标签:获取 特性 有序 出现 ack inux 在线 根据 应用
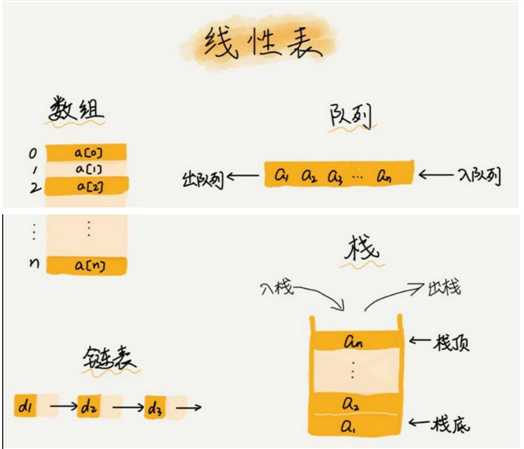
例子:
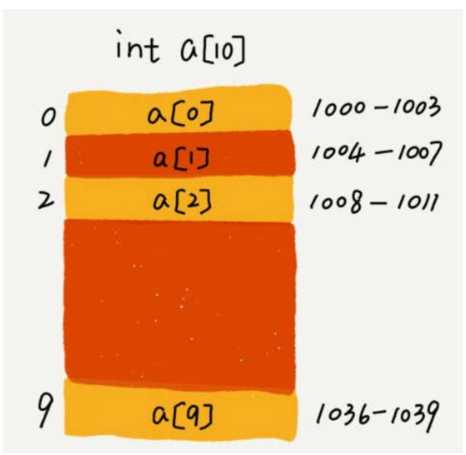
我们拿一个长度为 10 的 int 类型的数组 int[] a = new int[10] 来举例。在我画的这个图中,计算机给数组 a[10],分配了一块连续内存空间 1000~ 1039,其中,内存块的首地址为 base_address = 1000。
插入操作:
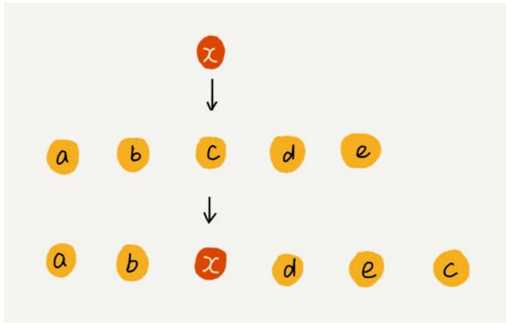
利用这种处理技巧,在特定场景下,在第 k 个位置插入一个元素的时间复杂度就会降为 O(1)。这个处理思想在快排中也会用到。
删除操作:
跟插入数据类似,如果我们要删除第 k 个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了。
和插入类似,如果删除数组末尾的数据,则最好情况时间复杂度为 O(1);如果删除开头的数据,则最坏情况时间复杂度为 O(n);平均情况时间复杂度也为 O(n)。
实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率是不是会提高很多呢?
我们继续来看例子。数组 a[10] 中存储了 8 个元素:a, b, c, d, e, f, g, h。现在,我们要依次删除 a, b, c 三个元素。

为了避免 d, e, f, g, h 这几个数据会被搬移三次,我们可以先记录下已经删除的数据。
每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。
当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
如果你了解 JVM,你会发现,这不就是 JVM 标记清除垃圾回收算法的核心思想吗?
