标签:曲线 loss href 种子 label RoCE 位置 tps 设置
本节我们来利用卷积神经网络(CNN)来实现kaggle平台上的 CIFAR-10 - Object Recognition In Images 图像分类问题。
相关数据下载地址为:https://www.kaggle.com/c/cifar-10/data
新建 python3 文件 cifar_model_1
import 进相关模块并查看版本
%matplotlib inline import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import os import pandas as pd import sklearn import sys import tensorflow as tf import time from tensorflow import keras print(tf.__version__) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__, module.__version__)
代码运行如下:
2.0.0 sys.version_info(major=3, minor=7, micro=4, releaselevel=‘final‘, serial=0) matplotlib 3.1.1 numpy 1.16.5 pandas 0.25.1 sklearn 0.21.3 tensorflow 2.0.0 tensorflow_core.keras 2.2.4-tf
定义类别列表:
class_names = [ "airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck", ]
上述是个类别即是我们所有数据所属的类别。
# 文件夹 train_labels_file = ‘./cifar-10/trainLabels.csv‘ # 训练集对应的label test_csv_file = ‘./cifar-10/sampleSubmission.csv‘ # 最后要生成的预测文件 train_folder = ‘./cifar-10/train/train/‘ # 训练集 test_folder = ‘./cifar-10/test/test/‘ # 测试集 # 解析csv文件 def parse_csv_file(filepath, folder): ‘‘‘parse csv files into (filename(path),label) format‘‘‘ result = [] with open(filepath,‘r‘) as f: lines = f.readlines()[1:] #去掉header for line in lines: image_id, label_str = line.strip(‘\n‘).split(‘,‘) image_full_path = os.path.join(folder,image_id+‘.png‘) # 图片文件名 result.append((image_full_path,label_str)) return result # 读取图片信息 train_labels_info = parse_csv_file(train_labels_file, train_folder) test_csv_info = parse_csv_file(test_csv_file, test_folder) import pprint pprint.pprint(train_labels_info[0:5]) pprint.pprint(test_csv_info[0:5]) print(len(train_labels_info),len(test_csv_info))
代码执行结果如下:
[(‘./cifar-10/train/train/1.png‘, ‘frog‘), (‘./cifar-10/train/train/2.png‘, ‘truck‘), (‘./cifar-10/train/train/3.png‘, ‘truck‘), (‘./cifar-10/train/train/4.png‘, ‘deer‘), (‘./cifar-10/train/train/5.png‘, ‘automobile‘)] [(‘./cifar-10/test/test/1.png‘, ‘cat‘), (‘./cifar-10/test/test/2.png‘, ‘cat‘), (‘./cifar-10/test/test/3.png‘, ‘cat‘), (‘./cifar-10/test/test/4.png‘, ‘cat‘), (‘./cifar-10/test/test/5.png‘, ‘cat‘)] 50000 300000
可以看到我们的训练集有50000个数据,测试集有300000个数据。
而且我们也将训练集中的数据与对应的label通过函数 parse_csv_file 做了结合。
在这里我们还需要做的是:
1、将训练集与测试集变为DataFrame形式以便我们后期训练。
2、把训练集分为训练集(前45000张)与验证集(后5000张)
代码如下:
train_df = pd.DataFrame(train_labels_info[0:45000]) valid_df = pd.DataFrame(train_labels_info[45000:]) test_df = pd.DataFrame(test_csv_info) # 设置列名 train_df.columns = [‘filepath‘,‘class‘] valid_df.columns = [‘filepath‘,‘class‘] test_df.columns = [‘filepath‘,‘class‘]
