标签:需要 location bcf word ber class 实例 实体 搭建
ORM(Object-Relational Mapping) 表示对象关系映射。在面向对象的软件开发中,通过ORM,就可以把对象映射到关系型数据库中。只要有一套程序能够做到建立对象与数据库的关联,操作对象就可以直接操作数据库数据,就可以说这套程序实现了ORM对象关系映射。
简单的说:ORM就是建立实体类和数据库表之间的关系,从而达到操作实体类就相当于操作数据库表的目的(就是说ORM会把MySQL表映射成一个java对象,使开发人员可以关注java程序)。
当实现一个应用程序时(不使用O/R Mapping),我们可能会写特别多数据访问层的代码(各种各样的DAO类),从数据库增删改查等操作,而这些代码都是重复的。但使用ORM框架则会大大减少重复性代码。对象关系映射(Object Relational Mapping,简称ORM),主要实现程序对象到关系数据库数据的映射。
优点:
①:提高开发效率,降低开发成本 (减少了DAO类的操作)
②:使开发更加对象化 (直接在实体类domain中来映射关系)
③:可移植
④:可以很方便地引入数据缓存之类的附加功能
缺点:
①:自动化进行关系数据库的映射需要消耗系统性能。消耗的性能可以忽略不记
②:在处理多表联查、where条件复杂之类的查询时,ORM的语法会变得复杂。(这才是最致命的缺点)
如:JDBC、Hibernate、MyBatis(ibatis)、TopLink、JPA(对ORM框架的再一次封装,这里是一套规范)
JDBC:其实JDBC是最原生的API,支持连接并操作各种关系型数据库,也就是说可以用JDBC完成ORM思想的程序编写,如一些有ORM思想的框架底层
都调用JDBC,所有这个JDBC我对其理解为ORM思想
Hibernate:这个框架就不用多说了,完全使用ORM思想,不过现在直接使用hibernate的少了,大多都是在JPA的封装上调用此框架
MyBatis:用过Mybatis都知道,这个框架可以手动写SQL语句,也可以完成对象关系映射,其实严格上说Mybatis不完全是一个ORM框架,包括后面
介绍JPA的供应商就不支持Mybatis
JPA的全称是Java Persistence API, 即Java 持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成。
JPA通过JDK 5.0注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。

1. 标准化 JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能够在不同的JPA框架下运行。 2. 容器级特性的支持 JPA框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的局限,在企业应用发挥更大的作用。 3. 简单方便 JPA的主要目标之一就是提供更加简单的编程模型:在JPA框架下创建实体和创建Java 类一样简单,没有任何的约束和限制,只需要使用 javax.persistence.Entity进行注释,JPA的框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。JPA基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成 4. 查询能力 JPA的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是Hibernate HQL的等价物。JPA定义了独特的JPQL(Java Persistence Query Language),JPQL是EJB QL的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。 5. 高级特性 JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性在关系数据库的持久化。
在上面我介绍到JPA其实是一套ORM规范,可不是ORM框架哟,因为当前JPA并未实现ORM思想的框架,它只是定义了一些规范,提供了一些编程的API接口,要具体实现的话必须指定服务厂商(供应商)来提高实现
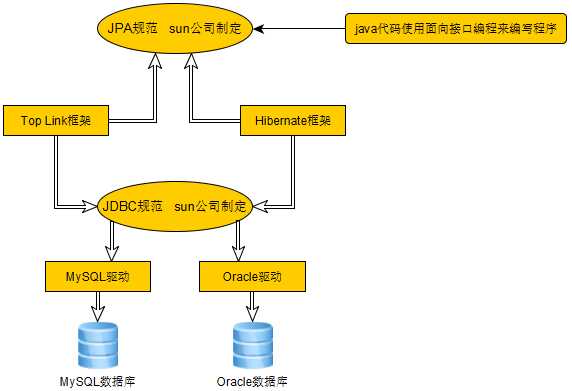
JPA和Hibernate的关系就像JDBC和JDBC实现的驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。JPA怎么取代Hibernate呢?JDBC规范可以驱动底层数据库吗?答案是否定的,也就是说,如果使用JPA规范进行数据库操作,底层需要hibernate作为其实现类完成数据持久化工作。
我们知道JPA只是一套规范,它必须借助外部的实现厂家来完成一系列的操作,所有我在接下来的全部操作中的实现厂家就选用Hibernate框架来完成。
①:准备工作
首先得建立一个maven的项目,然后再顺手建立一个数据库及表,为后期准备,然后再去maven仓库找到相应坐标
-- 删除库 -- drop database demo_jpa; -- 创建库 create database if not exists demo_jpa charset gbk collate gbk_chinese_ci; -- 使用库 use demo_jpa; -- 创建表 create table if not exists student( sid int primary key auto_increment, -- 主键id sname varchar(10) not null, -- 姓名 sage tinyint unsigned default 22, -- 年龄 smoney decimal(6,1), -- 零花钱 saddress varchar(20) -- 住址 )charset gbk collate gbk_chinese_ci; insert into student values(1,"蚂蚁小哥",23,8888.8,"安徽大别山");
②:导入坐标
