标签:数据存储 内存 维护 概念 mysql 空间 HERE 存储器 第一步
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等。
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。
最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。
但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。
但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,
每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,
因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。
具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
哈希表是一种以键-值(key-value)的方式存储数据的结构,只要输入待查找的值(即key),就可以找到其对应的值(即Value)。
哈希的思路很简单,把值放在数组里,用一个哈希函数把key换算成一个确定的位置,然后把value放在数组的这个位置,即idx = Hash(key)。如果出现哈希冲突,就采用拉链法解决。
因为哈希表中存放的数据不是有序的,因此不适合做区间查询,适用于只有等值查询的场景。
哈希表的缺点:因为节点的数据容易出现重合,查询数据还需要拿到真实的数据做对比,效率会变低。并且也不适合做范围查询。
采用二叉树做为索引的数据结构。
二叉树是一颗相对平衡的有序二叉树,对其进行插入,查找,删除等操作性能都比较好。
特点:它的左子节点的值比父节点的值要小,右节点的值要比父节点的大。
二叉树的优点:可以优化磁盘IO的次数。节点存在有顺序,可以进行范围的查询。
二叉树的缺点:插入数据的速度会比较慢,因为会更改数据结构。不平衡的问题,会产生倾斜的二叉树。
插入数据会平衡,但是插入的时候会改变树的结构。插入的数据的时候比较慢。而且树的层级会变高,会增加磁盘IO的次数。
二叉树是有顺序的,范围查找都是支持的。
B树或者B+树的节点可以存储多个数据,所以相对于完全平衡二叉树的高度肯定会低,那么就会降低磁盘IO的次数。
B+树相对于B树有数据的冗余,叶子节点中的数据是有顺序的。那么再进行顺序查找的时候就非常的方便,只要在叶子节点顺序向后遍历即可。
索引在起初做设计的时候其实是有一定数据结构选型的,
(1)使用二叉树作为索引结构缺陷
容易导致二叉树出现结构偏移,极端情况容易变成一条链表的形状。
(2)使用红黑树数据结构的缺陷
红黑树虽然有自动进行树节点的二叉平衡功能。虽然相对于二叉树而言,不会有太严重的单边偏移情况,但还是避免不了极端情况下树的重心出现偏移的现象。
(数据量变大的情况下,深度会变大)使用红黑树数据结构容易在极端的情况下发生红黑树失重情况,如下图所示,随着数据量的增大,失重情况愈发严重。
(3)hash索引的缺陷
虽然说hash查询的速度很快,但是依然有以下缺陷:
a.无法解决查询范围导致的问题。
b.无法解决hash冲突的问题。
Mysql对于不同的存储引擎,索引的实现实现方式是不同的。主流的存储引擎:MyISAM和InnoDB,两种存储引擎都使用B+Tree(B-Tree的变种)作为索引结构,但是在实现方式上,却有很大的不同。
这里的 B 是 Balance 的意思。
B-Tree结构:
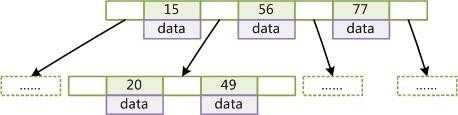
B-Tree无论是叶子结点还是非叶子结点,都含有key和一个指向数据的指针,只要找到某个节点后,就可以根据指针找到磁盘地址从而找到数据。
B+Tree结构:
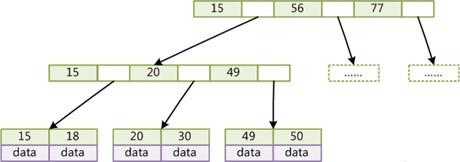
B+Tree所有叶子结点才有指向数据的指针。非叶子结点就是纯索引数据和主键。每个叶子结点都有指向下一个叶子结点的链接。
总结:
非叶子结点存放在内存中,也叫内结点,因此,在有限的内存中, B-Tree中每个数据的指针会带来额外的内存占用,减少了放入内存的非叶子结点数;B+Tree则尽可能多地将非叶子结点放入内存中。
由于B+Tree数据结构的优势,目前mysql基本都采用B+Tree方式实现索引。
B+Tree的性质:
(1)索引字段要尽量的小:
我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;
而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。
这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。
这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
(2)索引的最左匹配特性(即从左往右匹配):
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的。
比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;
但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。
比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了,
这个是非常重要的性质,即索引的最左匹配特性。
下面列出了两个最常用的存储引擎的索引实现:
MyISAM 引擎使用 B+Tree 作为索引结构,叶节点的 data 域存放的是数据记录的地址。
如下图,叶子结点的data域存放的是数据的地址:
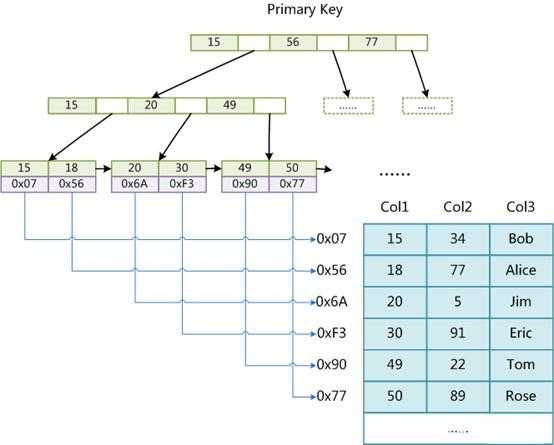
上图表中共三列数据,col1为主键,表示MyISAM表的主索引示意图,在MyISAM中,主索引和辅助索引(除主键以外的其它索引)在结构上没有任何区别,
只是主索引的key是唯一的,辅助索引的key可以重复。MyISAM 的索引方式也叫做“非聚集索引”,之所以这么称呼是为了与 InnoDB的聚集索引区分。
对比MyISAM,InnoDB的主键索引与辅助索引存储方式是不同的:
第一个重大区别是 InnoDB 的数据文件本身就是索引文件。MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
而在InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶点data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
主键索引:主键索引的叶子结点存放的是key值和数据,叶子结点载入内存时,数据一起载入,找到叶子结点的key,就找到了数据。
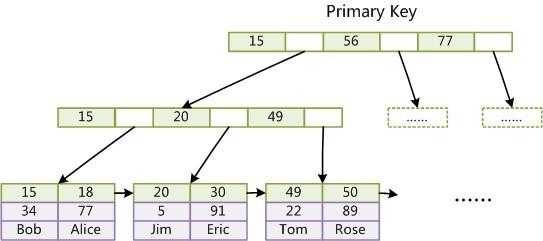
上图是 InnoDB 主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集。
(1)InnoDB 要求表必须有主键(MyISAM 可以没有),如果没有显式指定,则 MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,
如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,类型为长整形。
同时,请尽量在 InnoDB 上采用自增字段做表的主键。因为 InnoDB 数据文件本身是一棵B+Tree,
非单调的主键会造成在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
(2)第二个与 MyISAM 索引的不同是:InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话说,InnoDB 的所有辅助索引都引用主键作为 data 域。
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
引申:为什么不建议使用过长的字段作为主键?