数组和 ArrayList 的选择:
底层的存储结构:
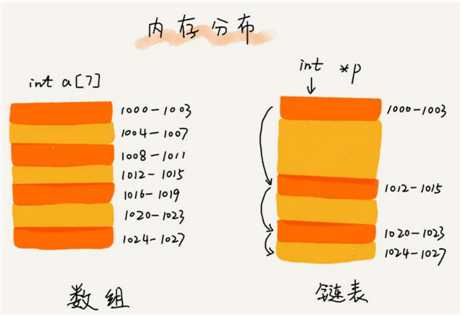
性能比较:

总结来看:
链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。
为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。
如下图所示,我们把这个记录下个结点地址的指针叫作后继指针 next。
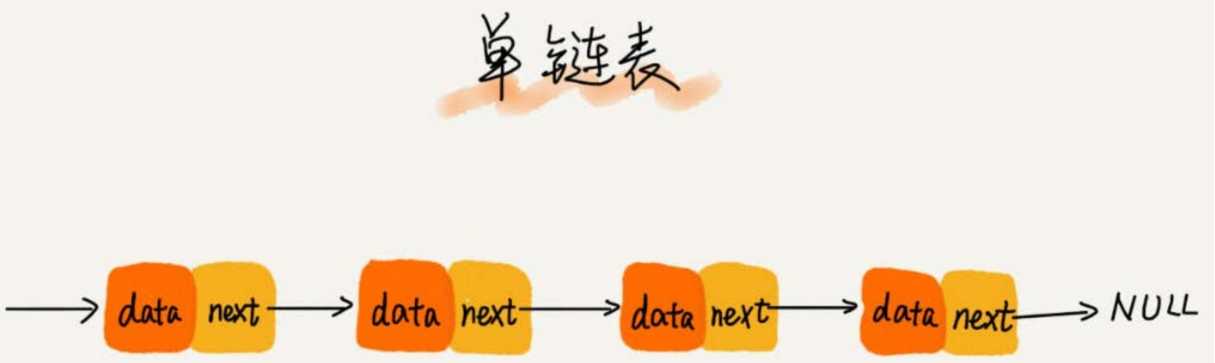
从图中可以发现,其中有两个结点是比较特殊的,它们分别是第一个结点和最后一个结点。
第一个结点叫作头结点,头结点用来记录链表的基地址。有了它,我们就可以遍历得到整条链表。
把最后一个结点叫作尾结点。而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址NULL,表示这是链表上最后一个结点。
插入、修改、查找
与数组一样,链表也支持数据的查找、插入和删除操作。我们知道,在进行数组的插入、删除操作时,为了保持内存数据的连续性,需要做大量的数据搬移,所以时间复杂度是O(n)。
在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。
所以,在链表中插入和删除一个数据是非常快速的。从下图中我们可以看出,针对链表的插入和删除操作,我们只需要考虑相邻结点的指针改变,所以对应的时间复杂度是O(1)。
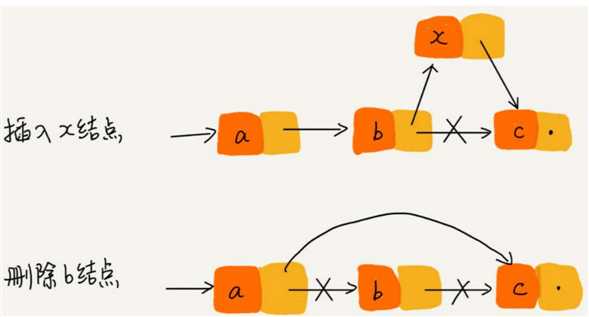
链表要想随机访问第k个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点。
所以,链表随机访问的性能没有数组好,需要 O(n) 的时间复杂度。
循环链表是一种特殊的单链表。
它跟单链表唯一的区别就在尾结点。我们知道,单链表的尾结点指针指向空地址,表示这就是最后的结点了。
而循环链表的尾结点指针是指向链表的头结点。如下图所示,它像一个环一样首尾相连,所以叫作“循环”链表。
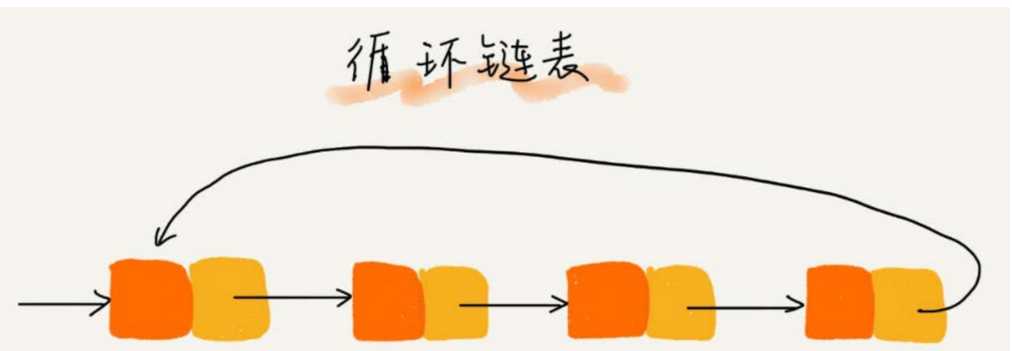
和单链表相比, 循环链表的优点是从链尾到链头比较方便。
当要处理的数据具有环型结构特点时,就特别适合采用循环链表。
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表,顾名思义,它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
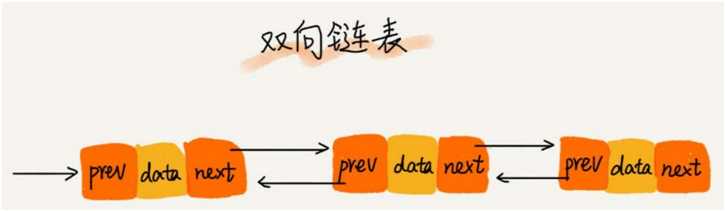
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。
虽然两个指针比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。那相比单链表,双向链表适合解决哪种问题呢?