<!--单元测试坐标--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> <!--hibernate EntityManager是围绕提供JPA编程接口的Hibernate Core的一个包装 支持JPA实体实例的生命周期,并允许你用标准的Java Persistence查询语言编写查询--> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>5.4.10.Final</version> </dependency> <!--hibernate集成C3P0连接池坐标--> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-c3p0</artifactId> <version>5.4.10.Final</version> </dependency> <!--mysql驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.32</version> </dependency>
③:编写一个JPA的配置文件
<?xml version="1.0" encoding="UTF-8"?> <persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0"> <!--写在前面:这个配置文件必须放在资源目录(resources)下的META-INF里面,且配置文件名必须为persistence.xml--> <!--提示:这里的约束在IDEA里面已经存在了 右击找到New ==> File and Code Templates ==>JPA==> Deployment descriptors==>persistence_2_0.xml--> <!--第一步:配置persistence-unit标签 name:持久化单元名称,自己定义,后期通过name来查找当前的文件配置 transaction-type:事务管理方实 JPA:分布式事务管理(只有JPA集群的时候要写,要不然事务无效(数据库在多台服务器上)) RESOURCE_LOCAL:本地事务(数据库就在一台服务上) --> <persistence-unit name="MyJPA_01" transaction-type="RESOURCE_LOCAL"> <!--第二步:这里告诉了JPA,它的实现厂家是哪个 provider标签就是供应商的意思--> <provider>org.hibernate.jpa.HibernatePersistenceProvider</provider> <!--第三步:配置JPA的基本信息--> <properties> <!--配置连接数据库的四大属性 必须以javax.persistence.jdbc前缀 --> <property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/> <property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/demo_jpa"/> <property name="javax.persistence.jdbc.user" value="root"/> <property name="javax.persistence.jdbc.password" value="123"/> <!--JPA实现方的配置信息 hibernate.show_sql:是否在控制台上显示操作的SQL语句 true AND false hibernate.format_sql:是否对打印在控制台上的SQL语句进行格式化(前提要显示SQL) true AND false hibernate.hbm2ddl.auto:数据库表创建方式 create:配置文件被加载时,会把原来对应的表删除后再创建(表信息也将删除),没有表则创建新的表 update:配置文件被加载时,有对应的表则不创建,没有表则创建一个新的表 none:和没写一样,有表就正常操作,找不到对应的表就报错 这里重要阐述一下:设置create在有(严格)外键约束的情况下,是无法删除表在创建的,所有这个时候的性能和update一样 --> <property name="hibernate.show_sql" value="true"/> <property name="hibernate.format_sql" value="true"/> <property name="hibernate.hbm2ddl.auto" value="create"/> </properties> </persistence-unit> </persistence>
④:编写实体类并且映射关系
/** * @Entity: 声明实体类 * @Table: 配置实体类与表的关系 * name:当前对应的数据库表的名称 */ @Entity @Table(name = "student") public class Student { /** * @Id: 声明当前字段为主键 * @GeneratedValue 配置主键生成策略 * GenerationType.SEQUENCE:自增,mysql可以用 * GenerationType.IDENTITY:序列,oracle可以用 * GenerationType.TABLE:jpa提供的一种机制,通过一张表的方式来帮我们完成主键自增 * GenerationType.AUTO:由程序自动帮我们完成 * @Column: 指定实体类属性和数据库表之间的对应关系 * name:指定数据库表的列名称。 * unique:是否唯一 * nullable:是否可以为空 * inserttable:是否可以插入 * updateable:是否可以更新 * columnDefinition: 定义建表时创建此列的DDL * secondaryTable: 从表名。如果此列不建在主表上(默认建在主表), * 该属性定义该列所在从表的名字搭建开发环境[重点] */ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private int id; // 主键 自增长 @Column(name = "sname") private String name; //姓名 @Column(name = "sage") private int age; //年龄 @Column(name = "smoney") private double money; //零花钱 @Column(name = "saddress") private String address; //住址 //后面省略构造方法/get/set/toString }
