Controller就能自动地感知到变化,进而开启后续的新增Broker作业。侦测Broker存活性则是依赖于临时节点。每个Broker启动后,会在/brokers/ids下创建一个临时znode。当Broker宕机或主动关闭后,Broker与ZooKeeper的会话结束,znode会被自动删除。ZooKeeper 的Watch机制将变更推送给Controller,Controller就能知道有Broker关闭或宕机,从而进行善后处理。
(5)数据服务。Controller上保存了最全的集群元数据信息,其它所有 Broker会定期接收Controller发来的元数据更新请求,从而更新其内存中的缓存数据。
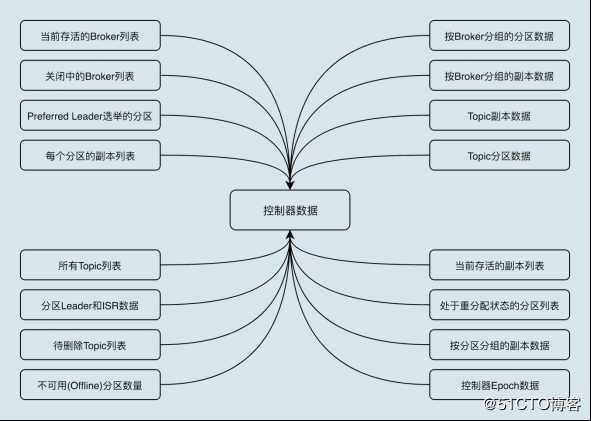
所有主题信息,包括具体的分区信息,比如领导者副本是谁,ISR集合中有哪些副本等。
所有Broker信息,包括当前都有哪些运行中的Broker,哪些正在关闭中的Broker等。
所有涉及运维任务的分区,包括当前正在进行Preferred领导者选举以及分区再分配的分区列表。
Controller保存的数据在ZooKeeper中也保存一份,每当Controller初始化时,会从ZooKeeper上读取对应的元数据并填充到自己的缓存中。
在Kafka集群运行过程中,只能有一台Broker充当控制器,存在单点失效(Single Point of Failure)的风险,因此Kafka为Controller提供故障转移功能(Failover)。故障转移是指当运行中的控制器突然宕机或意外终止时,Kafka能够快速地感知到,并立即启用备用Controller来代替失败的控制器。故障转移过程是自动完成。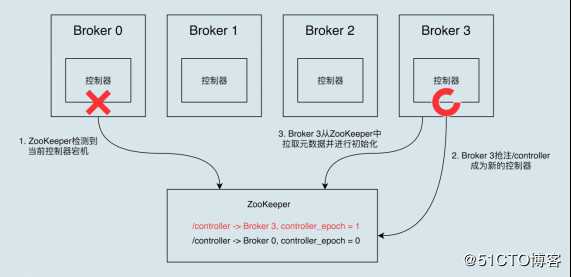
开始时,Broker 0是控制器。当Broker 0宕机后,ZooKeeper通过Watc机制感知到并删除/controller临时节点。然后,所有存活的Broker开始竞选新的Controller身份,Broker 3最终赢得选举,成功地在ZooKeeper上重建 /controller节点。Broker 3会从ZooKeeper中读取集群元数据信息,并初始化到自己的缓存中。
Kafka 0.11版本前,Controller是多线程的设计,会在内部创建很多个线程。Controller需要为每个Broker都创建一个对应的Socket连接,然后再创建一个专属的线程,用于向Broker发送特定请求。Controller连接ZooKeeper的会话,也会创建单独的线程来处理Watch机制的通知回调。Controller还会为主题删除创建额外的I/O线程。
Controller创建的多线程会访问共享的控制器缓存数据,为了保护数据安全性,Controller不得不在代码中大量使用ReentrantLock同步机制,进一步拖慢了整个Controller的处理速度。
Kafka 0.11版本重构了Kafka 0.11版本的底层设计,把多线程的方案改成了单线程加事件队列的方案。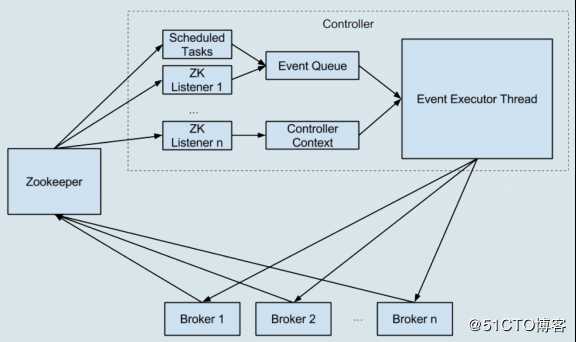
事件处理线程统一处理各种Controller事件,然后Controller将原来执行的操作全部建模成一个个独立的事件,发送到专属的事件队列中,供线程消费。Controller缓存中保存的状态只被一个线程处理,因此不再需要重量级的线程同步机制来维护线程安全,Kafka不用再担心多线程并发访问的问题,非常利于社区定位和诊断控制器的各种问题。
