标签:cal 开发工具 point ike please 间隔 eve 地址 check
DStream的转化操作DStream API提供的与转化操作相关的方法如下: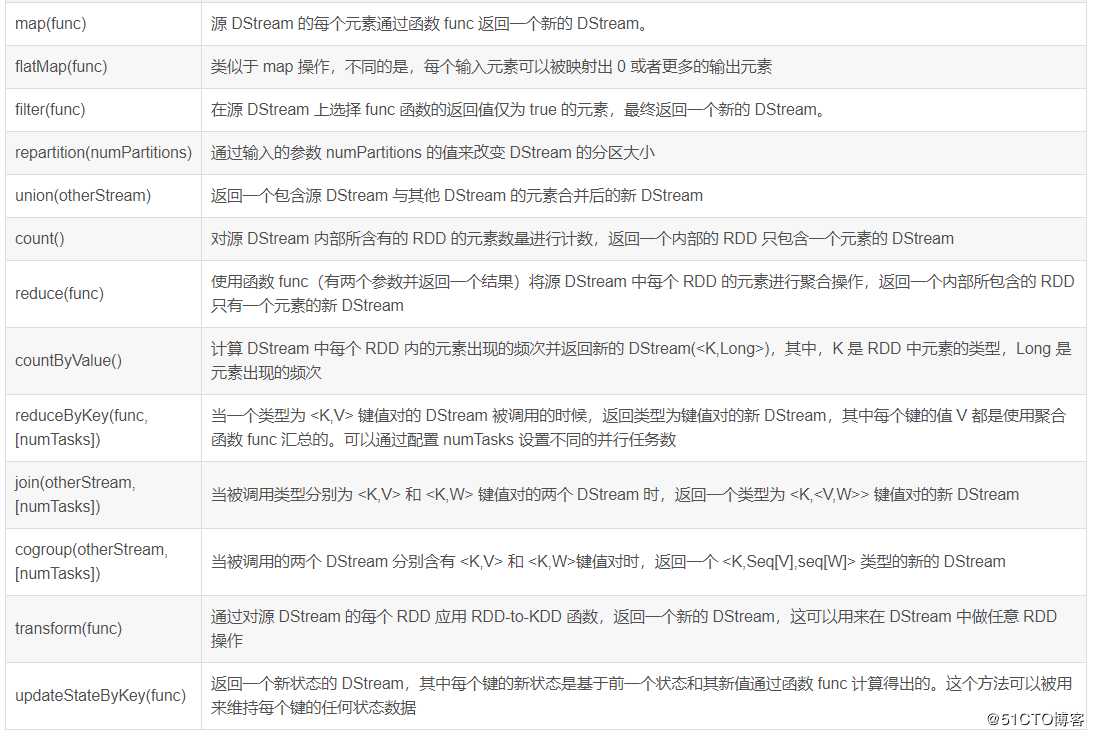
如下举例详解transform(func) 方法和 updateStateByKey(func) 方法:
transform 方法及类似的 transformWith(func) 方法允许在 DStream 上应用任意 RDD-to-RDD 函数,它们可以被应用于未在 DStream API 中暴露的任何 RDD 操作中。
下面举例演示如何使用transform(func) 方法将一行语句分隔成多个单词,具体步骤如下:
A、在Liunx中执行命令nc –lk 9999 启动服务器且监听socket服务,并且输入数据I like spark streaming and Hadoop,具体命令如下:
B、打开IDEA开发工具,创建一个Maven项目,并且配置pom.xml文件,引入Spark Streaming相关的依赖包,pom.xml文件配置具体如下:
<!--设置依赖版本号-->
<properties>
<spark.version>2.1.1</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>注意:配置好pom.xml文件后,需要在项目的/src/main和/src/test目录下分别创建scala目录。
C、在项目的/src/main/scala目录下创建包,接着创建一个名为TransformTest的scala类,主要用于编写SparkStreaming应用程序,实现一行语句分隔成多个单词的功能,具体代码如下(带注释):
package SparkStreaming
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object TransformTest {
def main(args: Array[String]): Unit = {
//创建SparkConf对象
val sparkconf = new SparkConf().setAppName("TransformTest").setMaster("local[2]")
//创建SparkContext对象
val sc = new SparkContext(sparkconf)
//设置日志级别
sc.setLogLevel("WARN")
//创建StreamingContext,需要创建两个参数,分别为SparkContext和批处理时间间隔
val ssc = new StreamingContext(sc,Seconds(5))
//连接socket服务,需要socket服务地址、端口号以及存储级别(默认的)
val dstream:ReceiverInputDStream[String] = ssc.socketTextStream("192.168.169.200",9999)
//通过空格分隔
val words:DStream[String] = dstream.transform(line => line.flatMap(_.split(" ")))
//打印输出结果
words.print()
//开启流式计算
ssc.start()
//用于保护程序正常运行
ssc.awaitTermination()
}
}D、运行程序可以看出,语句I like spark streaming and Hadoop在5s内被分割成6个单词,结果如下图:
updateStateByKey(func) 方法可以保持任意状态,同时允许不断有新的信息进行更新。