⑤:测试代码
public class Client { public static void main(String[] args) {} @Test //这个使用单元测试 而且pom.xml坐标的范围仅供测试 public void createStudent(){ //此静态方法执行后会找到“MyJPA_01”的名字配置,然后根据配置文件来创建工厂(实体管理器)对象 EntityManagerFactory factory = Persistence.createEntityManagerFactory("MyJPA_01"); //通过实体管理器工厂来生产(创建)一个实体管理器 EntityManager entityManager = factory.createEntityManager(); //通过实体管理器获取一个事务对象 EntityTransaction transaction = entityManager.getTransaction(); //开启事务 transaction.begin(); //创建一个实体对象,后面保存 Student student=new Student(0,"谢霆锋",30,8888.6,"北京顺义"); //保存方法 entityManager.persist(student); //提交事务 transaction.commit(); //先关闭实体管理器后关闭工厂 entityManager.close(); factory.close(); } }
在完成上面的入门程序后,就会知道在实体类里面有@GeneratedValue这个注解,它是用来生成主键的方式,在不同的数据库上使用不同的生成策略
JPA提供的四种标准用法为 TABLE,SEQUENCE,IDENTITY,AUTO
1:IDENTITY:主键由数据库自动生成(主要是自动增长型【MySQL就支持此写法】)
@Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private int id; // 主键 自增长
2:SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列(【Oracle就支持此写法】)
@Id @GeneratedValue(strategy = GenerationType.SEQUENCE,generator = "id_seq") @SequenceGenerator(name="id_seq",sequenceName = "sid_seq") @Column(name = "sid") private int id; // 主键 序列
//@SequenceGenerator注解源码中的定义 @Repeatable(SequenceGenerators.class) @Target({ElementType.TYPE, ElementType.METHOD, ElementType.FIELD}) @Retention(RetentionPolicy.RUNTIME) public @interface SequenceGenerator { //表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的"generator"值中 String name(); //属性表示生成策略用到的数据库序列名称 我当前的Oracle数据库指定表的序列是"sid_seq"。 String sequenceName() default ""; //数据库catalog的名称 String catalog() default ""; //数据库schema的名称 String schema() default ""; //表示主键初识值,默认为0 int initialValue() default 1; //表示每次主键值增加的大小,例如设置1,则表示每次插入新记录后自动加1,默认为50 int allocationSize() default 50; }
3:TABLE:使用一个特定的数据库表格来保存主键
@Id @GeneratedValue(strategy = GenerationType.TABLE,generator = "tb_table") @TableGenerator( name="tb_table", table = "tb_generator", pkColumnName = "gen_key", pkColumnValue = "student_pk", valueColumnName="gen_value", initialValue = 0, allocationSize = 1 ) @Column(name = "sid") private int id; // 主键 手动设置表
//@TableGenerator注解源码介绍 @Repeatable(TableGenerators.class) @Target({ElementType.TYPE, ElementType.METHOD, ElementType.FIELD}) @Retention(RetentionPolicy.RUNTIME) public @interface TableGenerator { //表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的"generator"值中 String name(); //表示表生成策略所持久化的表名,例如,这里表使用的是数据库中的"tb_generator"表名。 String table() default ""; //catalog和schema具体指定表所在的目录名或是数据库名 String catalog() default ""; String schema() default ""; //属性的值表示在持久化表中,该主键生成策略所对应键值的名称。例如在"tb_generator"中将"gen_key"作为主键的键值 String pkColumnName() default ""; //属性的值表示在持久化表中,该生成策略所对应的主键。例如在"tb_generator"表中,将"gen_key"的值为"student_pk"。 String pkColumnValue() default ""; //属性的值表示在持久化表中,该主键当前所生成的值,它的值将会随着每次创建累加。 //例如,在"tb_generator"中将"gen_value"作为主键的值 String valueColumnName() default ""; //表示主键初识值,默认为0。 int initialValue() default 0; //表示每次主键值增加的大小,例如设置成1,则表示每次创建新记录后自动加1,默认为50。 int allocationSize() default 50; UniqueConstraint[] uniqueConstraints() default {}; Index[] indexes() default {}; }