从结构上来看,双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
举个删除的例子:
删除结点中“值等于某个给定值”的结点:
删除给定指针指向的结点:
除了插入、删除操作有优势之外,对于一个有序链表,双向链表的按值查询的效率也要比单链表高一些。因为,我们可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
这就是为什么在实际的软件开发中,双向链表尽管比较费内存,但还是比单链表的应用更加广泛的原因。
如果你熟悉Java语言,你肯定用过LinkedHashMap这个容器。如果你深入研究LinkedHashMap的实现原理,就会发现其中就用到了双向链表这种数据结构。
实际上,这里有一个更加重要的知识点需要你掌握,那就是用空间换时间的设计思想。当内存空间充足的时候,如果我们更加追求代码的执行速度,我们就可以选择空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构。相反,如果内存比较紧缺,比如代码跑在手机或者单片机上,这个时候,就要反过来用时间换空间的设计思路。
从栈的操作特性上来看, 栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。先进后出。
/**
* @author xiandongxie
* 基于数组实现的栈
*/
public class ArrayStack {
public String[] arr = null;
private int num;//栈中元素个数
private int n;// 栈的大小
public ArrayStack(int n) {
arr = new String[n];
num = 0;
this.n = n;
}
public boolean push(String value) {
if (StringUtils.isEmpty(value)) return false;
if (num >= n) return false;
arr[num] = value;
num++;
return true;
}
public String pop() {
if (num > n || num <= 0) return null;
num--;
return arr[num];
}
}
队列跟栈一样,也是一种操作受限的线性表数据结构。只不过可以再两端操作,先进先出。
队列的概念很好理解,基本操作也很容易掌握。作为一种非常基础的数据结构,队列的应用也非常广泛,特别是一些具有某些额外特性的队列,比如循环队列、阻塞队列、并发队列。它们在很多偏底层系统、框架、中间件的开发中,起着关键性的作用。比如高性能队列 Disruptor、 Linux 环形缓存,都用到了循环并发队列; Java concurrent 并发包利用 ArrayBlockingQueue 来实现公平锁等。
/**
* 用数组实现队列
*/
class ArrayQueue {
// 装载数据的数组
private String[] arr;
// 数组容量大小
private int n;
// 队列头
private int start;
// 队列尾
private int end;
public ArrayQueue(int n) {
this.arr = new String[n];
this.start = 0;
this.end = 0;
this.n = n;
}
// 添加元素
public boolean push(String data) throws Exception {
if (end >= n && start == 0) {
throw new Exception("超出容量,且数据不需要移动,此时只能对队列扩容才能存入," +
"end=" + end + ", n=" + n + ", start=" + start);
}
if (end >= n && start > 0) {
System.out.println("超出容量,但是队列头部已经消费,可以移动数据扩容," +
