标签:apt 机制 targe 程序 追踪 一对一 技术 运行 关系
shuffle 是划分 DAG 中 stage 的标识,同时影响 Spark 执行速度的关键步骤.
RDD 的 Transformation 函数中,又分为窄依赖(narrow dependency)和宽依赖(wide dependency)的操作.窄依赖跟宽依赖的区别是是否发生 shuffle(洗牌) 操作.宽依赖会发生 shuffle 操作. 窄依赖是子 RDD的各个分片(partition)不依赖于其他分片,能够独立计算得到结果,宽依赖指子 RDD 的各个分片会依赖于父RDD 的多个分片,所以会造成父 RDD 的各个分片在集群中重新分片, 看如下两个示例:
第一个 Map 操作将 RDD 里的各个元素进行映射, RDD 的各个数据元素之间不存在依赖,可以在集群的各个内存中独立计算,也就是并行化,第二个 groupby 之后的 Map 操作,为了计算相同 key 下的元素个数,需要把相同 key 的元素聚集到同一个 partition 下,所以造成了数据在内存中的重新分布,即 shuffle 操作.shuffle 操作是 spark 中最耗时的操作,应尽量避免不必要的 shuffle.
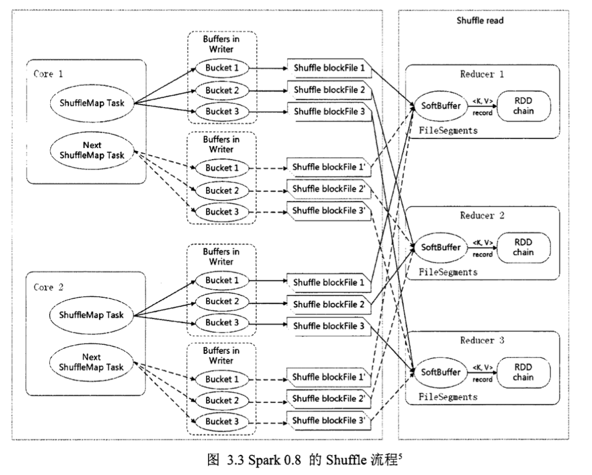
宽依赖主要有两个过程: shuffle write 和 shuffle fetch. 类似 Hadoop 的 Map 和 Reduce 阶段.shuffle write 将 ShuffleMapTask 任务产生的中间结果缓存到内存中, shuffle fetch 获得 ShuffleMapTask 缓存的中间结果进行 ShuffleReduceTask 计算,这个过程容易造成OutOfMemory.
shuffle 过程内存分配使用 ShuffleMemoryManager 类管理,会针对每个 Task 分配内存,Task 任务完成后通过 Executor 释放空间.这里可以把 Task 理解成不同 key 的数据对应一个 Task. 早期的内存分配机制使用公平分配,即不同 Task 分配的内存是一样的,但是这样容易造成内存需求过多的 Task 的 OutOfMemory, 从而造成多余的 磁盘 IO 过程,影响整体的效率.(例:某一个 key 下的数据明显偏多,但因为大家内存都一样,这一个 key 的数据就容易 OutOfMemory).1.5版以后 Task 共用一个内存池,内存池的大小默认为 JVM 最大运行时内存容量的16%,分配机制如下:假如有 N 个 Task,ShuffleMemoryManager 保证每个 Task 溢出之前至少可以申请到1/2N 内存,且至多申请到1/N,N 为当前活动的 shuffle Task 数,因为N 是一直变化的,所以 manager 会一直追踪 Task 数的变化,重新计算队列中的1/N 和1/2N.但是这样仍然容易造成内存需要多的 Task 任务溢出,所以最近有很多相关的研究是针对 shuffle 过程内存优化的.
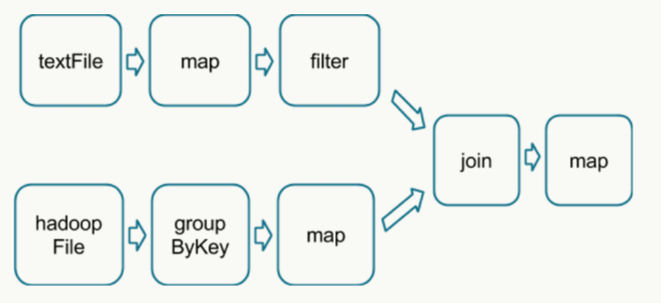
如下 DAG 流程图中,分别读取数据,经过处理后 join 2个 RDD 得到结果:
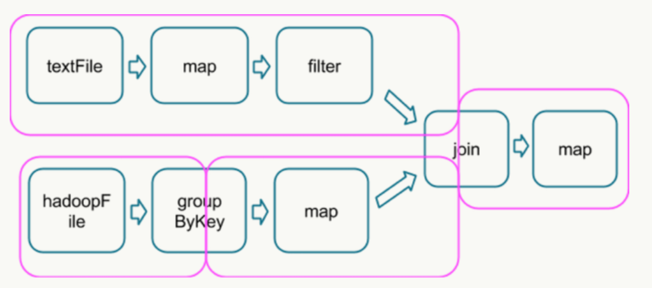
在这个图中,根据是否发生 shuffle 操作能够将其分成如下的 stage 类型:(join 需要针对同一个 key 合并,所以需要 shuffle)
运行到每个 stage 的边界时,数据在父 stage 中按照 Task 写到磁盘上,而在子 stage 中通过网络按照 Task 去读取数据。这些操作会导致很重的网络以及磁盘的I/O,所以 stage 的边界是非常占资源的,在编写 Spark 程序的时候需要尽量避免的 。父 stage 中 partition 个数与子 stage 的 partition 个数可能不同,所以那些产生 stage 边界的 Transformation 常常需要接受一个 numPartition 的参数来觉得子 stage 中的数据将被切分为多少个 partition7。PS:shuffle 操作的时候可以用 combiner 压缩数据,减少 IO 的消耗
总结:
在仅有一次shuffle 操作的时候,HIVE SQL 会比SPARK SQL更快,因为shuffle之后都会落一次盘或者不落盘。
绝大多数,Spark 都比 Hadoop 计算要快。这主要得益于其对 mapreduce 操作的优化以及对 JVM 使用的优化。
Shuffle 操作理解:涉及到合并操作的话,就会产生shuffle操作(比如group by 和 join 操作),一个shuffle会将任务分成不同的stage
宽依赖、窄依赖
宽依赖:本质就时shuffle,父RDD和子RDD partition 之间存在多对的关系
窄依赖:父RDD和子RDD partition 之间一对一的关系
原文参考:https://blog.csdn.net/databatman/article/details/53023818#4shuffle-和-stage
标签:apt 机制 targe 程序 追踪 一对一 技术 运行 关系
原文地址:https://www.cnblogs.com/Allen-rg/p/12966799.html