标签:dna 持久化存储 数据 数据包 滚动 中文 暂停 自己 lse
kubernetes objects文档(yaml文件编写):
https://kubernetes.io/docs/concepts/overview/working-with-objects/kubernetes-objects/
kubernetes objects 的api接口文档:
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.15/#deploymentlist-v1-apps
kubeadm文档:
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
kubectl文档:
https://kubernetes.io/docs/reference/kubectl/overview/
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
缩写:pod (po), service (svc), replicationcontroller (rc), deployment (deploy), replicaset (rs)
kubernetes概念文档:
https://kubernetes.io/docs/concepts/
kubernetes中文文档教程:
http://docs.kubernetes.org.cn/
kubernetes教程:
https://jimmysong.io/kubernetes-handbook/
配置nfs文档:
https://kubernetes.io/docs/concepts/storage/persistent-volumes/
apiVersion选择:kubectl api-versions
https://loocode.com/post/10173
http://docs.kubernetes.org.cn/31.html
k8s的大致结构
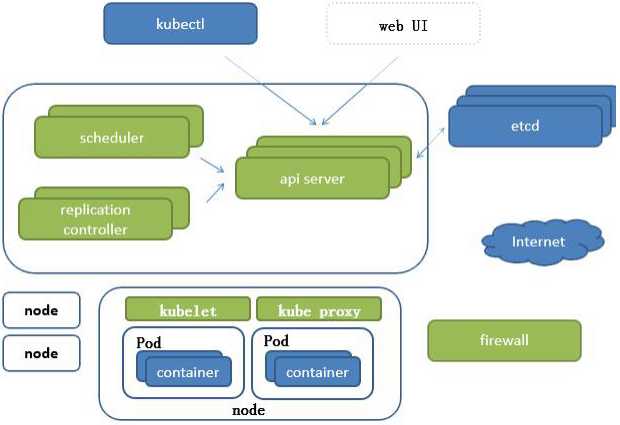
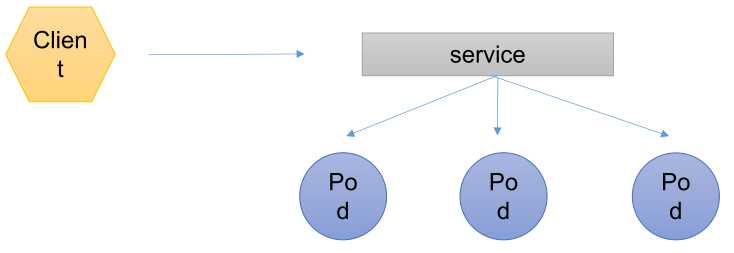
即pod互相通信是在内网中的要让外网的客户访问需要暴露服务。
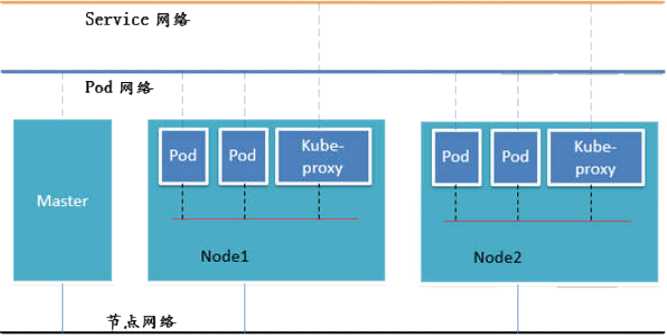
Kubernetes的网络模型假定了所有的Pod都在一个可以直接联通的扁平的网络空间中,在这个GCE(google compute engine)里面是现成的网络模型,kubernetes假定这个网络已经存在。而在私有云里搭建Kubernetes集群就不能假定这个网络已经存在了。我们需要自己实现这个网络,将不同节点上的Docker容器之间互相打通,然后在运行Kubernetes。
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,他的功能是让集群中不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。而且它还在这些IP地址之间建立一个覆盖网络(Overlay Network),通过覆盖网络,将数据包原封不动的传递到目标容器内。
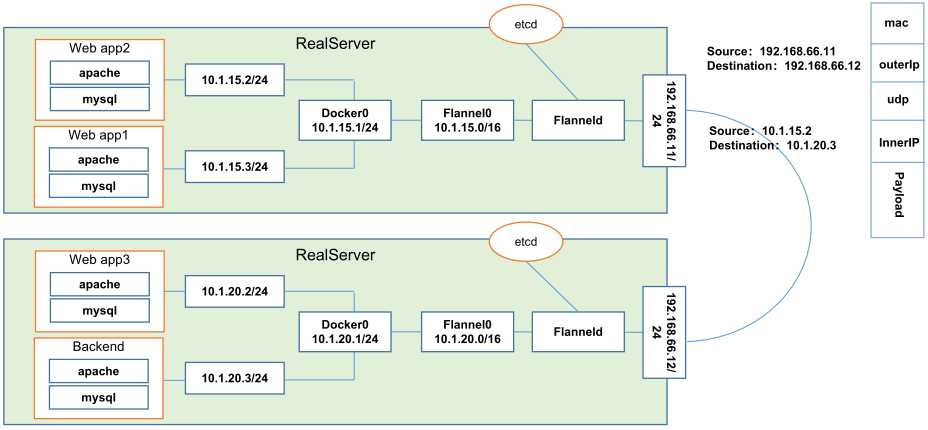
etcd和flannel提供说明:
存储管理Flannel可分配的IP地址资源;
监控etcd中每个pod的实际地址,并在内存中建立维护pod节点路由表;
同一个Pod内部通讯:同一个Pod共享同一个网络命名空间,共享同一个Linux协议栈;
Pod1至Pod2:
1.1 Pod1与Pod2不在同一台主机:
? Pod的地址是与docker0在统一个网段的,但是docker0网段与宿主机网卡是两个完全不同的网段,并且不同Node之间的通信只能通过宿主机的物理网卡进行。将Pod所在IP和所在Node的IP关联起来,通过这个关联让Pod可以互相访问。
1.2 Pod1与Pod2在同一台机器上:
? 由Docker0网桥直接转发请求值Pod2,不需要经过Flannel。
Pod至Service网络:目前基于性能考虑全部为iptables(新版本替换为lvs)
2.1 Pod到外网:
? Pod向外网发送请求,查找路由表,转发数据包到宿主机的网卡,宿主机网卡完成路由选择后,iptables执行Masquerade,把源IP更改为宿主机网卡的IP,然后向外网服务器发送请求。
2.2 外网访问Pod:
标签:dna 持久化存储 数据 数据包 滚动 中文 暂停 自己 lse
原文地址:https://www.cnblogs.com/bartggg/p/12996832.html