标签:解决 利用 hash表 没有 笔记 capacity img jdk 特点
????相信HashMap对于大家来说并不陌生,下面主要从HashMap的一些常见面试题来剖析,结合面试题和HashMap的一些源码来讲解,并不会一上来就一点一点源码去讲,相信大家一直对照着源码去讲解收获也不是很大,并且容易忘记。
????我们都知道HashMap是基于hash表实现的,而hash表底层是由数组加链表实现的。相信大家这个都能回答上来,我们不仅要知道是由数组加链表组成,还需要明白什么由数组加链表组成。知其然知其所以然。我们来看一下HashMap的源码:
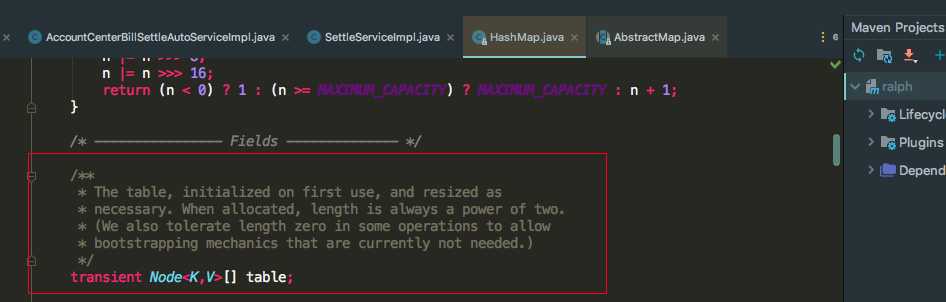
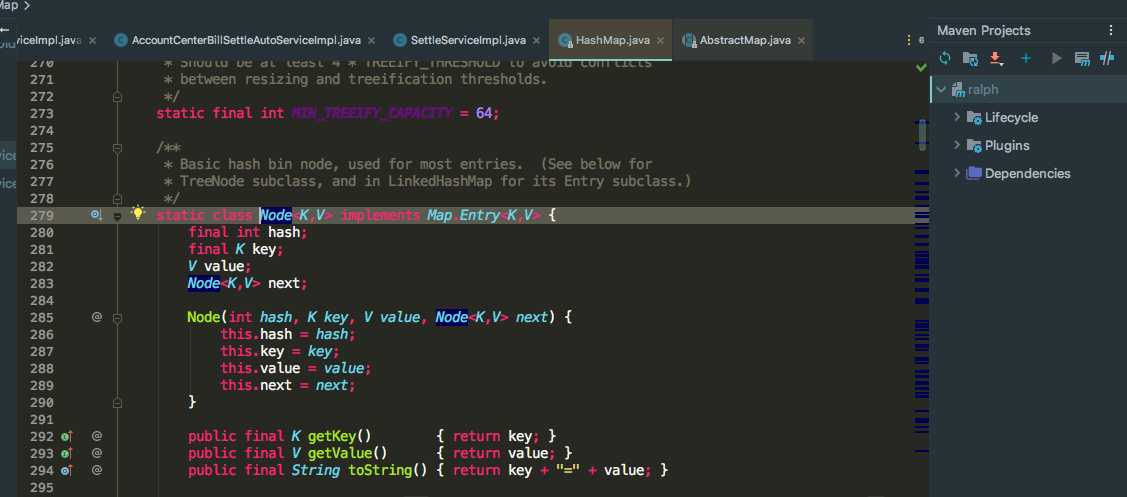
我们可以看到有一个Node[] table数组对象,而Node对象有next指针指向下一个对象组成链表。
????我们知道数组和链表各自的特点:
???????数组:具有随机访问的特点,能达到O(1)的时间复杂度,但是插入和删除比较麻烦,需要移动数组的元素位置
????????链表:链表跟数组恰恰相反,插入和删除不需要移动位置,只需要改变next指针指向的对象引用。但是链表的时间复杂度达到O(n),只能顺着节点依次的找下去
我们现在想一下,既然链表的时间复杂度达到O(n),为什么HashMap还需要加入链表了?假设一个场景:如果两个key被hash(key)成同一个数组下标i,这时数组下标i的位置只能保存一个元素,这时链表就发挥作用了,加入链表用来解决hash冲突,两个key会用链表next进行链接起来。当所有key被链接成一个链表时,而每次查找只能从第一个Node节点开始寻找,查找的效率就会低下,JDK1.8后对此引入了红黑树数据结构来解决这个问题,后面再详细介绍红黑树