# 查看前5个数据 print(train_df.head()) print(valid_df.head()) print(test_df.head())
代码执行结果如下:
filepath class 0 ./cifar-10/train/train/1.png frog 1 ./cifar-10/train/train/2.png truck 2 ./cifar-10/train/train/3.png truck 3 ./cifar-10/train/train/4.png deer 4 ./cifar-10/train/train/5.png automobile filepath class 0 ./cifar-10/train/train/45001.png horse 1 ./cifar-10/train/train/45002.png automobile 2 ./cifar-10/train/train/45003.png deer 3 ./cifar-10/train/train/45004.png automobile 4 ./cifar-10/train/train/45005.png airplane filepath class 0 ./cifar-10/test/test/1.png cat 1 ./cifar-10/test/test/2.png cat 2 ./cifar-10/test/test/3.png cat 3 ./cifar-10/test/test/4.png cat 4 ./cifar-10/test/test/5.png cat
五、数据预处理&读取图片
这里我们用keras里面的API来对图片做一些预处理操作以便后期训练,代码如下:
height = 32 # 图片高度 width = 32 # 图片宽度 channels = 3 # 图片通道数,一般都为RGB三通道 batch_size = 32 # 一批为32张图片 num_classes = 10 # 类别数 train_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode="nearest" ) train_generator = train_datagen.flow_from_dataframe(train_df, directory = ‘./‘, x_col = ‘filepath‘, y_col = ‘class‘, classes = class_names, target_size = (height,width), batch_size = batch_size, seed = 7, shuffle = True, class_mode = "sparse") valid_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255) valid_generator = valid_datagen.flow_from_dataframe(valid_df, directory = ‘./‘, x_col = ‘filepath‘, y_col = ‘class‘, classes = class_names, target_size = (height,width), batch_size = batch_size, seed = 7, shuffle = False, class_mode = "sparse") train_num = train_generator.samples valid_num = valid_generator.samples print(train_num, valid_num)
上面用到的keras.preprocessing.image.ImageDataGenerator API的作用主要是用来读取数据并做数据增强的。里面的一些主要参数介绍如下:
rescale = 1./255 的作用是将图片的像素点归一化到0到1之间。
rotation_range=40 意为将图片随机旋转的角度在0到40度之间。
width_shift_range = 0.2 意为将图片沿水平方向平移的距离为0到0.2的某个值。
height_shift_range = 0.2 意为将图片沿竖直方向平移的距离为0到0.2的某个值。
shear_range 为图片的剪切强度。
zoom_range 为缩放强度。
horizontal_flip 意为是否随机进行图片翻转。
fill_mode="nearest"指的是当对图像进行缩放时采用的插值法,这里用的是“就近插值法”。
上面用到的第二个API——train_datagen.flow_from_dataframe用来设置对图片数据进行训练时的一些参数,具体如下:
x_col 指的是数据那一列的列名,y_col指的是label那一列的列名。
classes为类别,这里根据列表class_name来实现类别与对应id的转化。
target_size为要处理的图片的大小。
batch_size为批量处理数据的数量。
seed是随机数种子。
shuffle为是否对训练集进行随机打乱顺序。
class_mode为数据类型,这里为稀疏(sparse)。
我们可以试着读取前两个train_generator来看看他的具体内容。代码如下:
for i in range(2): x,y = train_generator.next() print(x.shape,y.shape) print(y)
代码执行结果如下:
(32, 32, 32, 3) (32,) [2. 1. 4. 4. 4. 4. 6. 5. 2. 8. 4. 6. 6. 3. 7. 1. 7. 2. 8. 8. 3. 0. 5. 3. 9. 1. 4. 5. 6. 7. 9. 2.] (32, 32, 32, 3) (32,) [0. 7. 2. 7. 5. 5. 7. 0. 5. 4. 9. 7. 6. 3. 0. 4. 4. 4. 6. 3. 5. 4. 6. 6. 4. 1. 8. 2. 4. 4. 3. 0.]
