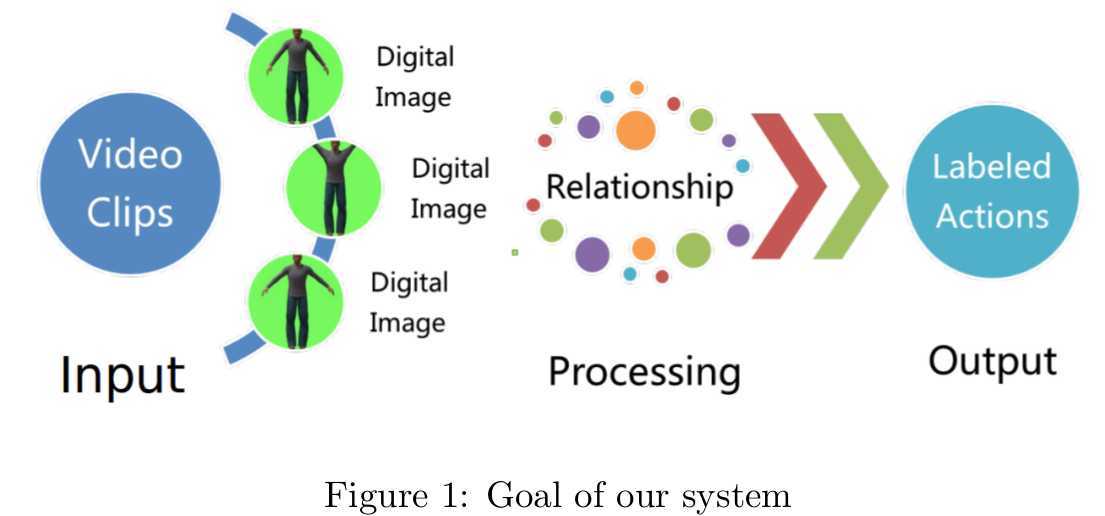
There‘s no doubt that researches and applications on the foundation of videos has become a popular field including intelligence surveillance, interactions between human and machines, content-based video retrieval and so on. However, it‘s also a research direction full of challenges. We want to design and implement a simple system whose responsibility is recognising limited kinds of actions. For example, if we want the system have the ability to recognise actions of walking, running and jumping, when given an unlabelled video containing one of the above actions, the system should tell us which kind of actions it has detected, as shown in Figure 1. For more details about human activity analysis, please refer to [1].
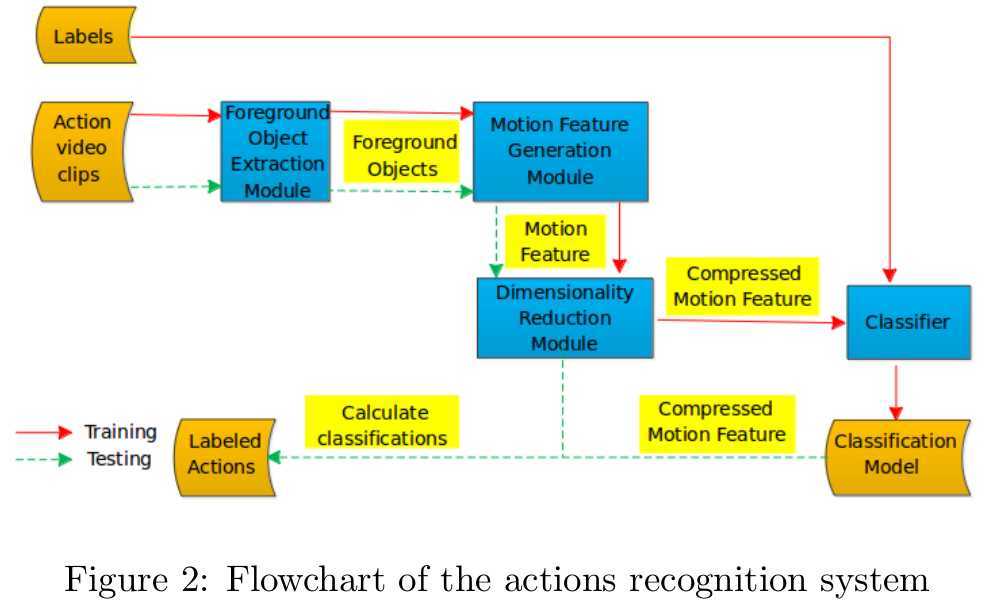
In this section, I provide what we are thinking about while designing this system and give a brief introduction to relevant techniques in each module of the system. The global processing flowchart is shown in Figure 2.
