标签:消息 行数据 called 消费 mod 元数据 intercept 操作 long
Kafka快速入门(四)——Kafka高级功能Kafka只针对已提交消息(committed message)做有限度的持久化保证。
当Kafka的若干个Broker成功地接收到一条消息并写入到日志文件后,会通知生产者程序相应消息已成功提交。多少个Broker成功保存消息算是已提交,可以由Producer参数或Broker端参数指定。
有限度的持久化保证是指Kafka不可能保证在任何情况下都做到不丢失消息,Kafka不丢消息的前提条件是保存消息的N个Kafka Broker 中至少有1个在线。
目前Kafka Producer是异步发送消息的,producer.send(msg)接口通常发送消息后会立即返回,但此时不能认为消息已经发送成功,因为网络瞬时抖动可能导致消息没有发送到Broker端,或者消息本身不合格导致Broker拒绝接收(如消息太大,超过Broker承受能力)。因此,Producer必须使用带有回调通知的producer.send(msg, callback)接口。callback(回调)可以准确地通知Producer消息是否真的提交成功,如果消息提交失败,可以针对性地进行处理。如果因为网络瞬时抖动导致发送失败,仅仅让Producer重试就可以;如果消息不合格导致发送失败,可以调整消息格式后再次发送。
Kafka 中Consumer Offset表示Consumer当前消费到的Topic分区的位置。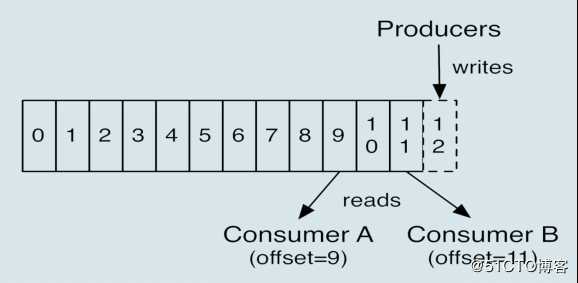
对于Consumer A,offset是9;Consumer B的offset是11。
Kafka中Consumer端的消息丢失是offset没有正确更新造成的。解决Consumer端的消息丢失的方法是维持先消费消息,再更新offset的顺序,可以最大限度地保证消息不丢失,但可能带来消息的重复处理问题。
Kafka中,如果Consumer从Kafka获取到消息后开启多个线程异步处理消息,而Consumer自动地向前更新位移。假如其中某个线程运行失败,所负责的消息没有被成功处理,但位移已经被更新,因此消息对于Consumer已经丢失。
如果多线程异步处理消费消息,Consumer程序不能开启自动提交位移,需要要应用程序手动提交位移。单个Consumer程序使用多线程消费消息代码极难实现,很难正确地处理位移更新,即很容易避免消费消息丢失,但极易出现消息被重复消费。
实现Kafka无丢失消息的解决方案如下:
(1)必须使用producer.send(msg, callback)接口发送消息。
(2)Producer端设置acks参数值为all。acks参数值为all表示ISR中所有Broker副本都接收到消息,消息才算已提交。
(3)设置Producer端retries参数值为一个较大值,表示Producer自动重试次数。当出现网络瞬时抖动时,消息发送可能会失败,此时Producer能够自动重试消息发送,避免消息丢失。
(4)设置Broker端unclean.leader.election.enable = false,unclean.leader.election.enable参数用于控制有资格竞选分区Leader的Broker。如果一个Broker落后原Leader太多,那么成为新Leader必然会造成消息丢失。因此,要将unclean.leader.election.enable参数设置成false。
(5)设置Broker端参数replication.factor >= 3,将消息保存多份副本。
(6)设置Broker参数min.insync.replicas > 1,保证ISR中Broker副本的最少个数,在acks=-1时才生效。设置成大于1可以提升消息持久性,生产环境中不能使用默认值 1。
(7)必须确保replication.factor > min.insync.replicas,如果两者相等,那么只要有一个副本挂机,整个分区无法正常工作。推荐设置成replication.factor = min.insync.replicas + 1。
(8)确保消息消费完成再提交。设置Consumer端参数enable.auto.commit为false,并采用手动提交位移的方式。
生产者向Kafka发送消息时,可以选择需要的可靠性级别。通过request.required.acks参数值可以设置可靠性级别。
0值:异步发送。生产者向Kafka发送消息而不需要Kafka反馈成功 ACK,效率最高,可靠性最低。可能会存在消息丢失的情况:在传输过程中会出现消息丢失;在Broker内部会出现消息丢失;会出现写入到Kafka中的消息的顺序与生产顺序不一致的情况。