Kafka 0.11版本将Controller的同步操作ZooKeeper全部改为异步操作,大幅提高性能(ZooKeeper写入性能提升10倍)。ZooKeeper本身的API提供了同步写和异步写两种方式,Kafka 0.11版本前Controller操作ZooKeeper使用的是同步API,性能很差,当有大量主题分区发生变更时,ZooKeeper容易成为系统瓶颈。
水位是一个单调增加且表征最早未完成工作(oldest work not yet completed)的时间戳。水位通常用于流式处理领域。
Kafka水位是用消息位移来表征的,不是时间戳,与时间无关。Kafka水位的作用如下:
(1)定义消息可见性,即用来标识分区下的哪些消息是可以被消费者消费的。
(2)帮助 Kafka 完成副本同步。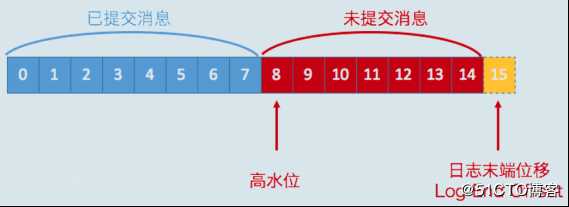
在分区高水位以下的消息被认为是已提交消息,在分区高水位以上的消息是未提交消息,消费者只能消费已提交消息,高水位上的消息是不能被消费者消费的。
日志末端位移(LEO,Log End Offset)表示副本写入下一条消息的位移值。当前分区副本当前只有15条消息,位移值是从0到14,下一条新消息的位移是15。介于高水位和LEO之间的消息就属于未提交消息。同一个副本对象,其高水位值不会大于LEO值。Kafka所有副本都有对应的高水位和LEO值,而不仅仅是Leader 副本。只不过Leader副本比较特殊,Kafka使用Leader副本的高水位来定义所在分区的高水位。分区的高水位就是其Leader副本的高水位。
每个副本对象都保存了一组高水位值和LEO值,在Leader副本所在的Broker上还保存了其它Follower副本的LEO值。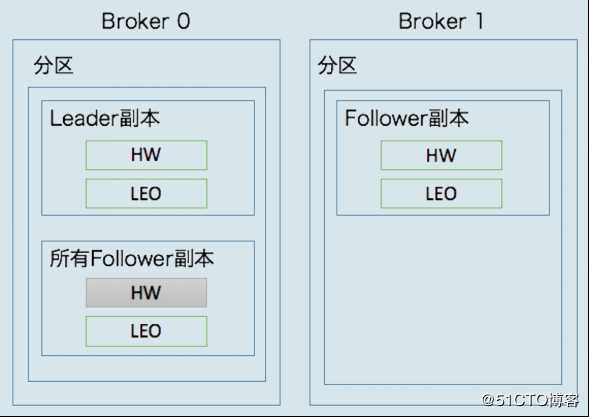
Broker 0保存了某分区的Leader副本和所有Follower副本的LEO值,而Broker1上仅仅保存了分区的某个Follower副本。Kafka把Broker 0上保存的Follower副本称为远程副本(Remote Replica)。Kafka副本机制在运行过程中,会更新Broker 1上Follower副本的高水位和LEO值,同时也会更新Broker 0上Leader副本的高水位和LEO以及所有远程副本的LEO,但不会更新远程副本的高水位值。在Broker 0 上保存远程副本的主要作用是,帮助Leader副本确定其分区高水位。
如果Partition Leader接收到新的消息,ISR中其它Follower正在同步过程中,还未同步完毕时Leader宕机,此时需要选举出新的Leader。若没有HW截断机制,将会导致Partition中Leader与Follower 数据的不一致。
当原Partition Leader宕机后又恢复时,将其LEO回退到其宕机时的HW,然后再与新的Leader进行数据同步,保证旧Partition Leader与新Partition Leader中数据一致,称为HW截断机制。
HW(HighWatermark),高水位,表示Consumer可以消费到的最高 Partition偏移量。HW保证了 Partition的Follower与Leader间数据的一致性,即保证了Kafka集群中消息的一致性。
LEO(Log End Offset),日志最后消息的偏移量,是当前最后一个写入的消息在Partition中的偏移量。
对于Leader新写入的消息,Consumer是不能立刻消费的。Leader 会等待消息被所有ISR中的Partition Follower同步后才会更新HW,此时消息才能被Consumer消费。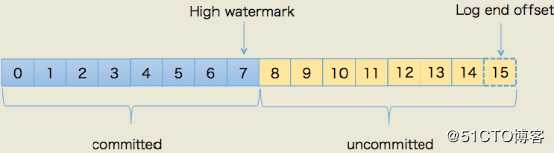
标签:正式 put 抽取 end 细粒度 节点 分布式协调 隔离级别 生产
原文地址:https://blog.51cto.com/9291927/2497820