We are interested in the actions in a video,
so the foreground object seems to be more important to us than the background.
We need to figure out a efficient way of foreground object detection and
segmentation from a video stream. Once getting the foreground object in each
frame of a video, we can spare more effort to analyse useful data. An commonly
used approach to extract foreground objects form the image sequence is through
background subtraction when the video is grabbed from a stationary camera
assuming the backgrounds in all the videos are same. But the requirement is too
harsh because our videos may come form any corner in the world having different
backgrounds. We need a method having the property of adapting to the changes of
background more or less. Gaussian Mixture Model(GMM) [7]
and Optical Flow [2] method sare considered as promising
methods.In GMM, each pixel in the scene are modelled by a mixture of
Action feature extraction is the key component in actions recognition systems. If we can take advantage of a method not only describing actions‘ characteristics appropriately, but also magnifying the differences between actions as much as possible, we will make a breakthrough in the relevant fields. Here,the well-known Motion History Image(MHI) [6] is utilized to generate compact, descriptive representations of motion information in the video. MHI compact the whole motion sequence into a single image, which is actually the weighted sum of past foreground objects and the weights decay back through time. Therefore, an MHI image contains the past foreground objects within itself, where the most recent one is brighter than the earlier ones.
Because the obtained motion features are high dimensional data, then dimensionality reduction becomes an essential part of the system. On the one hand, the process of dimensionality reduction extract main features of data, on the other hand, it helps to weaken the influence of noise. There are many algorithms,such as PCA[4,5], LPP [5],LDA [5],Laplacian Eigenmaps [5] and the corresponding kernel versions.We decide to apply PCA into our dimensionality reduction module. PCA is a simple but classical method,whose advantage lies in reserving much intrinsic information of data. That‘s to say,the compressed data can be used in reconstruction.
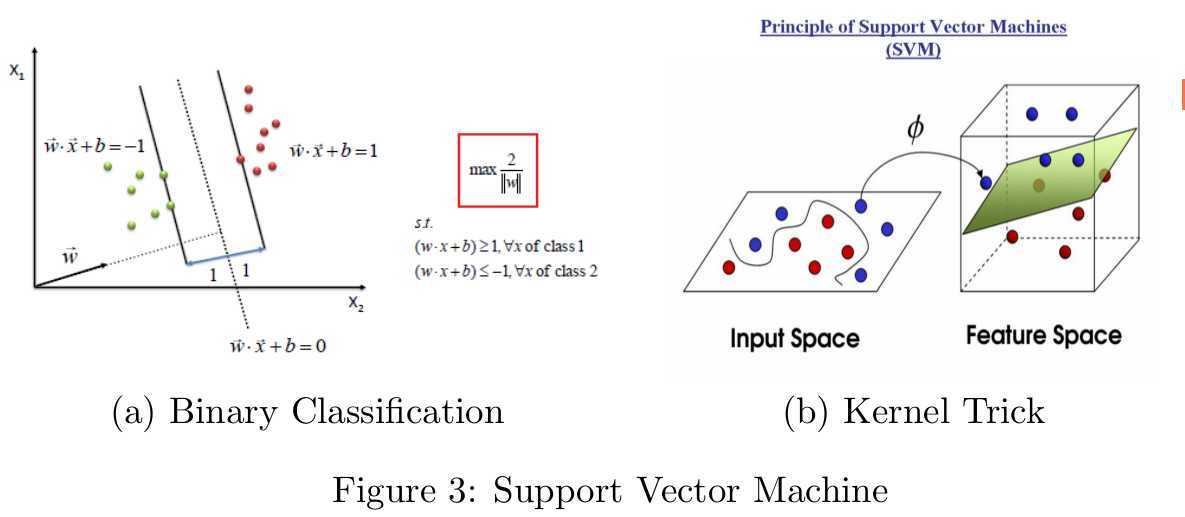
Our ultimate goal is making the system recognize actions correctly.So classifier used for learning and recognizing play a crucial role in the system.So far,classifiers such as Bayes classifier [9], decision trees [8], support vector machines(SVM) [10] have been widely used in machine learning. I prefer to use SVM in this module. Originally, SVM was a technique for binary classification.Later it was extended to regression and clustering problems. SVM maps feature vectors into a higher-dimensional space using a kernel function and builds an optimal hyper-plane fitting into the training data to implements the task of classification.
