标签:equal 做了 结果 scan 不同的 lex dbscan ted 百度
上周需要改一个降维的模型,之前的人用的是sklearn里的t-SNE把数据从高维降到了二维。我大概看了下算法的原理,和isomap有点类似,和dbscan也有点类似。不过这里就不详细讲了,这里说最重要的perplexity参数应该怎么调。
百度了一些文章,都说5-50就行。人云亦云,一个地方抄另外一个地方。perplexity的原本定义是“expected density”,也就是说预估每个cluster可能有多少个元素,有点类似dbscan里的min_sample。
这里有一个可以玩的网站,试试t-sne在不同的参数下跑的结果怎么样。
https://distill.pub/2016/misread-tsne/
作者自己做了实验,每个cluster有50个点的情况下,看不同的perplexity会有什么结果。
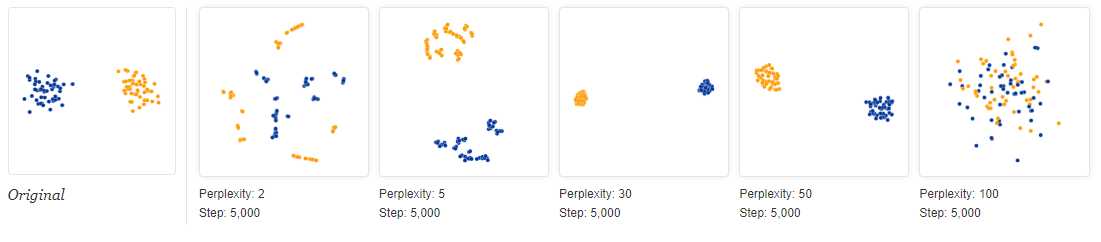
你也可以自己尝试,就是选第二个实验,“Two clusters with equal numbers of points.”,然后我自己参数point per cluster是20,然后perplexity选了40。最后无法收敛。所以你大概也能猜来这个参数到底应该选什么了,文章里也说了,应该要比point per cluster小。
文章里也讨论了t-sne的其他特性和表现。这里就不再阐述了,有兴趣的可以看看。

标签:equal 做了 结果 scan 不同的 lex dbscan ted 百度
原文地址:https://www.cnblogs.com/symbiosis/p/12953155.html