????我们知道在HashMap中有个默认的DEFAULT_LOAD_FACTOR负载因子=0.75,0.75也并不是随便进行设置的。0.75的含义表达当HashMap的容量达到总容量的75%时HashMap会进行扩容。那HashMap的负载因子为什么要设置0.75呢?是有原因的,主要是从hash冲突和空间利用率两个方面来考量的
????我们假设一下,如果我们将负载因子设置成1,会发生什么情况:
???????我们将HashMap的负载因子设置成1也就是HashMap的容量必须要全部装满,才允许扩容,HashMap的容量如果要全部装满必定会伴随着大量的hash冲突,这时候put和get操作效率就会低下。
????如果我们将负载因子设置成0.5,会发生什么情况:
????????这时HashMap的容量达到50%时就会进行扩容,这样虽然能减少hash冲突的概率,但是会存在还有一半的空间没有被使用到,会造成空间的利用率低下。
????这时1和0.5都不行,难道我们随便取个中间值可以吗。显然不是的,而是根据一个数学公式推导出来的,被叫做牛顿二项式。下面摘自StackOverFlow一个回答,在牛顿二项式公式下算出来的负载因子~0.69

公式算出来为0.693,而0.75是HashMap为了后面方便计算,0.75*size=整数,方便后面HashMap容量达到这个整数进行扩容。
????我们知道每次HashMap resize()时,扩容后都是之前的容量的2倍。这是为什么呢?我们先来看一段HashMap的源码
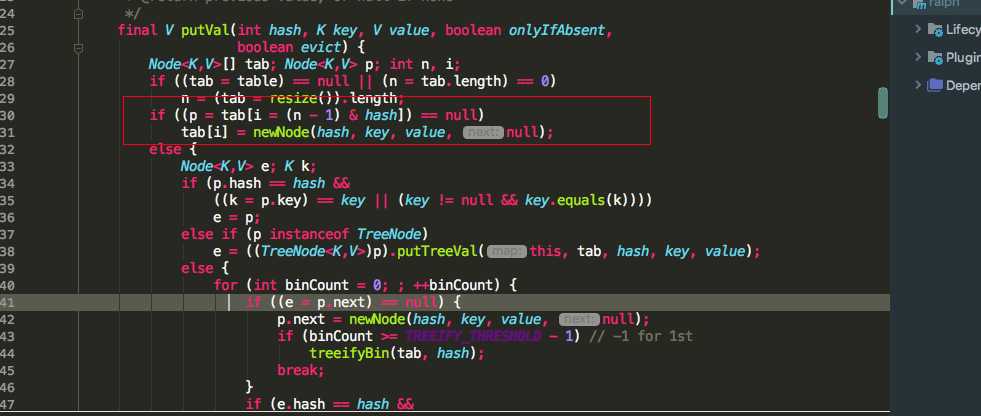
