标签:机制 为什么 实现 结构 产生 input forward 图片 token
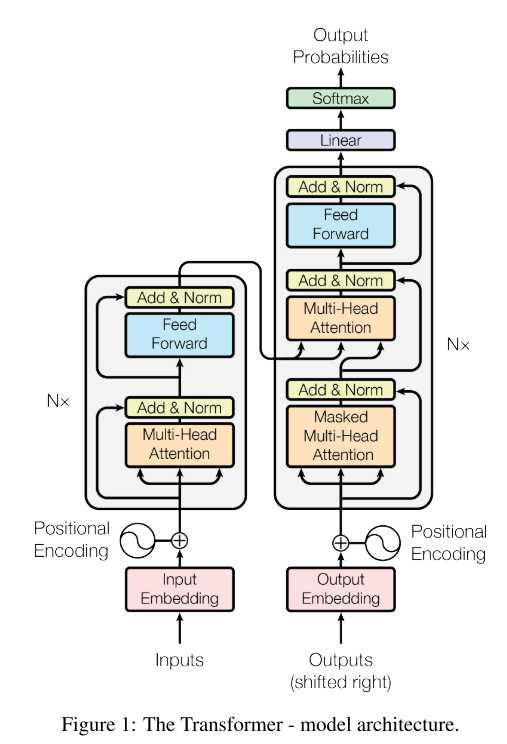
//这里为什么有两个output??什么意思?已经完全看不懂了。。
Transformer使用栈式自注意力机制,编码器和解码器的逐点完全连接层。
https://www.jianshu.com/p/e7d8caa13b21,这篇有讲到,Encoder的输出可以变换为注意力矩阵K和V,然后在解码的时候当然也要输入之前的输出?
但是比如说下面是用来翻译的,previous outputs那个I是从哪里来的?我就可能对机器翻译这个整个的过程都不懂啊!
下面的过程就是说,decoder的时候这个I am ... 什么的怎么就出来了???从哪里来的?
怎么产生预测的下一个单词的output呢?
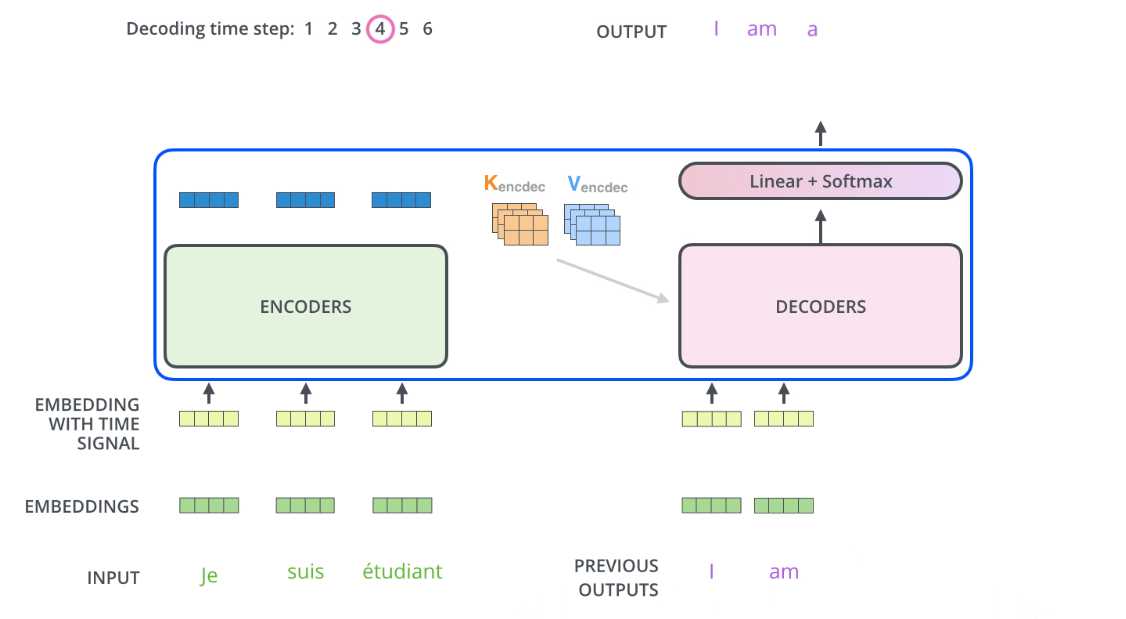
反正我还是看不太懂它的整个过程。我还是慢慢来看懂吧。
