标签:文本特征提取 ble spl https imp module epo dash ted
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0, stratify=y_train)

sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
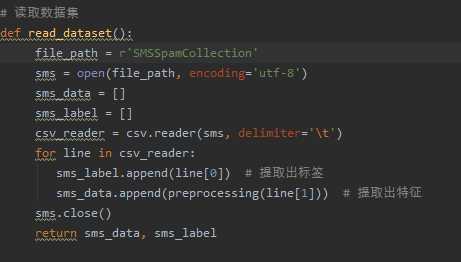
观察邮件与向量的关系
向量还原为邮件
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?

from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
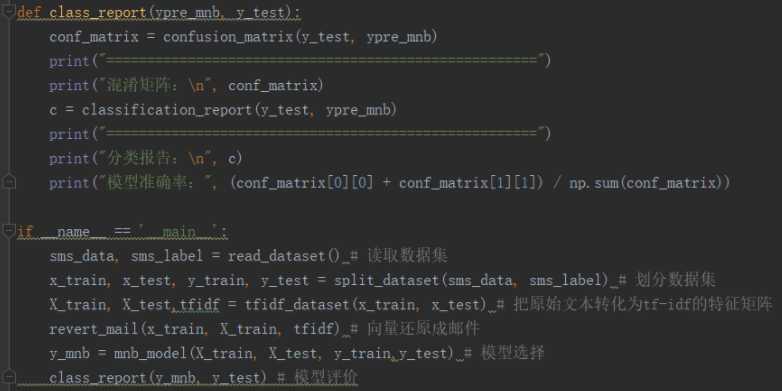
说明混淆矩阵的含义
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
混淆矩阵:
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数误报 (Type I error)
False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)
意义:
准确率:被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。(TP+TN)/总
精确率:表示被分为正例的示例中实际为正例的比例。 TP/(TP+FP)
召回率 :召回率是覆盖面的度量,度量有多个正例被分为正例。TP/(TP+FN)
F值 : 精确率 * 召回率 * 2 / ( 精确率 + 召回率) 。F值就是准确率(P)和召回率(R)的加权调和平均。
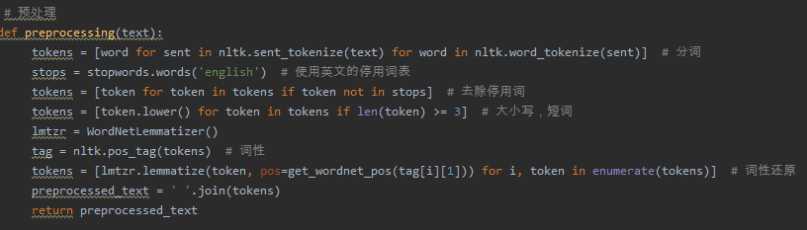
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
CountVectorizer:只考虑词汇在文本中出现的频率,属于词袋模型特征。
TfidfVectorizer: 除了考滤某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量。能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征。属于Tfidf特征。
相比之下,文本条目越多,Tfid的效果会越显著。
标签:文本特征提取 ble spl https imp module epo dash ted
原文地址:https://www.cnblogs.com/LipengC/p/12960265.html