我们可以看到putVal时,会去判断table[i]的值为不为空,而数组下标i是怎么得出来的呢,是通过key的hash值&(n - 1)得到的数组下标i,n代表数组的长度。在这里提另外一点,我们都知道数组下标i的值可以由hash%length(数组长度)得到,但是HashMap为什么没有采用这种方式了,而是采用hash&(length - 1)这种方式。&运算速度是要高于%运算速度的,不信的话,网友可以去尝试一下。
????我们假设一下如果扩容不是2的指数倍,假设数组长度是10,则(n - 1)的二进制是01001,就会存在这样的情况
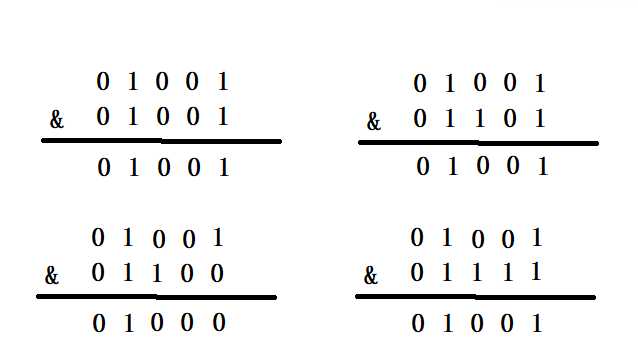
01001代表的是(n - 1)的二进制数,而下面&上的二进制数01001,01101,01100 ,01111代表的是hash的二进制数,我们发现四个不同的hash值&上(n - 1)却出现了两个01001两个相同的结果,也就是会同时对应一个数组下标i,这时就会造成hash冲突了。
????我们假设一下扩容是2的指数倍,则n就会是2,4,8,16,32,64等这些2的指数倍,(n - 1)就会是1,3,7,15,31等这些数对应的二进制就是00001,00011,00111,01111,11111等这些数。我们再来看下这些二进制数&hash值对应的二进制数
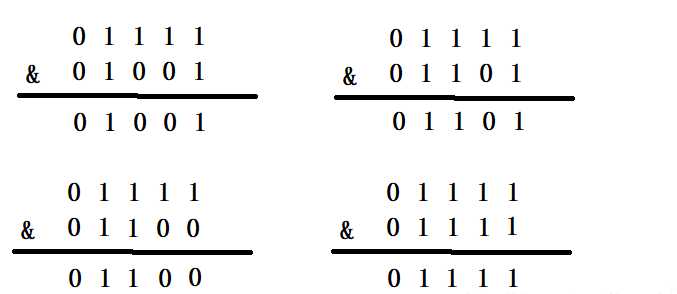
我们发现&出来的结果都是由hash值决定,结果取决于hash值。这时能够更好的减少hash冲突
????我们知道HashMap引入红黑树数据结构是为了解决链表O(n)的时间复杂度,达到一定条件时,链表就会转变红黑树。这里我们可以想一下,为什么HashMap引入的是红黑树,而不是完全平衡二叉树,完全平衡二叉树也可以解决链表O(n)的时间复杂度。