下面举例演示如何使用updateStateByKey(func) 方法进行词频统计:
在项目的/src/main/scala目录下创建包,接着创建一个名为UpdateStateByKeyTest的scala类,主要用于编写SparkStreaming应用程序,实现词频统计,具体代码如下:
package SparkStreaming
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object UpdateStateByKeyTest {
def updateFunction(newValues:Seq[Int],runningCount:Option[Int]) : Option[Int] = {
val newCount = runningCount.getOrElse(0)+newValues.sum
Some(newCount)
}
def main(args: Array[String]): Unit = {
//创建SparkConf对象
val sparkconf = new SparkConf().setAppName("UpdateStateByKeyTest").setMaster("local[2]")
//创建SparkContext对象
val sc = new SparkContext(sparkconf)
//设置日志级别
sc.setLogLevel("WARN")
//创建StreamingContext,需要创建两个参数,分别为SparkContext和批处理时间间隔
val ssc = new StreamingContext(sc,Seconds(5))
//连接socket服务,需要socket服务地址、端口号以及存储级别(默认的)
val dstream:ReceiverInputDStream[String] = ssc.socketTextStream("192.168.169.200",9999)
//通过逗号分隔第一个字段和第二个字段
val words:DStream[(String,Int)] = dstream.flatMap(_.split(" ")).map(word => (word,1))
//调用updateStateByKey操作
var result:DStream[(String,Int)] = words.updateStateByKey(updateFunction)
//如果用到updateStateByKey,此处要加上ssc.checkpoint("目录")这一句,否则会报错:
// The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
//为什么要用到checkpoint?因为之前的案例是没有状态的,用完之后就丢掉,不需要了,
// 但是现在要用到之前的那些数据,要把之前的状态保留下来
//“.”的意思是当前目录
ssc.checkpoint(".")
//打印输出结果
result.print()
//开启流式计算
ssc.start()
//用于保护程序正常运行
ssc.awaitTermination()
}
}然后在9999端口不断输入单词,具体内容如下:

运行程序从控制台输出的结果看出每隔5s接受一次数据,一共接受了两次数据,并且每接受一次数据就会进行词频统计并输出结果。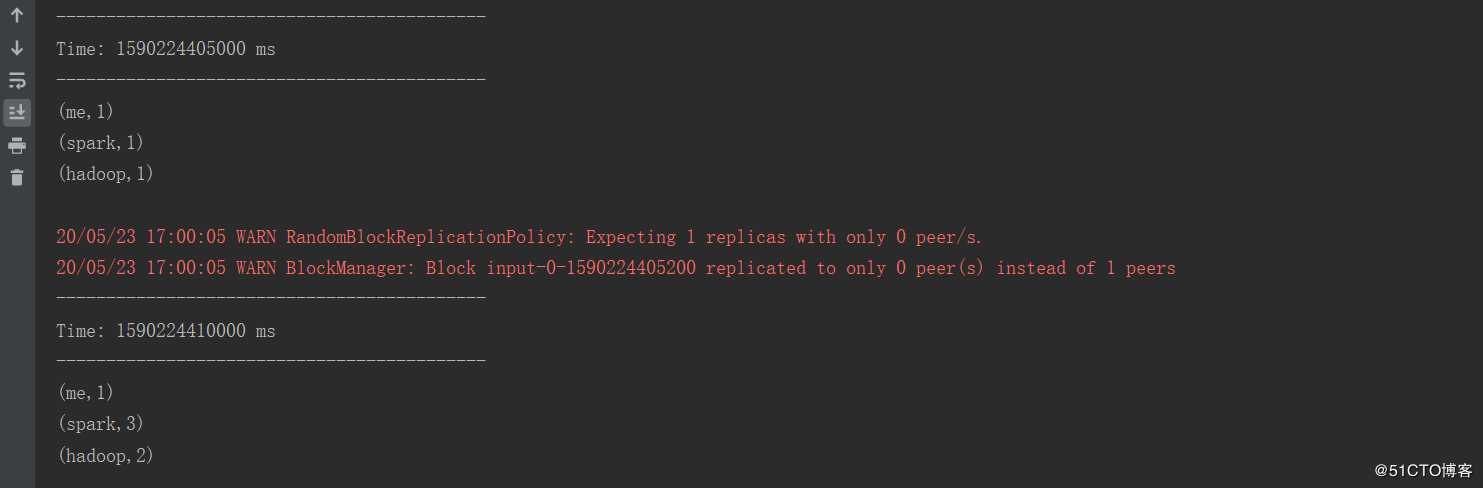
Spark Streaming的核心DStream之转换操作实例
标签:cal 开发工具 point ike please 间隔 eve 地址 check
原文地址:https://blog.51cto.com/14572091/2497948