All the video samples in the experiments are
made by Pose Pro 2012,including five people in a same scene waving hands,jumping
and walking. Besides,the shooting angle of the camera in the scene ranges from
°
~50
°

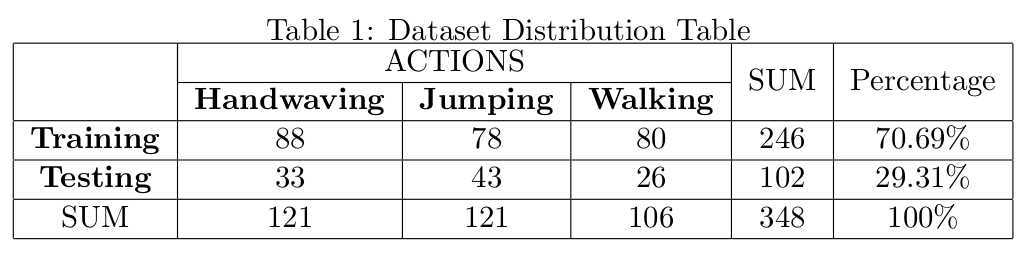
We split the whole dataset into training set and testing set,as shown in Table 1. It‘s suggested that the ratio between training data and testing data is 7:3.
From Figure 5, we can see that the foreground objective extraction is not as perfect as we expect.What we get are the moving parts of the objective,not the whole objective. GMM only concerns itself with the moving parts having relatively different color with the background.It seems to be a drawback of GMM. That won‘t affect the following motion features extraction much. Thinking in another way,which kind of action an objective is doing only decided by its moving parts.

Besides,the parameters of GMM especially the
background threshold
Figure 6 shows the corresponding motion
history images to us. It‘s mentioned before that MHI is actually the
superimposition of foreground objective with weight. There is no need to make
all the foreground objectives extracted be part of MHI. It‘s better to sample
the whole foreground objectives sequence and integrate every
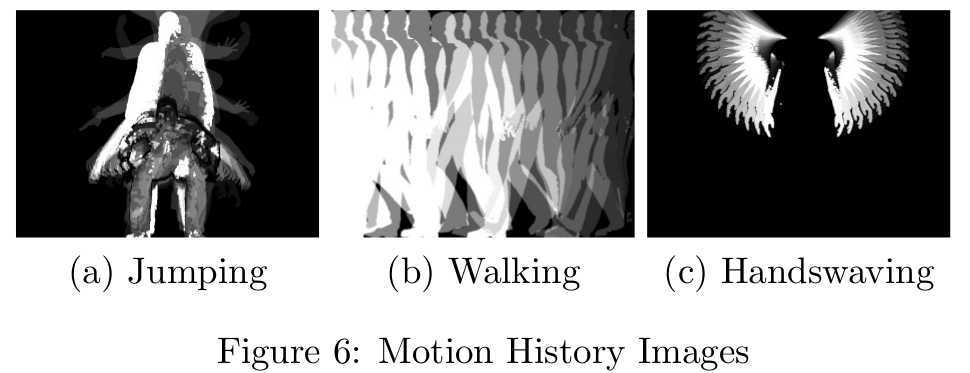
We compress MHI with the aim of simplifying
the action features further, so as to reduce the burden of the module of
learning and recognition. PCA is a linear method and easy to implement. The
compressed data can be used to construct data approximating the original data.