????这里就不概述红黑树和完全平衡二叉树的定义了,红黑树是一种相对平衡的二叉树,而完全平衡二叉树则是绝对平衡的。假设HashMap引入完全平衡二叉树,每当key插入进来时,完全平衡二叉树为了保持绝对的平衡,就会对树进行左旋,右旋操作来保持树的绝对平衡。这时插入的效率就会低下。而红黑树只需保持相对的平衡,并不会有过多的旋转操作,来使插入效率降低。完全平衡二叉树适合读多写少的场景,也就是get操作多,而put操作少。这时完全平衡二叉树的效率就会比红黑树的效率要高
????我们首先来看一段HashMap的一段源码注释
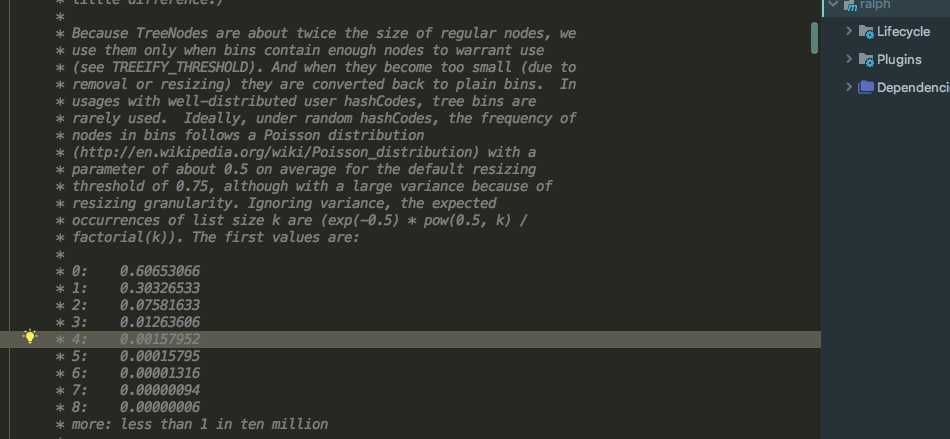
大概意思就是在负载因子为0.75的基础上,链表长度达到8个元素的概率为0.00000006,这个概率几乎很小了,这个概率是怎么算出来的呢,是通过一个叫泊松分布概率统计得出来的。并不是随随便便定义的这个数字。
????在HashMap中有一个转变成红黑树的阀值TREEIFY_THRESHOLD=8,看一段HashMap的源代码:
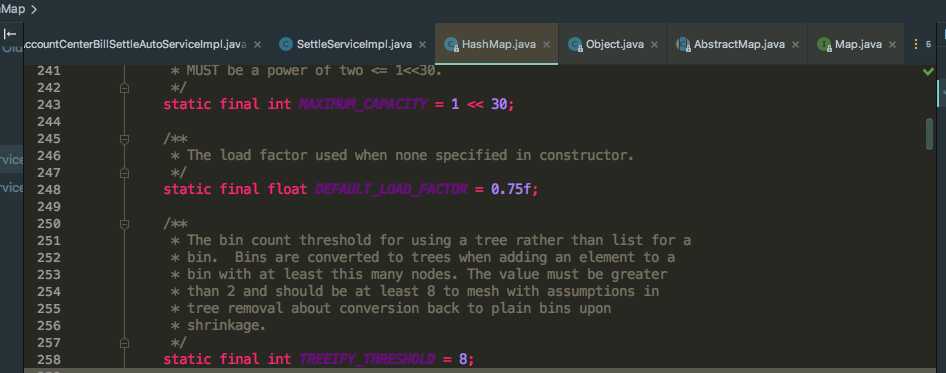
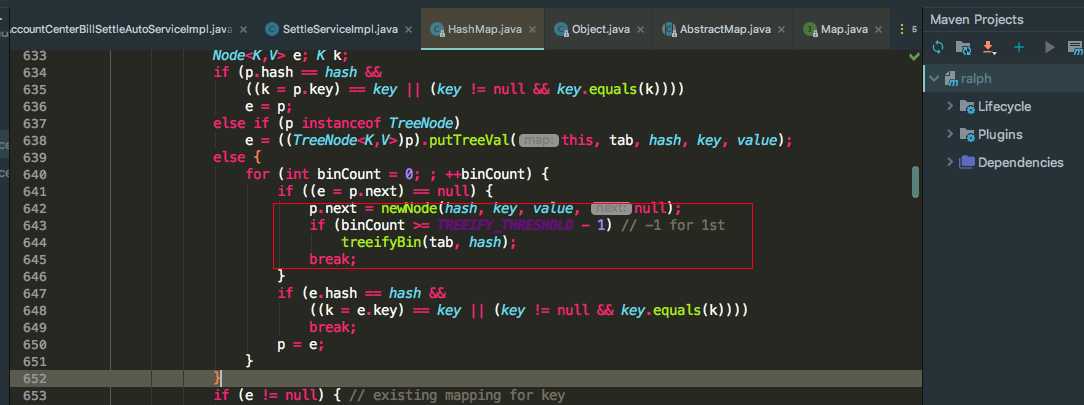
我们可以看到当binCount达到(TREEIFY_THRESHOLD - 1)时,便会执行treeifyBin()方法,因为binCount是从0开始的,所以会是8个节点。刚达到8个节点时,真的会转变成红黑树吗?我们再看一下treeifyBin()方法里面
我们可以看到如果tab.length 如果小于MIN_TREEIFY_CAPACITY = 64时,HashMap并不会中的链表并不会转变成红黑树,而是进行resize()扩容方法。所以可以得出转变成红黑树必须满足两个条件:
????(1):链表节点必须达到8个
????(2):数组tab的长度必须大于等于64
???我相信这种场景在线上是很难出现的,但是也不排除这个可能不会出现,在JDK1.8之前HashMap确实会导致CPU飙升,但是JDK1.8之后官方修复了这个问题。之前为什么会导致CPU飙升了,因为HashMap中的链表可能会出现环形链表,从而导致死循环。下面来分析一下HashMap中的环形链表的形成
????我们都知道当HashMap扩容时,需要将旧的数组重新hash填充到新的数组中,当扩容时,存在多个线程一起rehash,这时可能就会出现环形链表
假设初始时HashMap是这样的:
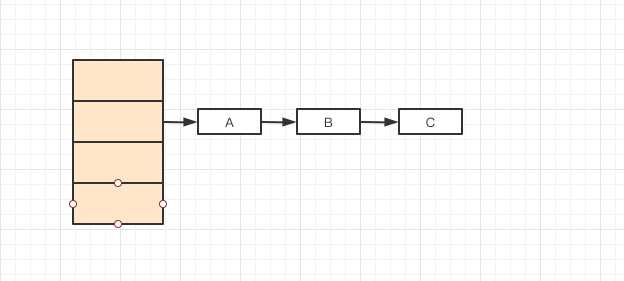
这时经过扩容,需要将A,B,C三个值重新hash到新的数组中
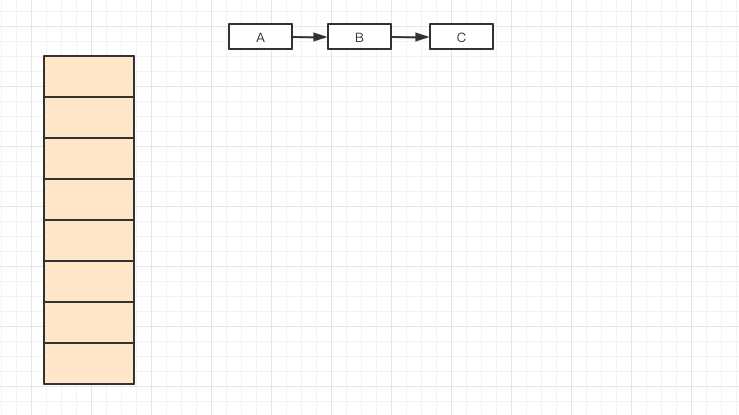
这时假设有两个线程A,B同时进行扩容操作
线程A进行扩容时,指针情况:
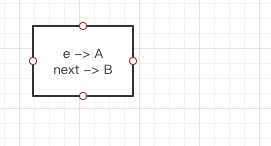
线程B进行扩容时,指针情况:
线程A正准备将指针e的值插入到新的数组中,发现CPU的时间片被抢占,以至于线程A被阻塞,指针情况还是:
这时线程B拿到时间片,进行插入操作,将指针e插入到新的数组中:
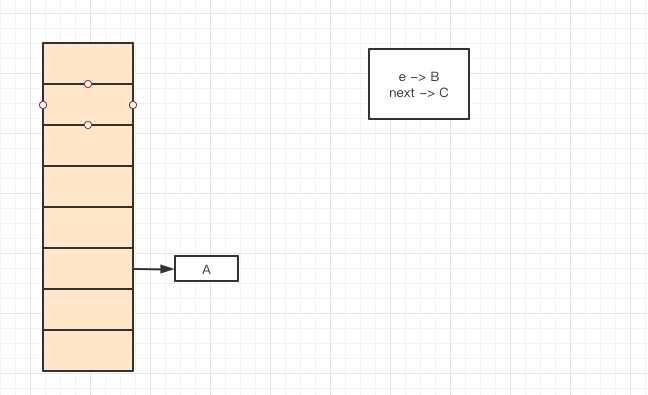
这时指针e就会变成指向B对象,这时又将e插入到新数组中:
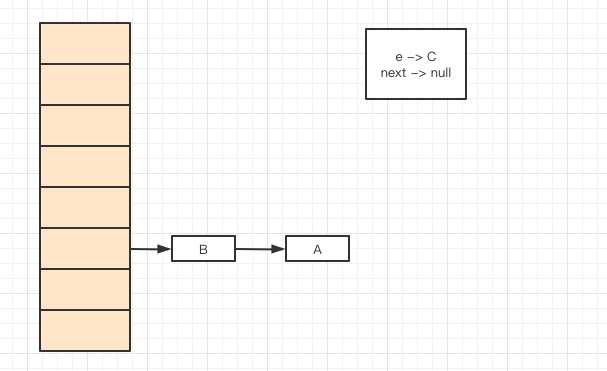
因为JDK1.8之前是采用头插法进行插入,B就会插入到A的前面,这时正准备插入最后一个元素C,当时时间片被抢占,轮到线程A执行。这时线程A去插入指针e,也就是元素A.