1值:同步发送。生产者发送消息给Kafka,Broker的Partition Leader在收到消息后马上发送成功ACK(无需等待ISR中的Follower同步),生产者收到后知道消息发送成功,然后会再发送消息。如果一直未收到Kafka的ACK,则生产者会认为消息发送失败,会重发消息。
如果没有收到ACK,一定可以确认消息发送失败,然后可以重发;但即使收到ACK,也不能保证消息一定就发送成功。
-1值:同步发送。生产者发送消息给Kafka,Kafka Broker收到消息后要等到ISR列表中的所有Follower都同步完消息后,才向生产者发送成功ACK。如果一直未收到Kafka的ACK,则认为消息发送失败,会自动重发消息,会出现消息重复接收的情况。
拦截器基本思想是允许应用程序在不修改逻辑的情况下,动态地实现一组可插拔的事件处理逻辑链,能够在主要业务操作的前后多个时间点上插入对应的拦截逻辑。
Kafka 0.10.0.0版本开始引入拦截器,Kafka拦截器分为生产者拦截器和消费者拦截器。生产者拦截器允许在发送消息前以及消息提交成功后插入拦截器逻辑;而消费者拦截器支持在消费消息前以及提交位移后编写特定逻辑。Kafka拦截器支持链的方式,即可以将一组拦截器串连成一个大的拦截器,Kafka会按照添加顺序依次执行拦截器逻辑。
假设要在生产消息前执行两个前置动作:一个是为消息增加一个头信息,封装发送消息的时间,一个是更新发送消息数字段。将两个拦截器串联在一起统一指定给Producer后,Producer会按顺序执行两个前置动作,然后再发送消息。
Kafka拦截器设置是通过参数配置的,生产者和消费者两端有一个相同的参数,名字叫interceptor.classes,指定的是一组类的列表,每个类就是特定逻辑的拦截器实现类,指定拦截器类时需要指定全限定名,即 full qualified name。
Producer端拦截器实现类都要继承org.apache.kafka.clients.producer.ProducerInterceptor接口。ProducerInterceptor接口有两个核心的方法:
onSend:在消息发送前被调用。
onAcknowledgement:在消息成功提交或发送失败后被调用。onAcknowledgement 调用要早于发送回调通知callback的调用。onAcknowledgement与onSend 方法不是在同一个线程中被调用,因此如果两个方法中使用了某个共享可变对象,要保证线程安全。
假设第一个拦截器的完整类路径是com.yourcompany.kafkaproject.interceptors.AddTimeStampInterceptor,第二个拦截器是com.yourcompany.kafkaproject.interceptors.UpdateCounterInterceptor,Producer指定拦截器的Java代码示例如下:
Properties props = new Properties();
List<String> interceptors = new ArrayList<>();
interceptors.add("com.yourcompany.kafkaproject.interceptors.AddTimestampInterceptor"); // 拦截器1
interceptors.add("com.yourcompany.kafkaproject.interceptors.UpdateCounterInterceptor"); // 拦截器2
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);Consumer拦截器的实现类要实现org.apache.kafka.clients.consumer.ConsumerInterceptor接口,ConsumerInterceptor有两个核心方法。
onConsume:在消息返回给Consumer程序前调用。在开始正式处理消息前,拦截器会先做一些处理,再返回给Consumer。
onCommit:Consumer在提交位移后调用,可以进行一些打日志操作等。
Kafka拦截器可以应用于包括客户端监控、端到端系统性能检测、消息审计等多种功能在内的场景。
Kafka默认提供的监控指标是针对单个客户端或Broker的,很难从具体的消息维度去追踪集群间消息的流转路径。同时,如何监控一条消息从生产到最后消费的端到端延时是很多Kafka用户迫切需要解决的问题。但在应用代码中编写统一的监控逻辑会增加复杂度,并且将监控逻辑与主业务逻辑耦合也是软件工程中不提倡的做法。通过实现拦截器的逻辑以及可插拔的机制,能够快速地检测、验证以及监控集群间的客户端性能指标,特别是能够从具体的消息层面上收集性能指标数据。