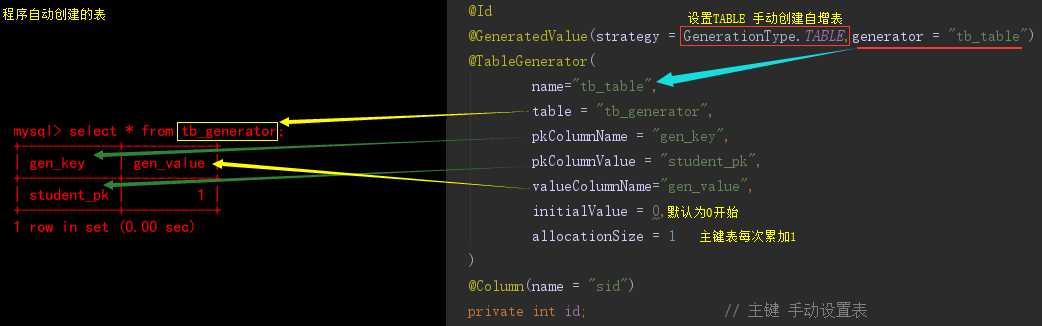
mysql> describe tb_generator;
+-----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+-------+
| gen_key | varchar(255) | NO | PRI | NULL | |
| gen_value | bigint(20) | YES | | NULL | |
+-----------+--------------+------+-----+---------+-------+
上面的这种方式就是自己设置主键引用表,那么这也太麻烦了吧,其实还有一种简单的,但是灵活性不如这个,下面我就介绍自动创建吧!
4:AUTO:主键由程序控制
@Id @GeneratedValue(strategy = GenerationType.AUTO) @Column(name = "sid") private int id; // 主键
mysql> select * from hibernate_sequence; +----------+ | next_val | +----------+ | 2 | +----------+ 1 row in set (0.00 sec) mysql> describe hibernate_sequence; +----------+------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+------------+------+-----+---------+-------+ | next_val | bigint(20) | YES | | NULL | | +----------+------------+------+-----+---------+-------+ 1 row in set (0.01 sec)
Persistence对象主要作用是用于获取EntityManagerFactory对象的 。通过调用该类的createEntityManagerFactory静态方法,根据配置文件中持久化单元名称创建EntityManagerFactory。
//此静态方法执行后会找到“MyJPA_01”的名字配置,然后根据配置文件来创建工厂(实体管理器)对象 EntityManagerFactory factory = Persistence.createEntityManagerFactory("MyJPA_01");
EntityManagerFactory(工厂) 接口主要用来创建 EntityManager 实例。由于EntityManagerFactory 是一个线程安全的对象(即多个线程访问同一个EntityManagerFactory 对象不会有线程安全问题),并且EntityManagerFactory 的创建极其浪费资源,所以在使用JPA编程时,我们可以对EntityManagerFactory 的创建进行优化,只需要做到一个工程只存在一个EntityManagerFactory 即可,后面编写工具类
//此静态方法执行后会找到“MyJPA_01”的名字配置,然后根据配置文件来创建工厂(实体管理器)对象 EntityManagerFactory factory = Persistence.createEntityManagerFactory("MyJPA_01"); //通过实体管理器工厂来生产(创建)一个实体管理器 EntityManager entityManager = factory.createEntityManager();
在 JPA 规范中, EntityManager是完成持久化操作的核心对象。实体类作为普通 java对象,只有在调用 EntityManager将其持久化后才会变成持久化对象。EntityManager对象在一组实体类与底层数据源之间进行 O/R 映射的管理。它可以用来管理和更新 Entity Bean, 根椐主键查找 Entity Bean, 还可以通过JPQL语句查询实体。我们可以通过调用EntityManager的方法完成获取事务,以及持久化数据库的操作
getTransaction : 获取事务对象
persist : 保存操作
merge : 更新操作
remove : 删除操作
find/getReference : 根据id查询
在 JPA 规范中, EntityTransaction是完成事务操作的核心对象,对于EntityTransaction在我们的java代码中承接的功能比较简单
begin: 开启事务
commit: 提交事务
rollback: 回滚事务
在前面我们在创建实体管理类都特别麻烦,而且每次都加载配置文件,这显然影响了性能,那在程序第一次创建实体管理类后就创建对象,后期直接使用就行了,那就可以减小性能损耗
public class JPAUtils { //聚合一个工厂管理类 private static EntityManagerFactory factory; //静态方法 在一执行就加载并创建工厂管理类 static{ factory = Persistence.createEntityManagerFactory("MyJPA_01"); } //返回对象 public static EntityManager getEntityManager(){ //返回一个实体管理类对象EntityManager return factory.createEntityManager(); } }
下面的操作我使用入门实例的代码和后面编写的JPAUtils工具类完成代码操作,因为我使用的是MySQL数据库,所有我的主键增长策略就使用@GeneratedValue(strategy = GenerationType.IDENTITY),配置文件的创建表模式设置 update,并且 <property name="hibernate.format_sql" value="true"/>注释 不让打印在控制台上的sql语句格式化
