标签:term anti 智能 isa work fun com general processes


Training set consists of labeled samples from lots of “tasks”, e.g., classifying cars, cats, dogs, planes . . .
Data from the new task, e.g., classifying strawberries has:

Few-shot setting considers the case when s is small.
Meta-learning forms the basis for almost all current algorithms. Here’s one successful instantiation.
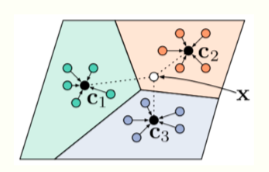
Prototypical Networks [Snell et al., 2017]

A classifier trained on a dataset \(D_s\) is a function F that classifies data x using
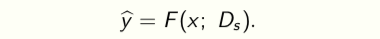
The parameters \(θ^? = θ(D_s )\) of the classifier are a statistic of the dataset Ds obtained after training. Maintaining this statistic avoids having to search over functions F at inference time.
We cannot learn a good (sufficient) statistic using few samples. So we will search over functions at test-time more explicitly
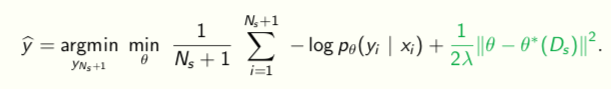
 ## A very simple baseline
## A very simple baseline
with a few practical tricks like cosine annealing of step-sizes,
mixup regularization, 16-bit training, very heavy data augmentation, and label smoothing cross-entrop



1-shot, 5-way accuracies are as high as 89%, 1-shot 20-way accuracies are about 70%.

表征学习的热力学观点
Let’s take an example from computer vision
(.Zamir, A. R., Sax, A., Shen, W., Guibas, L. J., Malik, J., & Savarese, S. Taskonomy: Disentangling task transfer learning. CVPR 2018)

信息瓶颈原则
A generalization of rate-distortion theory for learning relevant representations of data [Tishby et al., 2000]
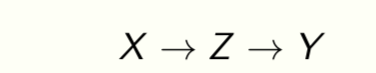
Z is a representation of the data X. We want
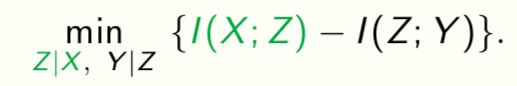
Doing well on one task requires throwing away nuisance information [Achille & Soatto, 2017].
The IB Lagrangian simply minimizes \(I(X;Z)\), it does not let us measure what was thrown away.
Choose a canonical task to measure discarded information. Setting
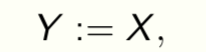
i.e., reconstruction of data, gives a special task. It is the superset of all tasks and forces the model to learn lossless representations.
The architecture we will focus on is

Shanon entropy measures the complexity of data
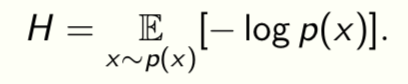
Distortion D measures the quality of reconstruction
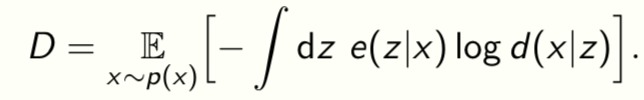
Rate R measures the average excess bits used to encode the representation
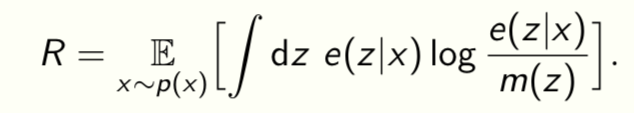
We know that [Alemi et al., 2017]
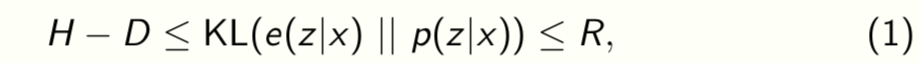
this is the well-known ELBO (evidence lower-bound). Let
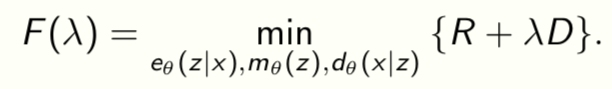
This is a Lagrange relaxation of the fact that given a variational family and data there is an optimal value R = func(D) that best sandwiches (1).

Let us extend the Lagrangian to

where the classification loss is
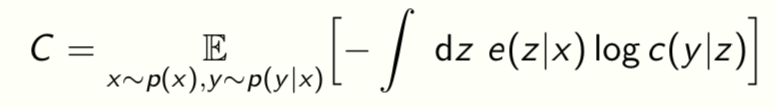
Can also include other quantities like the entropy S of the model parameters
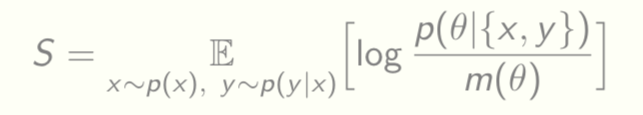

The existence of a convex surface func(R,D,C,S) = 0 tying together these functionals allows a formal connection to thermodynamics [Alemi and Fischer 2018]
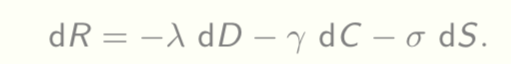
Just like energy is conserved in physical processes, information is conserved in the model, either it is in the encoder-classifier pair or it is in the decoder.
The RDC surface determines all possible representations that can be learnt from given data. Can solve the variational problem for F(λ,γ) to get
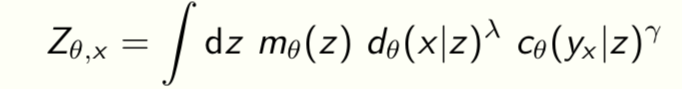
and
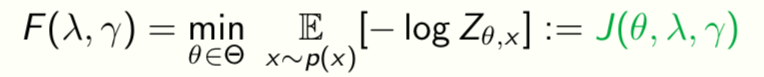
This is called the “equilibrium surface” because training converges to some point on this surface. We now construct ways to travel on the surface
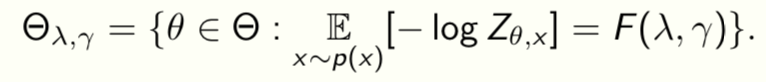 The surface depends on data p(x,y).
The surface depends on data p(x,y).
A quasi-static process happens slowly enough for the system to remain in equilibrium with its surroundings, e.g., reversible expansion of an ideal gas.
We will create a quasi-static process to travel on the RDC surface. This constraint is
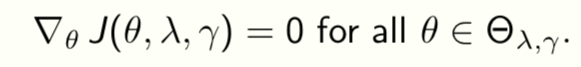
e.g., if we want classification loss to be constant in time, we need

……
更多精彩,请下载 资源文件 了解。
关注公众号“小样本学习与智能前沿”,回台回复“200527” ,即可获取资源文件“Learning with Few Labeled Data.pdf”

Simple methods such as transductive fine-tuning work extremely well for few-shot learning. This is really because of powerful function approximators such as neural networks.
The RDC surface is a fundamental quantity and enables principled methods for transfer learning. Also unlocks new paths to understanding regularization and properties of neural architecture for classical supervised learning.
We did well in the era of big data without understanding much about data; this is unlikely to work in the age of little data.
Email questions to pratikac@seas.upenn.edu Read more at
少标签数据学习:宾夕法尼亚大学Learning with Few Labeled Data
标签:term anti 智能 isa work fun com general processes
原文地址:https://www.cnblogs.com/joselynzhao/p/12971538.html