对于消息审计(message audit),如果把Kafka作为一个私有云消息引擎平台向全公司提供服务,会涉及多租户以及消息审计的功能。作为私有云的PaaS提供方,需要要能够随时查看每条消息是哪个业务方在什么时间发布的,被哪些业务方在什么时刻消费。可以通过在拦截器内实现相应的消息审计逻辑,强行规定所有接入Kafka服务的客户端程序必须设置消息审计拦截器。
Kafka 0.10.1.0版本开始,Kafka Consumer采用双线程设计,即用户主线程和心跳线程。用户主线程是启动Consumer应用程序main方法的线程,而新引入的心跳线程(Heartbeat Thread)只负责定期给对应的Broker机器发送心跳请求,以标识消费者应用的存活性(liveness)。心跳线程的引入将心跳频率与主线程调用KafkaConsumer.poll方法的频率分开,从而解耦真实的消息处理逻辑与消费者组成员存活性管理。但由于消息获取逻辑依然是在用户主线程中完成的,因此,依然可以安全地认为Kafka Consumer是单线程设计。
KafkaConsumer类不是线程安全的 (thread-safe)。所有的网络IO处理都在用户主线程中,在使用过程中必须要确保线程安全。不能在多个线程中共享同一个KafkaConsumer实例,否则程序会抛出ConcurrentModificationException异常。KafkaConsumer的wakeup()方法是线程安全的,可以在其他线程中安全地调用KafkaConsumer.wakeup()来唤醒 Consumer。
消费者程序启动多个线程,每个线程维护专属的Kafka Consumer实例,负责完整的消息获取、消息处理流程。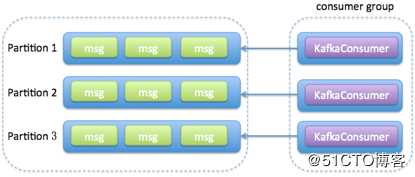
优点:
(1)实现简单,使用多个线程并在每个线程中创建专属的KafkaConsumer实例即可。
(2)多个线程间没有任何交互,不用考虑线程安全开销。
(3)每个线程使用专属的Kafka Consumer实例来执行消息获取和消息处理逻辑,因此,Kafka主题中的每个分区都能保证只被一个线程处理,很容易实现分区内的消息消费顺序。
缺点:
每个线程都需要维护自己的KafkaConsumer实例,必然会占用更多的系统资源,比如内存、TCP连接等。
可以使用的线程数受限于Consumer订阅主题的总分区数,在一个消费者组中,每个订阅分区都只能被组内的一个消费者实例所消费。
每个线程需要完整地执行消息获取和消息处理逻辑,如果消息处理逻辑很重,造成消息处理速度慢,容易产生不必要的Rebalance,从而引发整个消费者组的消费停滞。
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records =
consumer.poll(Duration.ofMillis(10000));
// 执行消息处理逻辑
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}消费者程序使用单或多线程获取消息,同时创建多个消费线程执行消息处理逻辑。获取消息的线程可以是单线程,也可以是多线程,每个线程维护专属的Kafka Consumer实例,处理消息则交由特定的线程池处理,从而实现消息获取与消息处理的真正解耦。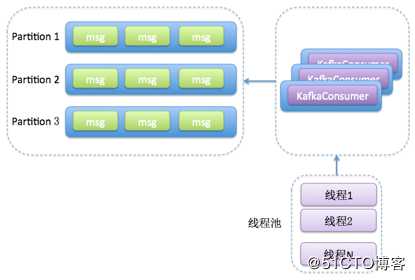
优点:
提高系统伸缩性。将任务切分成消息获取和消息处理两个部分,分别由不同的线程处理,可以独立地调节消息获取的线程数以及消息处理的线程数,而不必考虑两者之间是否相互影响。如果消费获取速度慢,那么增加消费获取的线程数即可;如果消息的处理速度慢,那么增加Worker线程池线程数即可。
缺点:
实现难度要大,需要分别管理两组线程。
无法保证分区内的消费顺序。由于使用两组线程,消息获取可以保证分区内的消费顺序,但消息处理时Worker线程池将无法保证分区内的消费顺序。
使用两组线程,使得整个消息消费链路被拉长,最终导致正确位移提交会变得异常困难,可能会出现消息的重复消费。
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
...
private int workerNum = ...;
executors = new ThreadPoolExecutor(
workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
...