方法: void persist(Object var1); 传入一个带有映射关系的对象即可进行添加数据
@Test //这个使用单元测试 而且pom.xml坐标的范围仅供测试 public void createStudent(){ //通过调用工具类来返回一个实体管理器 EntityManager entityManager = JPAUtils.getEntityManager(); //通过实体管理器获取一个事务对象 EntityTransaction transaction = entityManager.getTransaction(); //开启事务 transaction.begin(); //创建一个实体对象,后面保存 Student student=new Student(0,"迪丽热巴",30,8888.8,"北京顺义"); //保存方法 entityManager.persist(student); //提交事务 transaction.commit(); //关闭实体管理器 工厂属于公用的所有不能关闭 entityManager.close(); }
方法:
<T> T merge(T var1); 传入一个要更新的实体类 然后更新
@Test //这个使用单元测试 而且pom.xml坐标的范围仅供测试 public void mergeStudent(){ //通过调用工具类来返回一个实体管理器 EntityManager entityManager = JPAUtils.getEntityManager(); //通过实体管理器获取一个事务对象 EntityTransaction transaction = entityManager.getTransaction(); //开启事务 transaction.begin(); /* 更新数据: <T> T find(Class<T> var1, Object var2);后面说到查询会详细说 为什么会先查询后更新呢?因为方便,我现在如果要更新id为1的学生的姓名, 那么如果我自己创建一个student对象,但是其它信息不确定,所有我就把数据全部 查询出来通过set方法设置后再传入更新 */ Student student = entityManager.find(Student.class, 1); System.out.println("更新前的学生:"+student); student.setName("王二麻"); student.setAddress("伊拉克"); Student merge = entityManager.merge(student); System.out.println("更新后的学生:"+merge); //提交事务 transaction.commit(); //关闭实体管理器 工厂属于公用的所有不能关闭 entityManager.close(); //更新前的学生:Student{id=1, name=‘蚂蚁小哥‘, age=23, money=8888.8, address=‘安徽大别山‘} //更新后的学生:Student{id=1, name=‘王二麻‘, age=23, money=8888.8, address=‘伊拉克‘} }
方法: void remove(Object var1); 传入一个要删除的实体类,然后删除
@Test //这个使用单元测试 而且pom.xml坐标的范围仅供测试 public void removeStudent(){ //通过调用工具类来返回一个实体管理器 EntityManager entityManager = JPAUtils.getEntityManager(); //通过实体管理器获取一个事务对象 EntityTransaction transaction = entityManager.getTransaction(); //开启事务 transaction.begin(); //删除操作 先把指定id查询出来一个对象,然后把对象丢到删除方法上 Student student = entityManager.find(Student.class, 1); entityManager.remove(student); //提交事务 transaction.commit(); //关闭实体管理器 工厂属于公用的所有不能关闭 entityManager.close(); }
查询方法:(立即加载) <T> T find(Class<T> var1, Object var2); var1:传入一个查询的类型字节码文件,var2:传入一个指定的查询主键ID 常用 <T> T find(Class<T> var1, Object var2, Map<String, Object> var3); <T> T find(Class<T> var1, Object var2, LockModeType var3); <T> T find(Class<T> var1, Object var2, LockModeType var3, Map<String, Object> var4);
查询方法:(延迟加载) <T> T getReference(Class<T> var1, Object var2); var1:传入一个查询的类型字节码文件,var2:传入一个指定的查询主键ID 常用
@Test //这个使用单元测试 而且pom.xml坐标的范围仅供测试 public void findStudent(){ //通过调用工具类来返回一个实体管理器 EntityManager entityManager = JPAUtils.getEntityManager(); //立即加载 Student studentA = entityManager.find(Student.class, 2); //延迟加载 Student studentB = entityManager.getReference(Student.class, 2); /* 区别: find是立即加载,一旦执行entityManager.find(...)就会去数据库查询,然后把对象封装到接收对象上 getReference:是懒加载:一旦执行不会立即去数据库查询,而是等到后面某一行代码要使用到这个查询信息的时候 才去数据库做真正的查询 懒加载的方式是基于代理方式完成懒加载的,一般我们都使用懒加载,因为有些查询的数据从头到尾都没使用到, 那么懒加载就不会浪费查询性能,但是有些数据查询后立马或者某个地方确定要使用则可使用立即加载 */ //关闭实体管理器 工厂属于公用的所有不能关闭 entityManager.close(); }