在bert中需要输入的三个参数为,input id,padding,segment,第一个就是序列token,第二个1表示有单词,0表示是pad补齐的, segment表示是a句还是b句。
其实这上面三个是没有看到位置编码出现在哪里的,应该是在forward的时候处理的,需要看源码实现。
https://zhuanlan.zhihu.com/p/48508221
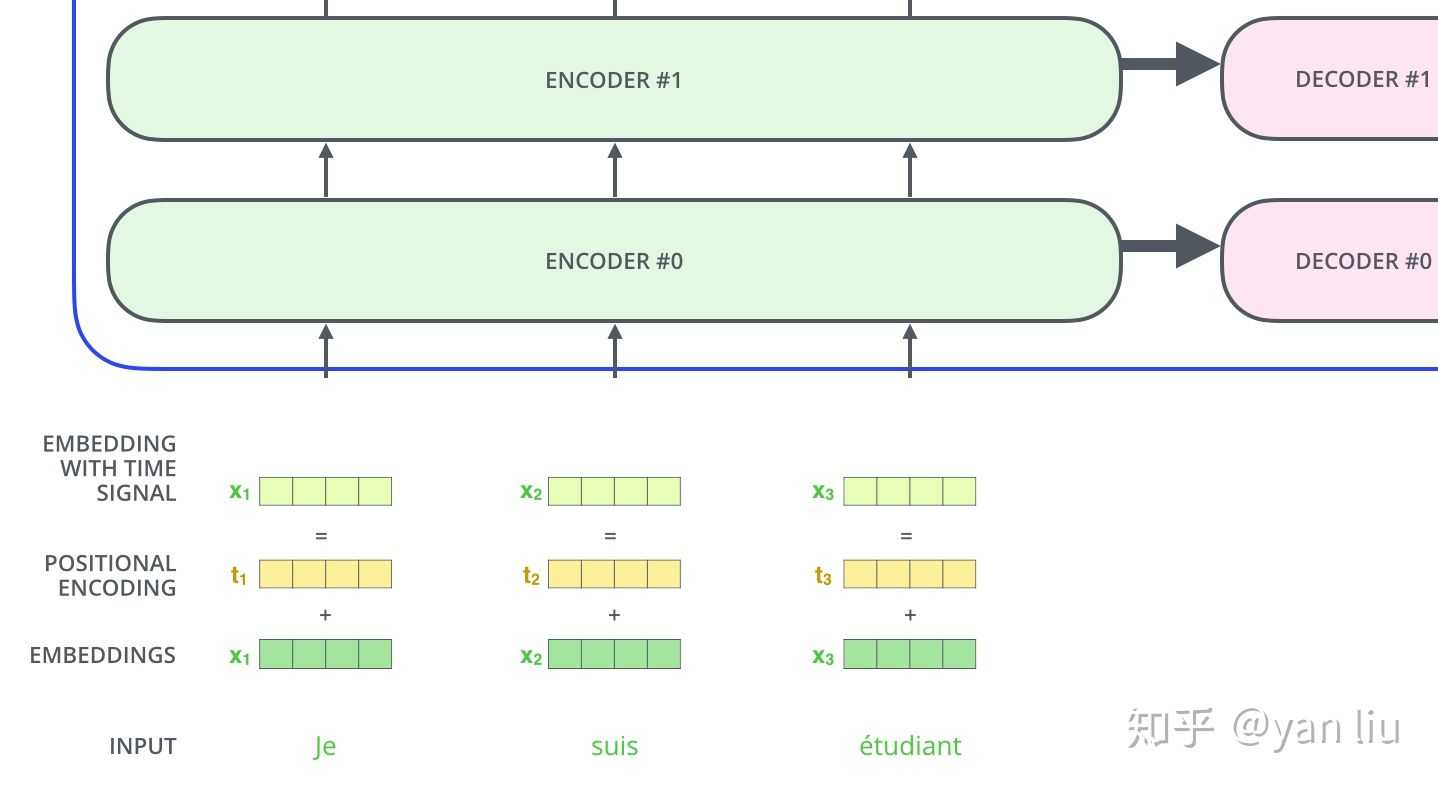
可以看到,嵌入向量和位置编码连接concat形成了最终的有 时间信号的嵌入。公式是这样的:
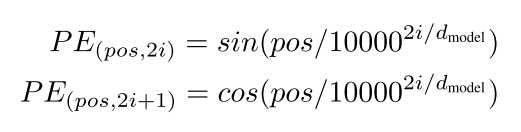
其中i是单词维度,dmodel是位置编码的维度,pos是单词的位置。那我就很迷惑了,针对一个单词它获取到的不就是一个标量值吗?何来位置向量呢?
《Attention is all you need》论文学习
标签:机制 为什么 实现 结构 产生 input forward 图片 token
原文地址:https://www.cnblogs.com/BlueBlueSea/p/12989866.html