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (final ConsumerRecord record : records) {
executors.submit(new Worker(record));
}
}
..Kafka Consumer消费的滞后程度(Consumer Lag)是指消费者当前落后于生产者的程度。
Lag的单位是消息数,Kafka监控Lag的层级是在分区上的。Lag直接反映消费者的运行情况,正常工作的消费者,Lag值应该很小,甚至是接近于0的,表示消费者能够及时地消费生产者生产出来的消息,滞后程度很小。如果消费者Lag值很大,表明无法跟上生产者的速度,最终Lag会越来越大,从而拖慢下游消息的处理速度。
Kafka监控消费者进有3种方法:
(1)使用Kafka自带的命令行工具kafka-consumer-groups脚本。
(2)使用Kafka Java Consumer API编程。
(3)使用Kafka自带的JMX监控指标。
kafka-consumer-groups脚本是Kafka提供的最直接的监控消费者消费进度的工具,也能够监控独立消费者(Standalone Consumer)的Lag。kafka-consumer-groups.sh --bootstrap-server <Kafka broker> --describe --group <group id>
kafka-consumer-groups脚本的输出信息会按照消费者组订阅主题的分区进行展示,每个分区一行数据;其次,除了主题、分区等信息外,会汇报每个分区当前最新生产的消息的位移值(即LOG-END-OFFSET 列值)、该消费者组当前最新消费消息的位移值(即 CURRENT-OFFSET 值)、LAG 值(前两者的差值)、消费者实例 ID、消费者连接 Broker 的主机名以及消费者的 CLIENT-ID 信息。
Kafka 2.0.0版本开始,Kafka Consumer API分别提供了查询当前分区最新消息位移和消费者组最新消费消息位移两组方法,可以用于计算消费者的Lag。
public static Map<TopicPartition, Long> lagOf(String groupID, String bootstrapServers) throws TimeoutException {
Properties props = new Properties();
props.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
try (AdminClient client = AdminClient.create(props)) {
ListConsumerGroupOffsetsResult result = client.listConsumerGroupOffsets(groupID);
try {
Map<TopicPartition, OffsetAndMetadata> consumedOffsets = result.partitionsToOffsetAndMetadata().get(10, TimeUnit.SECONDS);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 禁止自动提交位移
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
try (final KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
Map<TopicPartition, Long> endOffsets = consumer.endOffsets(consumedOffsets.keySet());
return endOffsets.entrySet().stream().collect(Collectors.toMap(entry -> entry.getKey(),
entry -> entry.getValue() - consumedOffsets.get(entry.getKey()).offset()));
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
// 处理中断异常
// ...
return Collections.emptyMap();
} catch (ExecutionException e) {
// 处理ExecutionException
// ...
return Collections.emptyMap();
} catch (TimeoutException e) {
throw new TimeoutException("Timed out when getting lag for consumer group " + groupID);
}
}
}Kafka默认提供的JMX监控指标可以监控消费者的Lag值。Kafka Consumer提供了一个名为kafka.consumer:type=consumer-fetch-manager-metrics,client-id=“{client-id}”的JMX指标,其中属性records-lag-max和records-lead-min分别表示消费者在测试窗口时间内曾经达到的最大的Lag值和最小的Lead值。Lead值是指消费者最新消费消息的位移与分区当前第一条消息位移的差值。
Apache Kafka采用TCP协议作为所有请求通信的底层协议。
Kafka的Java生产者API主要的对象就是KafkaProducer,开发Kafka生产者的流程如下:
(1)构造生产者对象所需的参数对象。
(2)利用构造的参数对象,创建KafkaProducer对象实例。
(3)使用KafkaProducer的send方法发送消息。
(4)调用KafkaProducer的close方法关闭生产者并释放各种系统资源。
在创建KafkaProducer实例时,生产者应用会在后台创建并启动一个名为Sender的线程,Sender线程开始运行时首先会创建与Broker的连接。Java Producer的Sender线程会连接bootstrap.servers参数指定的所有Broker,因此生产环境中中,建议在bootstrap.servers参数中指定3~4台Broker即可。