方法:
①:createNativeQuery (String sqlString) Query
②:createNativeQuery (String sqlString, Class resultClass) Query
③:createNativeQuery (String sqlString, String resultClass) Query
参数介绍:
String sqlString:这个是传入最基本的sql语句(原生SQL)
Class resultClass:传入指定映射的对象
String resultClass:传入字符串的映射关系(前提得在类上注解指定)
返回值:
Query:是一个和数据库打交道的对象,里面封装各种执行SQL语句及操作
介绍:createNativeQuery其实是用来封装原生的SQL语句,返回Query对象,然后通过Query对象进行增删改查,没错就是增删改查,从官方上理解说是标量原生查询,可包含简单的SQL和复杂的SQL查询,而且还可以增删改
①:Query createNativeQuery(String sqlString) (完成简答增删改查)
@Test public void createNativeQueryTest() { //通过调用工具类来返回一个实体管理器 EntityManager entityManager = JPAUtils.getEntityManager(); //获取事务并开启事务 EntityTransaction transaction = entityManager.getTransaction(); transaction.begin(); //------------------------------------------------------------- //增加数据: String sql_insert = "insert into student (sname,sage,smoney,saddress) values(?1,?2,?3,?4)"; //封装原生SQL代码 并设置占位符数据 Query query_insert = entityManager.createNativeQuery(sql_insert); query_insert.setParameter(1,"王小二"); query_insert.setParameter(2,25); query_insert.setParameter(3,1234.5); query_insert.setParameter(4,"江苏连云港"); //调用添加操作 int i_insert = query_insert.executeUpdate(); System.out.println("成功数:"+i_insert); //删除操作 String sql_delete="delete from student where sid=?1"; Query query_delete = entityManager.createNativeQuery(sql_delete); query_delete.setParameter(1,8); //调用删除操作 int i_delete = query_delete.executeUpdate(); System.out.println("删除成功数:"+i_delete); //更新操作 String sql_update="update student set sname=?1 where sid=?2"; Query query_update = entityManager.createNativeQuery(sql_update); query_update.setParameter(1,"妲己"); query_update.setParameter(2, 3); int i_update = query_update.executeUpdate(); System.out.println("更新成功数:"+i_update); //查询操作 多个 Query query_select = entityManager.createNativeQuery("select * from student"); //返回的数据默认就是List<Object[]> 直接写List也是返回List<Object[]> List<Object[]> list = query_select.getResultList(); for(Object[] o:list){ System.out.println(Arrays.toString(o)); } //查询操作 单个 Query nativeQuery = entityManager.createNativeQuery("select * from student where sid=2"); //默认返回的是Object类型 但是必须后面转为Object[] 才可以使用 Object student = nativeQuery.getSingleResult(); System.out.println(Arrays.toString((Object[])student)); //------------------------------------------------------------- //提交事务 transaction.commit(); //关闭实体管理器 工厂属于公用的所有不能关闭 entityManager.close(); }
注:上面的一段代码必须要实现事务(查询除外)否则会报异常
②:Query createNativeQuery(String sqlString,Class resultClass) (返回的结果被映射成指定类型)