"end=" + end + ", n=" + n + ", start=" + start);
for (int i = 0; i < end - start; i++) {
arr[i] = arr[start + i];
}
end = end - start;
start = 0;
}
arr[end] = data;
end++;
return true;
}
// 取出元素
public String pop() throws Exception {
if (end <= 0 || start >= end) {
throw new Exception("没有元素,队列为空,end=" + end + ", n=" + n + ", start=" + start);
}
String value = arr[start];
start++;
return value;
}
public String[] getArr() {
return arr;
}
}
/**
* 用链表实现队列
*/
class LinkedQueue {
// 定义节点类
private class Node {
Node nextNode;
String value;
}
// 头指针
private Node head;
// 尾指针
private Node tail;
// 数据个数
private int size;
public LinkedQueue() {
this.size = 0;
}
// 添加
public boolean push(String data) {
Node newNode = new Node();
newNode.value = data;
if (size == 0) {
head = newNode;
} else {
tail.nextNode = newNode;
}
tail = newNode;
size++;
return true;
}
// 移除
public String pop() throws Exception {
if (size <= 0) {
throw new Exception("队列为空,size=" + size);
}
if (size == 1){
tail = null;
}
size--;
String value = head.value;
head = head.nextNode;
return value;
}
}
对于栈来说,我们只需要一个栈顶指针就可以了。
但是队列需要两个指针:一个是 head 指针,指向队头;一个是 tail 指针,指向队尾。
你可以结合下面这幅图来理解。当 a 、b、c、d 依次入队之后,队列中的 head 指针指向下标为 0 的位置, tail 指针指向下标为 4 的位置。
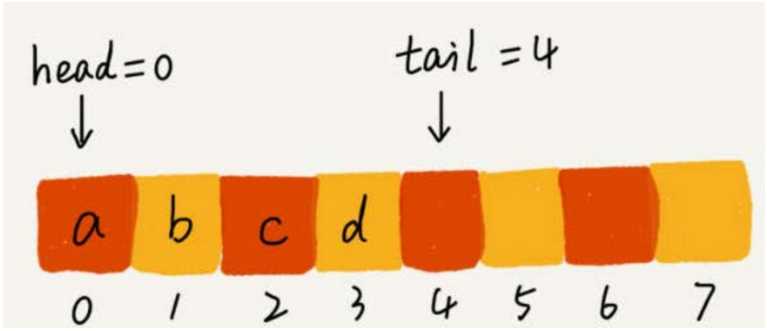
当我们调用两次出队操作之后,队列中 head 指针指向下标为 2 的位置, tail 指针仍然指向下标为4的位置。
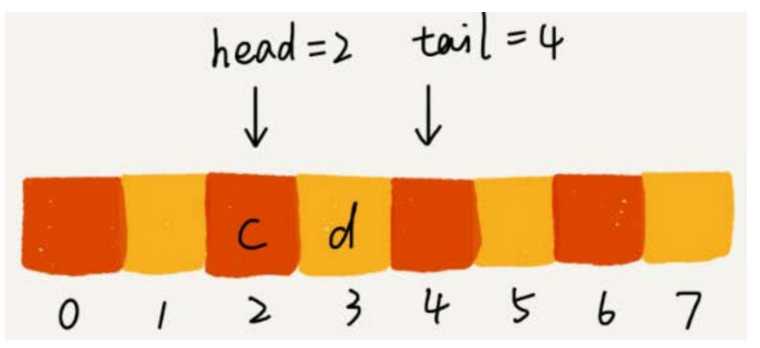
随着不停地进行入队、出队操作, head 和 tail 都会持续往后移动。当 tail 移动到最右边,即使数组中还有空闲空间,也无法继续往队列中添加数据了。这个问题该如何解决呢?
用数据搬移!但是,每次进行出队操作都相当于删除数组下标为 0 的数据,要搬移整个队列中的数据,这样出队操作的时间复杂度就会从原来的 O(1) 变为 O(n)。能不能优化一下呢?
我们在出队时可以不用搬移数据。如果没有空闲空间了,我们只需要在入队时,再集中触发一次数据的搬移操作。借助这个思想,出队函数 pop() 保持不变,我们稍加改造一下入队函数 push() 的实现,就可以轻松解决刚才的问题了。
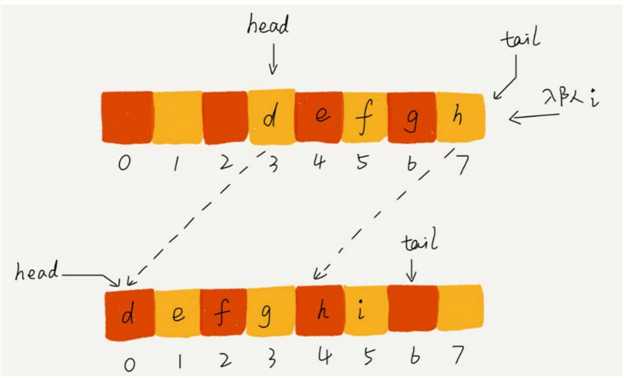
我们刚才用数组来实现队列的时候,在 tail == n 时,会有数据搬移操作,这样入队操作性能就会受到影响。那有没有办法能够避免数据搬移呢?