x.shape(32,32,32,3)里面的参数依次代表(batch_size,height,width,channels),y.shape =(32,)即说明里面有32个数据的label。
在这里我们用卷积神经网络训练,代码如下:
model = keras.models.Sequential([ keras.layers.Conv2D(filters=128,kernel_size=3,padding="same", activation="relu",input_shape=[width,height,channels]), keras.layers.BatchNormalization(), keras.layers.Conv2D(filters=128,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.MaxPool2D(pool_size=2), keras.layers.Conv2D(filters=256,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.Conv2D(filters=256,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.MaxPool2D(pool_size=2), keras.layers.Conv2D(filters=512,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.Conv2D(filters=512,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.MaxPool2D(pool_size=2), keras.layers.Flatten(), keras.layers.Dense(512,activation="relu"), keras.layers.Dense(num_classes,activation="softmax") ]) # 配置训练学习过程,设置损失函数,优化器和训练指标 model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) model.summary()
在这里我们在每一层卷积神经网络(CNN)后面加一层批归一化以加快训练速度。
代码执行如下:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 32, 32, 128) 3584 _________________________________________________________________ batch_normalization (BatchNo (None, 32, 32, 128) 512 _________________________________________________________________ conv2d_1 (Conv2D) (None, 32, 32, 128) 147584 _________________________________________________________________ batch_normalization_1 (Batch (None, 32, 32, 128) 512 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 16, 16, 128) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 16, 16, 256) 295168 _________________________________________________________________ batch_normalization_2 (Batch (None, 16, 16, 256) 1024 _________________________________________________________________ conv2d_3 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ batch_normalization_3 (Batch (None, 16, 16, 256) 1024 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 8, 8, 256) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 8, 8, 512) 1180160 _________________________________________________________________ batch_normalization_4 (Batch (None, 8, 8, 512) 2048 _________________________________________________________________ conv2d_5 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ batch_normalization_5 (Batch (None, 8, 8, 512) 2048 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 4, 4, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 8192) 0 _________________________________________________________________ dense (Dense) (None, 512) 4194816 _________________________________________________________________ dense_1 (Dense) (None, 10) 5130 ================================================================= Total params: 8,783,498 Trainable params: 8,779,914 Non-trainable params: 3,584 _________________________________________________________________
接下来就对训练集进行训练,代码如下:
epochs = 20 history = model.fit_generator(train_generator, steps_per_epoch = train_num // batch_size, epochs = epochs, validation_data = valid_generator, validation_steps = valid_num // batch_size)
在这里由于计算速度的限制,我们暂且将遍历次数epochs设置为20。因为我们的网络层次较深,理论上来说epochs越大训练效果会越好。
代码执行如下:
poch 1/20 157/157 [==============================] - 5s 35ms/step - loss: 1.6870 - acc: 0.3806 1407/1407 [==============================] - 631s 449ms/step - loss: 2.5543 - acc: 0.2675 - val_loss: 1.6870 - val_acc: 0.3806 Epoch 2/20 157/157 [==============================] - 3s 18ms/step - loss: 1.7154 - acc: 0.4232 1407/1407 [==============================] - 91s 65ms/step - loss: 1.7151 - acc: 0.3767 - val_loss: 1.7154 - val_acc: 0.4232 Epoch 3/20 157/157 [==============================] - 3s 18ms/step - loss: 1.7433 - acc: 0.4360 1407/1407 [==============================] - 91s 65ms/step - loss: 1.5059 - acc: 0.4543 - val_loss: 1.7433 - val_acc: 0.4360 Epoch 4/20 157/157 [==============================] - 3s 18ms/step - loss: 1.1556 - acc: 0.6002 1407/1407 [==============================] - 91s 65ms/step - loss: 1.3400 - acc: 0.5198 - val_loss: 1.1556 - val_acc: 0.6002 Epoch 5/20 157/157 [==============================] - 3s 18ms/step - loss: 1.0857 - acc: 0.6226 1407/1407 [==============================] - 91s 65ms/step - loss: 1.1878 - acc: 0.5788 - val_loss: 1.0857 - val_acc: 0.6226 Epoch 6/20 157/157 [==============================] - 3s 18ms/step - loss: 1.0947 - acc: 0.6430 1407/1407 [==============================] - 91s 65ms/step - loss: 1.0565 - acc: 0.6303 - val_loss: 1.0947 - val_acc: 0.6430 Epoch 7/20 157/157 [==============================] - 3s 18ms/step - loss: 0.7530 - acc: 0.7496 1407/1407 [==============================] - 91s 65ms/step - loss: 0.9525 - acc: 0.6676 - val_loss: 0.7530 - val_acc: 0.7496 Epoch 8/20 157/157 [==============================] - 3s 18ms/step - loss: 1.2433 - acc: 0.6230 1407/1407 [==============================] - 91s 65ms/step - loss: 0.8687 - acc: 0.7010 - val_loss: 1.2433 - val_acc: 0.6230 Epoch 9/20 157/157 [==============================] - 3s 18ms/step - loss: 0.6869 - acc: 0.7760 1407/1407 [==============================] - 92s 65ms/step - loss: 0.8051 - acc: 0.7236 - val_loss: 0.6869 - val_acc: 0.7760 Epoch 10/20 157/157 [==============================] - 3s 18ms/step - loss: 0.7114 - acc: 0.7798 1407/1407 [==============================] - 92s 65ms/step - loss: 0.7481 - acc: 0.7428 - val_loss: 0.7114 - val_acc: 0.7798 Epoch 11/20 157/157 [==============================] - 3s 18ms/step - loss: 0.6984 - acc: 0.7746 1407/1407 [==============================] - 91s 65ms/step - loss: 0.7112 - acc: 0.7580 - val_loss: 0.6984 - val_acc: 0.7746 Epoch 12/20 157/157 [==============================] - 3s 19ms/step - loss: 0.5960 - acc: 0.8136 1407/1407 [==============================] - 93s 66ms/step - loss: 0.6698 - acc: 0.7698 - val_loss: 0.5960 - val_acc: 0.8136 Epoch 13/20 157/157 [==============================] - 3s 19ms/step - loss: 0.5687 - acc: 0.8196 1407/1407 [==============================] - 92s 65ms/step - loss: 0.6366 - acc: 0.7813 - val_loss: 0.5687 - val_acc: 0.8196 Epoch 14/20 157/157 [==============================] - 3s 18ms/step - loss: 0.7316 - acc: 0.7654 1407/1407 [==============================] - 91s 65ms/step - loss: 0.6090 - acc: 0.7940 - val_loss: 0.7316 - val_acc: 0.7654 Epoch 15/20 157/157 [==============================] - 3s 20ms/step - loss: 0.5415 - acc: 0.8276 1407/1407 [==============================] - 91s 65ms/step - loss: 0.5821 - acc: 0.8022 - val_loss: 0.5415 - val_acc: 0.8276 Epoch 16/20 157/157 [==============================] - 3s 18ms/step - loss: 0.6255 - acc: 0.8126 1407/1407 [==============================] - 92s 65ms/step - loss: 0.5611 - acc: 0.8073 - val_loss: 0.6255 - val_acc: 0.8126 Epoch 17/20 157/157 [==============================] - 3s 19ms/step - loss: 0.5124 - acc: 0.8350 1407/1407 [==============================] - 