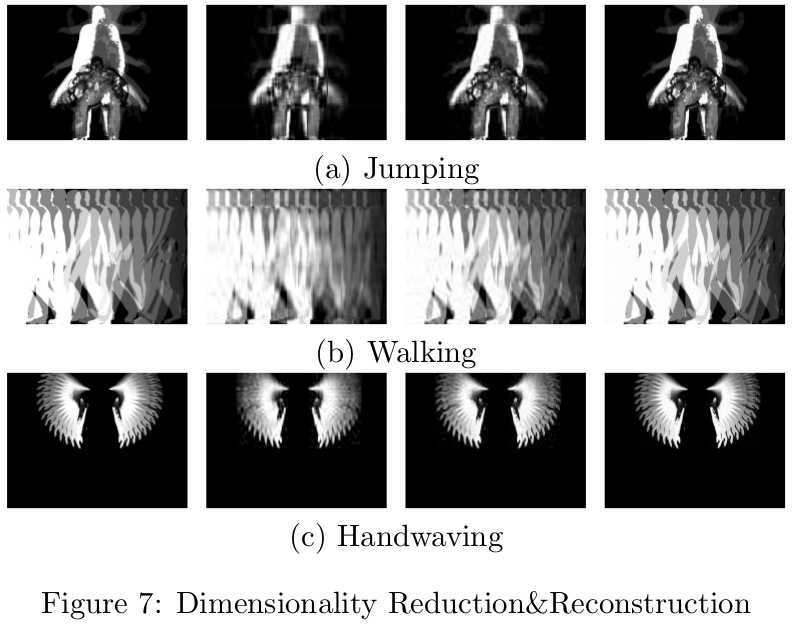
In Figure 7, the images in the first column are the original motion history
image and the images in the second,third and fourth column are reconstructed
from compressed data whose number of principal components are respectively 10,20
and 60. It can be easily observed that the more principal components used, the
more similar the reconstructed image is to the original image. When the number
of principal components is
We choose radial basis
function(RBF) as the kernel function of SVM.Its parameter
The cross-validation procedure can prevent the
overfitting problem. In v-fold cross-validation, we first divide the training
set into
We recommend a “grid-search” on ?5
,2
?3
,?,2
15
,γ=2
?15
,2
?13
,?,2
3
)
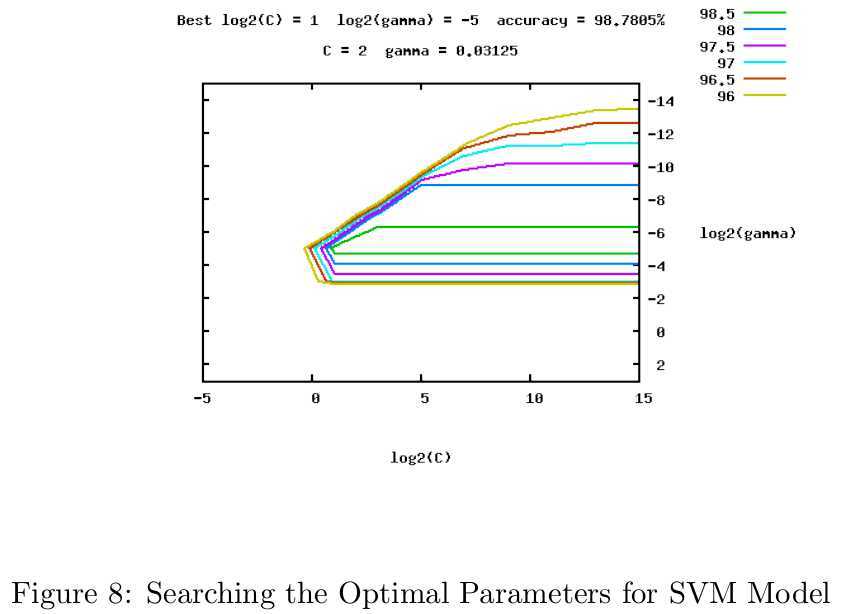
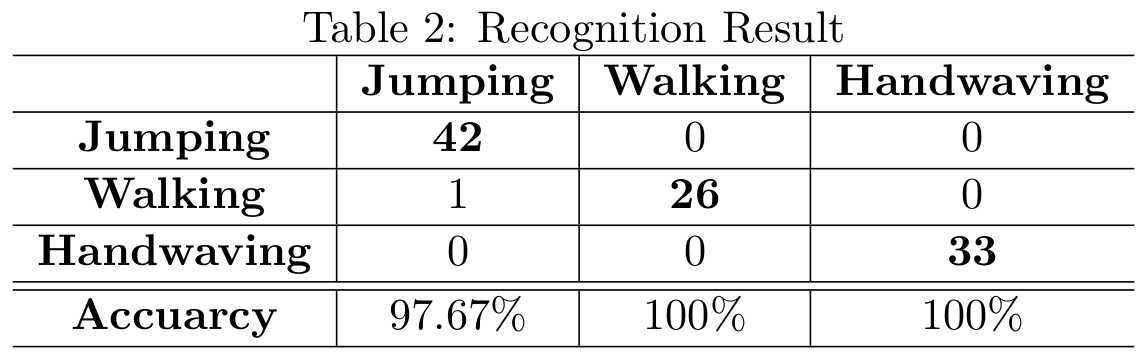
Table 2 shows the confusion matrix obtained
from our system. Every element on the diagonal corresponds to the correctly
recognised number of each action in the testing set. The element of
Clearly, there are a lot of flaws in theory in the system, which have been pointed out more or less in the designing part. Besides, there are some aspects needed to be improved:
Plenty of work still need to be done to build a excellent and practical actions recognition system.
In one word, we need to explore the intrinsic characteristics of specific data and relationships between them.