我们来看看循环队列的解决思路。循环队列,顾名思义,它长得像一个环。原本数组是有头有尾的,是一条直线。现在我们把首尾相连,扳成了一个环。
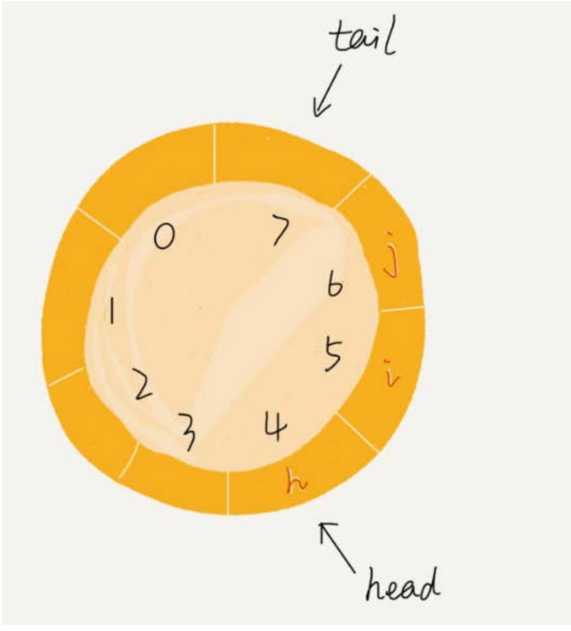
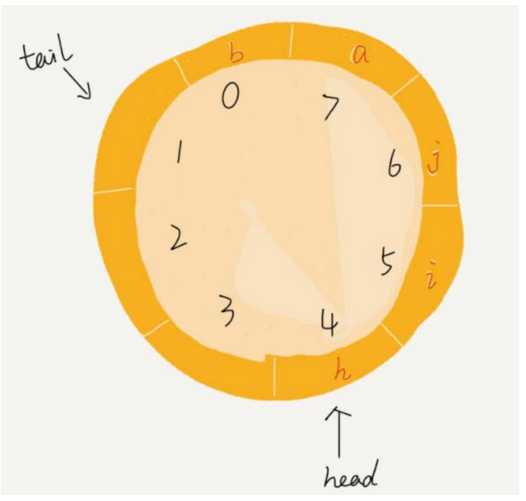
我们可以看到,图中这个队列的大小为 8,当前 head=4, tail=7。当有一个新的元素 a 入队时,我们放入下标为 7 的位置。
但这个时候,我们并不把 tail 更新为8,而是将其在环中后移一位,到下标为 0 的位置。
当再有一个元素 b 入队时,我们将 b 放入下标为 0 的位置,然后 tail 加 1 更新为 1。
所以,在 a, b 依次入队之后,循环队列中的元素就变成了下面的样子:
通过这样的方法,我们成功避免了数据搬移操作。
看起来不难理解,但是循环队列的代码实现难度要比前面讲的非循环队列难多了。要想写出没有bug的循环队列的实现代码,我个人觉得,最关键的是,确定好队空和队满的判定条件。
在用数组实现的非循环队列中,队满的判断条件是 tail == n,队空的判断条件是 head == tail。
循环队列,队列为空的判断条件仍然是 head == tail。但队列满的判断条件就稍微有点复杂了。我画了一张队列满的图,你可以看一下,试着总结一下规律。
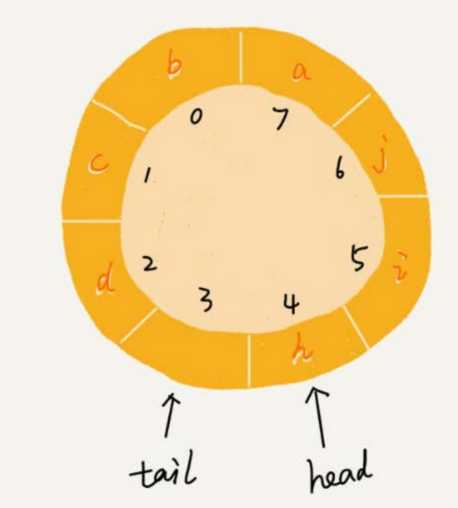
就像我图中画的队满的情况,tail=3,head=4,n=8,所以总结一下规律就是:(3+1) % 8 = 4。多画几张队满的图,你就会发现,当队满时,(tail+1) % n = head。
还有一点是当队列满时,图中的 tail 指向的位置实际上是没有存储数据的。所以,循环队列会浪费一个数组的存储空间。
public class CircularQueue {
// 数组: items,数组大小: n
private String[] items;
private int n = 0;
// head表示队头下标, tail表示队尾下标
private int head = 0;
private int tail = 0;
// 申请一个大小为capacity的数组
public CircularQueue(int capacity) {
items = new String[capacity];
n = capacity;
}
// 入队
public boolean enqueue(String item) {