92s 65ms/step - loss: 0.5346 - acc: 0.8194 - val_loss: 0.5124 - val_acc: 0.8350 Epoch 18/20 157/157 [==============================] - 3s 18ms/step - loss: 0.5804 - acc: 0.8248 1407/1407 [==============================] - 92s 65ms/step - loss: 0.5129 - acc: 0.8261 - val_loss: 0.5804 - val_acc: 0.8248 Epoch 19/20 157/157 [==============================] - 3s 20ms/step - loss: 0.5762 - acc: 0.8194 1407/1407 [==============================] - 99s 71ms/step - loss: 0.4913 - acc: 0.8332 - val_loss: 0.5762 - val_acc: 0.8194 Epoch 20/20 157/157 [==============================] - 3s 19ms/step - loss: 0.5128 - acc: 0.8442 1407/1407 [==============================] - 101s 72ms/step - loss: 0.4836 - acc: 0.8359 - val_loss: 0.5128 - val_acc: 0.8442
可以看到最后的精度达到了80%以上。
为了更加直观的观察训练过程,我们可以将训练过程可视化,代码如下:
def plot_learning_curves(history, label, epcohs, min_value, max_value): data = {} data[label] = history.history[label] data[‘val_‘+label] = history.history[‘val_‘+label] pd.DataFrame(data).plot(figsize=(8, 5)) plt.grid(True) plt.axis([0, epochs, min_value, max_value]) plt.show() plot_learning_curves(history, ‘acc‘, epochs, 0, 1) plot_learning_curves(history, ‘loss‘, epochs, 0, 2)
代码执行结果如下:
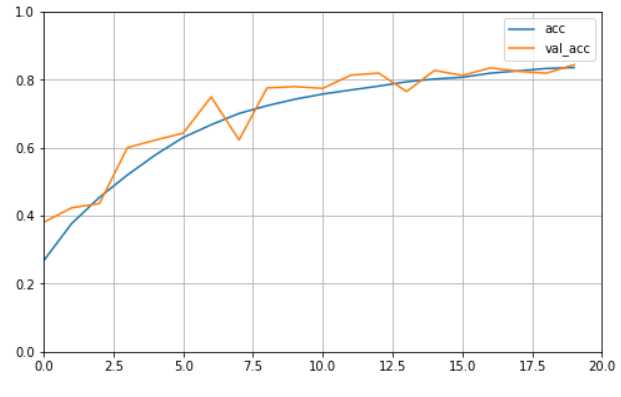
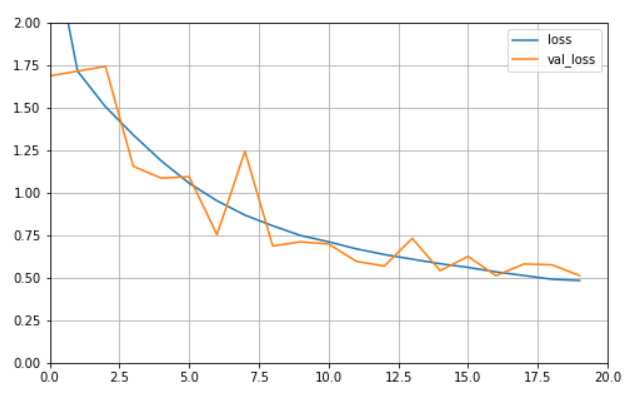
通过曲线图我们看到训练效果在随着epoch的增加在稳步上升。
接下来我们要对测试集中的数据进行预测。
首先我们应该对测试集中的数据作类似于训练基的数据预处理操作,代码如下:
test_datagen = keras.preprocessing.image.ImageDataGenerator( rescale = 1./255) test_generator = valid_datagen.flow_from_dataframe( test_df, directory = ‘./‘, x_col = ‘filepath‘, y_col = ‘class‘, classes = class_names, target_size = (height, width), batch_size = batch_size, seed = 7, shuffle = False, class_mode = "sparse") test_num = test_generator.samples print(test_num)
代码执行结果如下:
Found 300000 images belonging to 10 classes.
300000
可以看到测试集中包含300000张图片数据。
接下来进行预测:
test_predict = model.predict_generator(test_generator, workers = 10, use_multiprocessing = True
workers 代表并行度,use_multiprocessing = True 代表开启并行度为10的预测。
我们可以查看下预测结果的大小,代码如下:
print(test_predict.shape)
结果如下:
(300000, 10)
我们可以看到这是对于300000个数据的属于十个类别的概率分布。
我们可以打印一下前五个数据的预测结果,代码如下:
print(test_predict[0:5])
结果如下:
[[1.8115582e-02 3.0195517e-02 9.7707666e-02 2.2199485e-01 9.6216276e-02 1.4796969e-02 3.6596778e-01 2.3226894e-02 1.2524511e-02 1.1925392e-01] [9.3144512e-01 2.5595291e-04 3.6763612e-02 9.3153082e-03 9.9368917e-04 9.1112546e-05 1.5013785e-02 3.5342187e-04 5.2798474e-03 4.8821873e-04] [7.2171527e-04 8.8273185e-01 3.1592429e-06 1.9850962e-05 2.2674351e-06 1.8648565e-06 1.6326395e-06 1.5337924e-05 6.6775086e-05 1.1643546e-01] [1.7911234e-05 7.6694396e-06 7.3977681e-06 1.4877276e-06 1.0498322e-06 2.0850619e-07 1.4016325e-06 4.9560447e-07 9.9995601e-01 6.3446323e-06] [9.0831274e-01 1.8281976e-04 6.2809147e-02 1.6991662e-02 8.5249258e-04 4.1505805e-04 3.8536564e-03 6.0711574e-04 5.2569183e-03 7.1851560e-04]]
接下来我们要做的是将预测结果中十个概率值最大的位置对应的索引取出作为我们的预测结果,代码如下:
test_predict_class_indices = np.argmax(test_predict, axis = 1)
然后再取前五个值来观察,代码如下:
print(test_predict_class_indices[0:5])
代码执行结果如下:
[6 0 1 8 0]
然后再根据class_names 取出索引所对应的类别名称,代码如下:
test_predict_class = [class_names[index] for index in test_predict_class_indices]
然后再取前五个值来观察,代码如下:
print(test_predict_class[0:5])
代码执行结果如下:
[‘frog‘, ‘airplane‘, ‘automobile‘, ‘ship‘, ‘airplane‘]
基于kaggle平台的 CIFAR-10 - Object Recognition in Images 分类问题
标签:曲线 loss href 种子 label RoCE 位置 tps 设置
原文地址:https://www.cnblogs.com/sunny0824/p/12989725.html