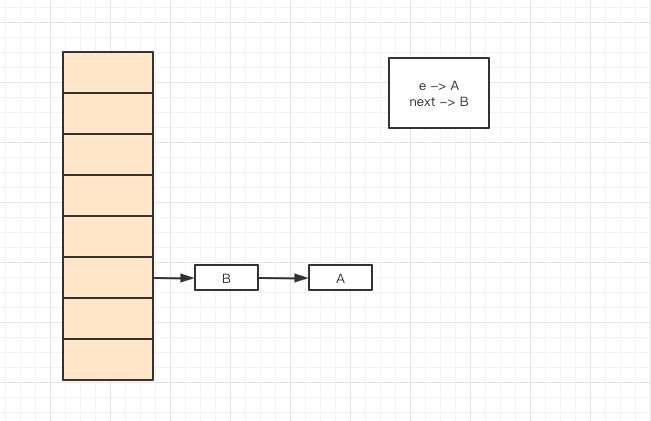
当插入元素A时,会插入到元素B的前面,也就是A的next = B
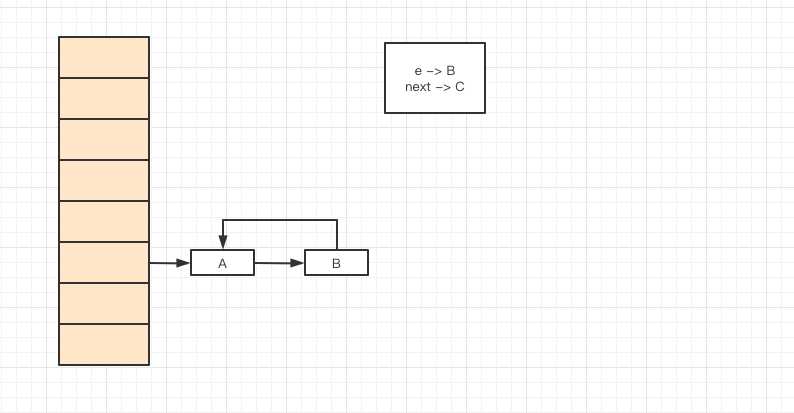
这时就是演变成A 和 B形成了一个环形链表,因为B之前的next指针是指向A元素的。
????因为JDK1.8之前是采用头插法进行插入的,也就是旧数组之前链表元素插入到新数组后顺序是颠倒过来的。后面JDK1.8之后官方采用尾插法进行插入,保证插入后的元素顺序跟插入前的顺序是一样的。
????HashMap应该是面试中必问的一道面试题,前面总结的都是常被问到的,自己也做一些笔记。当是自己发现有些公司不再问到了HashMap,反而更倾向于线程安全的ConcurrentHashMap。可能是HashMap的面试题都被大家背熟了,有些公司都干脆不问了。哈哈哈!
标签:解决 利用 hash表 没有 笔记 capacity img jdk 特点
原文地址:https://www.cnblogs.com/semi-sub/p/12953414.html