// 队列满了
if ((tail + 1) % n == head)
return false;
items[tail] = item;
tail = (tail + 1) % n;
return true;
}
// 出队
public String dequeue() {
// 如果head == tail 表示队列为空
if (head == tail)
return null;
String ret = items[head];
head = (head + 1) % n;
return ret;
}
}
阻塞队列其实就是在队列基础上增加了阻塞操作。
简单来说,就是在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;
如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。
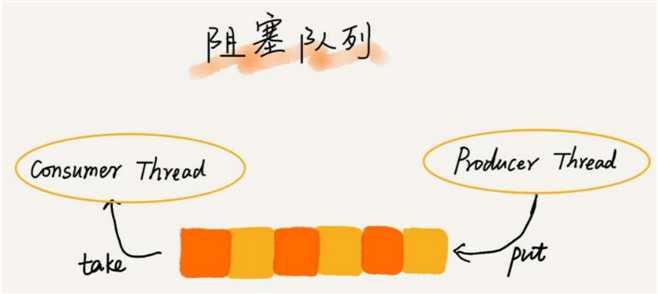
上述的定义就是一个“生产者-消费者模型”!我们可以使用阻塞队列,轻松实现一个“生产者-消费者模型”!
这种基于阻塞队列实现的“生产者-消费者模型”,可以有效地协调生产和消费的速度。
当“生产者”生产数据的速度过快,“消费者”来不及消费时,存储数据的队列很快就会满了。这个时候,生产者就阻塞等待,直到“消费者”消费了数据, “生产者”才会被唤醒继续“生产”。
而且不仅如此,基于阻塞队列,我们还可以通过协调“生产者”和“消费者”的个数,来提高数据的处理效率。比如前面的例子,我们可以多配置几个“消费者”,来应对一个“生产者”。
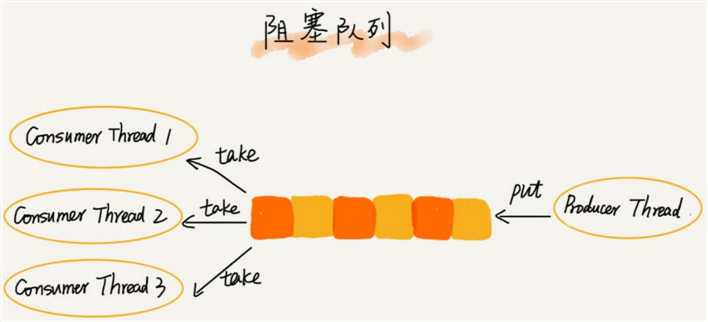
阻塞队列,在多线程情况下,会有多个线程同时操作队列,这个时候就会存在线程安全问题,那如何实现一个线程安全的队列呢?
线程安全的队列我们叫作并发队列。最简单直接的实现方式是直接在 enqueue()、 dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。
实际上,基于数组的循环队列,利用 CAS 原子操作,可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的原因。
标签:获取 特性 有序 出现 ack inux 在线 根据 应用
原文地址:https://www.cnblogs.com/xiexiandong/p/12983913.html