标签:ade mbed obj define rmi return oid 过程 内存分配
redis的每种数据类型都有起码两种底层编码
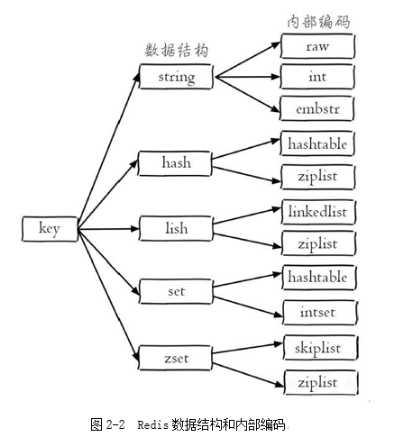
Redis 并没有直接使用这些数据结构来实现键值对的数据库,而是在这些数据结构之上又包装了一层 RedisObject(对象),每种数据类型对应一种redisObject对象
下面以Sting数据类型,来说明一下String数据类型创建的过程
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */
## 这里lru属性要不保存 LRU的信息 ,要不保存LFU的信息
## 最大24位无法保存完整的时间戳信息
## 所以,当保存LRU信息的时候,保存时间戳的低24位,最多能几多194天
## 当保存LFU信息的时候,高16位保存时间戳的低16位信息, 低8位保存访问频率,简称counter
## 但是由什么来决定呢?
## 请看下图
int refcount; void *ptr; } robj;
robj *createObject(int type, void *ptr) { robj *o = zmalloc(sizeof(*o)); o->type = type; ## 数据类型 o->encoding = OBJ_ENCODING_RAW; ## redis每种数据类型的内部编码,默认使用RAW的内部编码 o->ptr = ptr; ## 实际值的指针 o->refcount = 1; ## 引用计数 /* Set the LRU to the current lruclock (minutes resolution), or * alternatively the LFU counter. */ if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL; } else { o->lru = LRU_CLOCK(); }
## 可以看到,
## redisObject类中的lru属性是根据启动配置文件的内存驱逐策略来决定保存lru的信息还是lfu的新
## 但是问题来了,当切换内存驱逐策略的时候,例如当LRU 切换成 LFU的时候,redis是怎么操作的呢,这篇文章主要解决这个问题 return o; }
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) { if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) return createEmbeddedStringObject(ptr,len); else return createRawStringObject(ptr,len); }
## 就是说 当String类型的value的大小小于等于44的时候,就会使用emb编码,大于则使用RAW
## 但是为什么是44呢,这是因为redis从2.8开始使用jemalloc内存分配器。这个比glibc的malloc要好不少,还省内存。
## 在这里可以简单理解,jemalloc会分配8,16,32,64等字节的内存。
## redis存储 为key和value,key对象最大16Byte,value由sdshdr存储,sdshdr请看下图 robj *createRawStringObject(const char *ptr, size_t len) { return createObject(OBJ_STRING, sdsnewlen(ptr,len)); } /* Create a string object with encoding OBJ_ENCODING_EMBSTR, that is * an object where the sds string is actually an unmodifiable string * allocated in the same chunk as the object itself. */ robj *createEmbeddedStringObject(const char *ptr, size_t len) { robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1); ## 使用sdshdr8 struct sdshdr8 *sh = (void*)(o+1); o->type = OBJ_STRING; o->encoding = OBJ_ENCODING_EMBSTR; o->ptr = sh+1; o->refcount = 1; if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL; } else { o->lru = LRU_CLOCK(); } sh->len = len; sh->alloc = len; sh->flags = SDS_TYPE_8; if (ptr == SDS_NOINIT) sh->buf[len] = ‘\0‘; else if (ptr) { memcpy(sh->buf,ptr,len); sh->buf[len] = ‘\0‘; } else { memset(sh->buf,0,len+1); } return o; }
struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
## sdshdr5 flags 低3位用来存类型,高5位用来存value长度,2的5次方=32 ,最大只能表示32,
## String的raw 和emb 以value长度为44为分界,所以sdshdr5 表示不了44
char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];
## sdshdr8 用8位表示长度value长度
## 用8位表示空闲空间
## flags占8位
## redisObject对象16个字节,value 结构3个字节, 加value值44个字节 加 空格符 1个字节 = 64个字节
## jemalloc 可以一次分配完 }; struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };
标签:ade mbed obj define rmi return oid 过程 内存分配
原文地址:https://www.cnblogs.com/start-from-zero/p/12993612.html