[1] JK Aggarwal and M.S. Ryoo. Human activity analysis: A review. ACM Computing Surveys (CSUR), 43(3):16, 2011.
[2] J.L. Barron, D.J. Fleet, and SS Beauchemin. Performance of optical flow techniques. International journal of computer vision, 12(1):43–77,1994.
[3] C.W. Hsu, C.C. Chang, C.J. Lin, et al. A practical guide to support vector classification, 2003.
[4] A. Hyv ?rinen, J. Karhunen, and E. Oja. Principal component analysis,a2001.
[5] E. Kokiopoulou, J. Chen, and Y. Saad. Trace optimization and eigen-problems in dimension reduction methods. Numerical Linear Algebra with Applications, 18(3):565–602, 2011.
[6] H. Meng, N. Pears, M. Freeman, and C. Bailey. Motion history histograms for human action recognition. Embedded Computer Vision,pages 139–162, 2009.
[7] C. Stauffer and W.E.L. Grimson. Learning patterns of activity using real-time tracking. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 22(8):747–757, 2000.
[8] Decision tree. http://en.wikipedia.org/wiki/Decision_tree.
[9] Naive bayes classifier. http://en.wikipedia.org/wiki/Naive_Bayes_classifier.
[10] Support vector machine. http://en.wikipedia.org/wiki/Support_vector_machine.
Email:yunfeiwang@hust.edu.cn
A Simple Actions Recognition System,布布扣,bubuko.com
A Simple Actions Recognition System
原文地址:http://www.cnblogs.com/jeromeblog/p/3733327.html