因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
InnoDB 使用的是聚簇索引,将主键组织到一棵 B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照 B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
若对 Name 列进行条件搜索,则需要两个步骤:
第一步在辅助索引 B+树中检索 Name, 到达其叶子节点获取对应的主键。
第二步使用主键在主索引 B+树种再执行一次 B+树检索操作, 最终到达叶子节点即可获取整行数据。
MyISM 使用的是非聚簇索引, 非聚簇索引的两棵 B+树看上去没什么不同, 节点的结构完全一致只是存储的内容不同而已, 主键索引 B+树的节点存储了主键, 辅助键索引B+树存储了辅助键。
表数据存储在独立的地方, 这两颗 B+树的叶子节点都使用一个地址指向真正的表数据, 对于表数据来说, 这两个键没有任何差别。 由于索引树是独立的, 通过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别, 我们假想一个表如下图存储了 4 行数据。 其中Id 作为主索引, Name 作为辅助索引。
MyISAM索引叶子节点存放的是数据的地址,主键索引与辅助索引除了值得唯一性在结构上完全一样。
InnoDB索引叶子节点存放的内容因索引类型不同而不同,主键索引叶子节点存放的是数据本身,辅助索引叶子节点上存放的是主键值。
(1)所有键值分布在整个树中(区别与B+树,B+树的值只分部在叶子节点上);
(2)任何关键字出现且只出现在一个节点中(区别与B+树);
(3)搜索有可能在非叶子节点结束(区别与B+树,因为值都在叶子节点上,只有搜到叶子节点才能拿到值);
(4)在关键字全集内做一次查找,性能逼近二分查找算法;
(1)B+树索引并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
数据的读取是精确到页的,因为页是计算机管理存储器的逻辑块,IO的磁盘读取,每次都读取数据的大小是一个页大小的整数倍。
(2)假设B+Tree的高度为h,一次检索最多需要h-1次I/O(根节点常驻内存),复杂度O(h) = O(logmN),m指的是一个节点存储的数据的个数。
实际应用场景中,M通常较大,常常超过100,因此树的高度一般都比较小,通常不超过3。
(1)所有关键字存储在叶子节点,非叶子节点不存储真正的data;
(2)为所有叶子节点(左右相邻的节点之间)增加了一个链指针;
(1)计算器在IO磁盘读取的时候,为了降低读取的次数,默认一次会读取一个页的数据量,MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改)。
linux 默认页大小为4K。所以每次IO读取,都是读取一个页的数据量,所以B树的节点都是存储一个页的节点,这样的查询效率才是最高的
(2)每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个结点只需一次I/O。这样大大降低了树的高度。
(1)范围查找更快,mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。
而B树的数据有一部分存在在非叶子节点上面,而且默认的B树的相邻的叶子节点之间是没有指针的,所以范围查找相对更慢。
(2)降低树的高度,但是最底下一层的节点会更多,因为所有的数据都堆积在最底下一层了,用空间换速度。
B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。
也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高。
Hash索引的优势是精确查找的话,速度会更快,为什么不选择Hash索引。
(1)Hash索引不适合范围查找,而B+树特别适合范围查找(特别是聚簇索引的时候);
(2)Hash索引每次查询要加载所有的索引数据到内存当中,而B+树只需要根据匹配规则选择对应的叶子数据加载即可;
(3)另外B+树引入了缓存机制 和 数据页技术来提升性能(不过理论上来说,这两个特性Hash索引也可以实现);
(1)插入:和红黑树特别像,新数据插入到一个满了的节点中时,会优先进行左旋右旋,如果邻近的节点都满了的话,会取中间的一个key往上一个层级插入,
直至到Root节点,树的高度的增加,都是通过根节点的拆分来完成的,这保证了所有左右节点的高度差不超过1
(2)删除:会进行调整优化树形结构,使树的数据更分散,以及降低树的高度。比如如果该节点的数据过少,可以从邻近的节点左旋 右旋数据来填充。可能的话,降低一个树的高度。
标签:数据存储 内存 维护 概念 mysql 空间 HERE 存储器 第一步
原文地址:https://www.cnblogs.com/ZJOE80/p/12958269.html