@Test public void createNativeQueryTest() { //通过调用工具类来返回一个实体管理器 EntityManager entityManager = JPAUtils.getEntityManager(); //查询全部 Query query = entityManager.createNativeQuery("select * from student", Student.class); List<Student> students = query.getResultList(); for(Student s:students){ System.out.println(s); } //这个使用query调用getSingleResult() 返回单个对象 //Object student = query.getSingleResult(); //关闭实体管理器 工厂属于公用的所有不能关闭 entityManager.close(); }
第三种方式就相当复杂点,我这里借鉴一篇文章
①:首先我来介绍一下JPQL语法
JPQL 语言,即 Java Persistence Query Language 的简称。JPQL 和 HQL 是非常类似的,支持以面向对象的方式来写 SQL 语句,当然也支持本地的 SQL 语句。JPQL 最终会被编译成针对不同底层数据库的 SQL 查询从而屏蔽掉不同数据库的差异。
那么语法是什么样的呢?其实这语法和SQL语句大同小异
数据库表: +-----+----------+------+--------+------------+ | sid | sname | sage | smoney | saddress | +-----+----------+------+--------+------------+ | 1 | 蚂蚁小哥 | 23 | 8888.8 | 安徽大别山 | | 2 | 王二麻 | 21 | 7777.8 | 安徽大别山 | | 3 | 王晓爱 | 25 | 6666.8 | 安徽大别山 | | 4 | 霍元甲 | 24 | 5555.8 | 安徽大别山 | | 5 | 叶问 | 26 | 4444.8 | 安徽大别山 | | 6 | 李连杰 | 28 | 3333.8 | 安徽大别山 | | 7 | 马克思 | 20 | 2222.8 | 安徽大别山 | | 9 | 王小二 | 25 | 1234.5 | 江苏连云港 | +-----+----------+------+--------+------------+ 映射关系 @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private int id; // 主键 @Column(name = "sname") private String name; //姓名 @Column(name = "sage") private int age; //年龄 @Column(name = "smoney") private double money; //零花钱 @Column(name = "saddress") private String address; //住址 1:查询全部 select s form Student; from Student; from cn.xw.domain.Student; 2:查询id为2,6,9的 from Student where id in(2,6,9); 3:查询id在2到6之间 from Student where id between 2 and 3 4:模糊查询 from Student where name like "%张%"; 上面我简单的列举了几个,这里注意的是Student必须是类名,且JPQL语句任何地方都不能使用?号代替
②:Query接口方法介绍
第一组: 功能:用来设置占位符指定的数据 Query setParameter(int position, Object value); 这个是最常用的√ <T> Query setParameter(Parameter<T> param, T value); Query setParameter(Parameter<Calendar> param, Calendar value, TemporalType temporalType); Query setParameter(Parameter<Date> param, Date value, TemporalType temporalType); Query setParameter(String name, Object value); Query setParameter(String name, Calendar value, TemporalType temporalType); Query setParameter(String name, Date value, TemporalType temporalType); Query setParameter(int position, Calendar value,TemporalType temporalType); Query setParameter(int position, Date value, TemporalType temporalType); 例如: Query query = entityManager.createQuery("from Student where sid=?1"); query.setParameter(1, 3); /*------------------------------------------------------------------------------------------------------------*/ 第二组: 功能:用来进行分页操作,对查询的整张表指定从索引某处到某处 Query setMaxResults(int maxResult); //当前要查询几条记录数 int getMaxResults(); Query setFirstResult(int startPosition); //当前的查询起始位 int getFirstResult(); 介绍:上面set是设置值 get是返回值 例如: Query query = entityManager.createQuery("from Student"); query.setFirstResult(2); //从表第二条记录数查询 query.setMaxResults(2); //查询2条记录数 limit 2,2 /*------------------------------------------------------------------------------------------------------------*/ 