当Producer更新了集群的元数据信息后,如果发现与某些Broker当前没有连接,Producer就会创建一个TCP连接。当要发送消息时,Producer发现不存在与目标Broker的连接,会创建一个TCP连接。
当Producer尝试给一个不存在的Topic发送消息时,Broker会告诉Producer相关Topic不存在,此时Producer会发送METADATA请求给Kafka集群,尝试获取最新的元数据信息;Producer通过指定metadata.max.age.ms参数定期地更新元数据信息,参数默认值是300000,即5分钟,即Producer每5分钟都会强制刷新一次元数据以保证是最新的数据。Producer默认会向集群的所有Broker都创建TCP连接,不管是否真的需要传输请求。
Producer关闭TCP连接的方式有两种:一种是用户主动关闭,一种是Kafka自动关闭。Kafka自动关闭与Producer端参数connections.max.idle.ms值有关,默认参数值是9分钟,即如果在9分钟内某个TCP 连接没有任何请求,Kafka会主动把TCP连接关闭。用户可以在Producer端设置connections.max.idle.ms=-1,TCP连接将成为永久长连接。Kafka创建的Socket连接都开启keepalive,因此keepalive探活机制会遵守。对于被Broker端被关闭的TCP连接,由于TCP连接的发起方是客户端,属于被动关闭,即 passive close。被动关闭的后果就是会产生大量的CLOSE_WAIT连接,因此Producer端或Client端怒会显式地检测到TCP连接已被中断
消费者端主要的程序入口是KafkaConsumer类,构建KafkaConsumer实例时不会创建任何TCP连接。TCP连接是在调用KafkaConsumer.poll方法时被创建,三种时机创建。
(1)发起FindCoordinator请求时。
消费者端Coordinator驻留在Broker端的内存中,负责消费者组的组成员管理和各个消费者的位移提交管理。当消费者程序首次启动调用poll方法时,会向Kafka集群中当前负载最小的Broker发送一个名为FindCoordinator的请求,获取其Coordinator所在的Broker。负载的评估是看消费者连接的所有Broker中,谁的待发送请求最少,是消费者端的单向评估。
(2)连接Coordinator时。Broker处理完FindCoordinator请求后,会返回对应的响应结果(Response),显式地告诉消费者哪个Broker是其Coordinator。消费者会创建连向Coordinator所在Broker的Socket连接。
(3)消费数据时。消费者会为每个要消费的分区创建与分区Leader副本所在Broker连接的TCP连接。
消费者关闭Socket分为主动关闭和Kafka自动关闭。主动关闭是指显式地调用消费者KafkaConsumer.close()方法关闭消费者;而Kafka自动关闭是由消费者端参数connection.max.idle.ms控制,参数默认值是9分钟,即如果某个Socket连接上连续9分钟都没有任何请求,那么消费者会强行关闭Socket连接。如果在编写消费者程序时,使用循环的方式来调用poll方法消费消息,那么上面提到的所有请求都会被定期发送到Broker,因此Socket连接上总是能保证有请求在发送,从而实现了长连接效果。
当实际消费数据的TCP连接成功创建后,消费者程序就会废弃获取集群元数据的TCP连接,再定期请求元数据时,会改为使用实际消费数据的TCP连接。因此,获取集群元数据的TCP连接会在后台被自动关闭掉。
生产者将消息发送到Topic中,消费者即可对其进行消费,其消费过程如下:
(1)Consumer向Broker提交连接请求,其所连接上的Broker都会向其发送Broker Controller的通信URL,即配置文件中的listeners地址;
(2)当Consumer指定了要消费的Topic后,会向Broker Controller发送消费请求;
(3)Broker Controller会为Consumer分配一个或几个Partition Leader,并将Partition的当前offset发送给Consumer;
(4)Consumer会按照Broker Controller分配的Partition对其中的消息进行消费;
(5)当Consumer消费完消息后,Consumer会向Broker发送一个消息已经被消费反馈,即消息的offset;
(6)在Broker接收到Consumer的offset后,会更新相应的__consumer_offset中;
Consumer可以重置offset,从而可以灵活消费存储在Broker上的消息。
(1)同一个Consumer重复消费
当Consumer由于消费能力低而引发了消费超时,则可能会形成重复消费。
在某数据刚好消费完毕,但正准备提交offset时,消费时间超时,则Broker认为消息未消费成功,产生重复消费问题。
其解决方案:延长offset提交时间。
(2)不同的Consumer重复消费
当Consumer消费了消息,但还没有提交offset时宕机,则已经被消费过的消息会被重复消费。
其解决方案:将自动提交改为手动提交。
(1)保存并查询
给每个消息都设置一个唯一的UUID,在消费消息时,首先去持久化系统中查询,查看消息是否被消费过,如果没有消费过,再进行消费;如果已经消费过,直接丢弃。
(2)利用幂等性
幂等性操作的特点是任意多次执行所产生的影响均与一次执行的影响相同。
如果将系统消费消息的业务逻辑设计为幂等性操作,就不用担心Kafka消息的重复消费问题,因此可以将消费的业务逻辑设计成具备幂等性的操作。利用数据库的唯一约束可以实现幂等性,如在数据库中建一张表,将表的两个或多个字段联合起来创建一个唯一约束,因此只能存在一条记录。
(3)设置前提条件
实现幂等性的另一种方式是给数据变更设置一个前置条件。如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。
标签:消息 行数据 called 消费 mod 元数据 intercept 操作 long
原文地址:https://blog.51cto.com/9291927/2497828