标签:包含 har struct 示例 值类型 需要 src rom 表数
Hive支持原始数据类型和复杂类型,原始类型包括数值型,Boolean,字符串,时间戳。复杂类型包括数组,map,struct。下面是Hive数据类型的一个总结:
| 分类 | 类型 | 描述 | 字面量示例 |
|---|---|---|---|
| 原始类型 | BOOLEAN | true/false | TRUE |
| TINYINT | 1字节的有符号整数 -128~127 | 1Y | |
| SMALLINT | 2个字节的有符号整数,-32768~32767 | 1S | |
| INT | 4个字节的带符号整数 | 1 | |
| BIGINT | 8字节带符号整数 | 1L | |
| FLOAT | 4字节单精度浮点数1.0 | ||
| DOUBLE | 8字节双精度浮点数 | 1.0 | |
| DEICIMAL | 任意精度的带符号小数 | 1.0 | |
| STRING | 字符串,变长 | “a”,’b’ | |
| VARCHAR | 变长字符串 | “a”,’b’ | |
| CHAR | 固定长度字符串 | “a”,’b’ | |
| BINARY | 字节数组 | 无法表示 | |
| TIMESTAMP | 时间戳,纳秒精度 | 122327493795 | |
| DATE | 日期 | ‘2016-03-29’ | |
| 复杂类型 | ARRAY | 有序的的同类型的集合 | array(1,2) |
| MAP | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) | |
| STRUCT | 字段集合,类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) | |
| UNION | 在有限取值范围内的一个值 | create_union(1,’a’,63) |
HQL的基本类型和Java的基本类型很接近,虽然受到一些MySQL命名的影响。
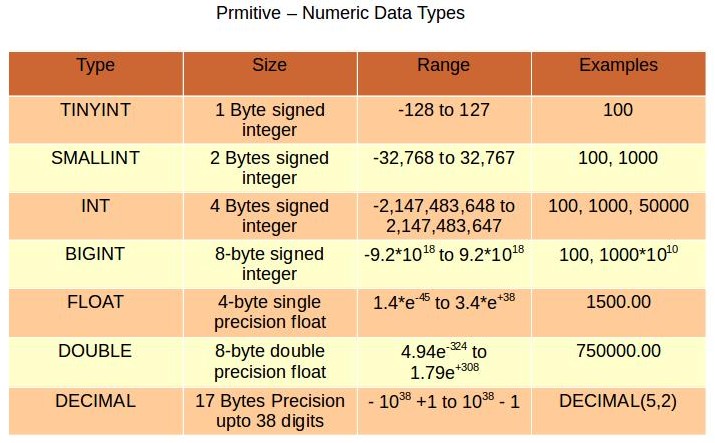
Hive有4种带符号的整数类型:TINYINT,SMALLINT,INT,BIGINT,分别对应Java中的byte,short,int,long。字节长度分别为1,2,4,8字节。在使用整数字面量时,默认情况下为INT,如果要声明为其他类型,通过后缀来标识:
| 类型 | 后缀 | 例子 |
|---|---|---|
| TINYINT | Y | 100Y |
| SMALLINT | S | 100S |
| BIGINT | L | 100L |
浮点类型包括FLOAT和DOUBLE两种,对应到Java的float和double,分别为32位和64位浮点数。DECIMAL用于表示任意精度的小树,类似于Java的BigDecimal,通常在货币当中使用。例如DECIMAL(5,2)用于存储-999.99到999.99的数字,省略掉小数位,DECIAML(5)表示-99999到99999的数字。DECIMAL则等同于DECIMAL(10,0)。小数点左边允许的最大位数为38位。
数值类型总结如下表:
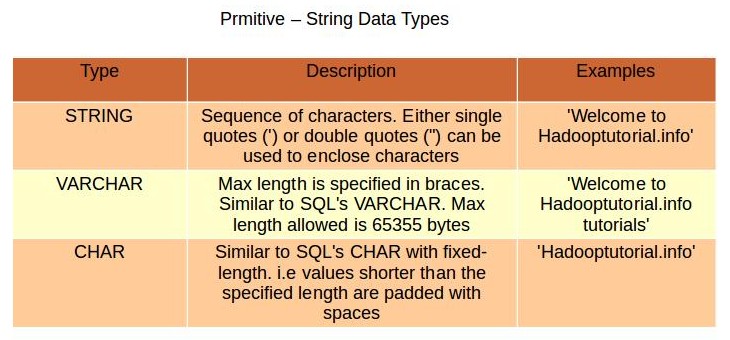
Hive有3种类型用于存储字文本。STRING存储变长的文本,对长度没有限制。理论上将STRING可以存储的大小为2GB,但是存储特别大的对象时效率可能受到影响,可以考虑使用Sqoop提供的大对象支持。VARCHAR与STRING类似,但是长度上只允许在1-65355之间。例如VARCHAR(100).CHAR则用固定长度来存储数据。
BOOLEAN表示二元的true或false。
BINARY用于存储变长的二进制数据。
TIMESTAMP则存储纳秒级别的时间戳,同时Hive提供了一些内置函数用于在TIMESTAMP与Unix时间戳(秒)和字符串之间做转换。例如:
时间戳类型的数据不包含任务的时区信息,但是to_utc_timestamp和from_utc_timestamp函数可以用于时区转换。DATE类型则表示日期,对应年月日三个部分。
Hive的类型层次中,可以根据需要进行隐式的类型转换,例如TINYINT与INT相加,则会将TINYINT转化成INT然后INT做加法。隐式转换的规则大致可以归纳如下:
任意数值类型都可以转换成更宽的数据类型(不会导致精度丢失)或者文本类型。
所有的文本类型都可以隐式地转换成另一种文本类型。也可以被转换成DOUBLE或者DECIMAL,转换失败时抛出异常。
BOOLEAN不能做任何的类型转换。
时间戳和日期可以隐式地转换成文本类型。
也可以使用CAST进行显式的类型转换,例如CAST(‘1‘ as INT),如果转换失败,CAST返回NULL。
Hive有4种复杂类型的数据结构:ARRAY,MAP,STRUCT,UNION。
ARRAY和MAP类型与Java中的数据和映射表。数组的类型声明格式为ARRAY<data_type>,元素访问通过0开始的下标,例如arrays[1]访问第二个元素。
MAP通过MAP<primitive_type,data_type>来声明,key只能是基本类型,值可以是任意类型。map的元素访问则使用[],例如map[‘key1‘].
STRUCT则封装一组有名字的字段(named filed),其类型可以是任意的基本类型,元素的访问使用点号。
UNION则类似于C语言中的UNION结构,在给定的任何一个时间点,UNION类型可以保存指定数据类型中的任意一种。类型声明语法为UNIONTYPE<data_type,data_type,…>。每个UNION类型的值都通过一个整数来表示其类型,这个整数位声明时的索引,从0开始。例如:
CREATE TABLE union_test(foo UNIONTYPE<int,double,array<string>,strucy<a:int,b:string>>);foo的一些取值如下:
其中冒号左边的整数代表数据类型,必须在预先定义的范围类,通过0开始的下标表示。冒号右边是该类型的取值。
下面的这个CRATE语句用到了这4中复杂类型:
通过下面的SELECT语句查询相应的数据:
SELECT c1[0] , c2[‘b‘],c3.c , c4 FROM complex结果类似:
1 2 1.0 {1:63}标签:包含 har struct 示例 值类型 需要 src rom 表数
原文地址:https://www.cnblogs.com/SunshineKimi/p/12977624.html