第三组: 功能:用来对查询的返回一条数据或多条数据 List getResultList(); //返回查询的多条记录封装到集合 Object getSingleResult(); //返回查询的单条记录赋值给Object /*------------------------------------------------------------------------------------------------------------*/ 第四组: 功能:用来对数据的增删改 int executeUpdate(); /*------------------------------------------------------------------------------------------------------------*/ 第五组: 功能返回第二组设置在上面的值 Set<Parameter<?>> getParameters(); Parameter<?> getParameter(String name); <T> Parameter<T> getParameter(String name, Class<T> type); Parameter<?> getParameter(int position); <T> Parameter<T> getParameter(int position, Class<T> type); <T> T getParameterValue(Parameter<T> param); Object getParameterValue(String name); Object getParameterValue(int position);
####进入正题
①:查询全部数据
@Test public void Test() { //通过调用工具类来返回一个实体管理器 EntityManager em = JPAUtils.getEntityManager(); Query query = em.createQuery("from cn.xw.domain.Student"); List list = query.getResultList(); for (Object o : list) { System.out.println(o); } //关闭实体管理器 工厂属于公用的所有不能关闭 em.close(); }
②:模糊查询
@Test public void Test() { //通过调用工具类来返回一个实体管理器 EntityManager em = JPAUtils.getEntityManager(); Query query = em.createQuery("from Student where name like ?1"); query.setParameter(1,"%二%"); //设置占位符数据 List list = query.getResultList(); for (Object o : list) { System.out.println(o); } //关闭实体管理器 工厂属于公用的所有不能关闭 em.close(); }
看一段相似的段代码介绍:大家会发现我SQL语句 "insert into student (sname,sage,smoney,saddress) values(?1,?2,?3,?4)"
都写一些?1,?2的,这是为了防止报异常,这个"?"后面加数字的都是在一些较高版本的Hibernate的规范,低版本如5.0.1..等不需要加入,
后面的输入无所谓“ ?18 , ?26 , ?19....”,这些随便数字都没问题,但是后面在参数赋值上对应上每个地方就行,说白了这个就是为了可以准确匹配设置参数的位置。
这和我们上面的模糊查询的?1也有相似情况,大家注意
④:分页查询
@Test public void Test() { //通过调用工具类来返回一个实体管理器 EntityManager em = JPAUtils.getEntityManager(); Query query = em.createQuery("from Student"); query.setFirstResult(2); //这条语句和下条语句代表 limit 2 ,4 query.setMaxResults(4); List list = query.getResultList(); for (Object o : list) { System.out.println(o); } //关闭实体管理器 工厂属于公用的所有不能关闭 em.close(); }
④:统计查询(查询学生人数)
@Test public void Test() { //通过调用工具类来返回一个实体管理器 EntityManager em = JPAUtils.getEntityManager(); Query query = em.createQuery("select count(id) from Student"); Object result = query.getSingleResult(); System.out.println("学生总数:"+result); //关闭实体管理器 工厂属于公用的所有不能关闭 em.close(); }
⑤:删除操作
@Test public void Test() { //通过调用工具类来返回一个实体管理器 EntityManager em = JPAUtils.getEntityManager(); //获取事务并开启 EntityTransaction transaction = em.getTransaction(); transaction.begin(); String sql="delete from Student where id=?1"; Query query = em.createQuery(sql); query.setParameter(1,3); query.executeUpdate();//开始执行 删除第三条记录 //提交事务 transaction.commit(); //关闭实体管理器 工厂属于公用的所有不能关闭 em.close(); }
.
标签:需要 location bcf word ber class 实例 实体 搭建
原文地址:https://www.cnblogs.com/antLaddie/p/12985708.html
