标签:stop learn info mamicode pre ike 包括 voc rem
1 """ 2 演示内容:文档的向量化 3 """ 4 from sklearn.feature_extraction.text import CountVectorizer 5 corpus = [ 6 ‘Jobs was the chairman of Apple Inc., and he was very famous‘, 7 ‘I like to use apple computer‘, 8 ‘And I also like to eat apple‘ 9 ] 10 11 #未经停用词过滤的文档向量化 12 vectorizer =CountVectorizer() 13 print(vectorizer.fit_transform(corpus).todense()) #转化为完整特征矩阵 14 print(vectorizer.vocabulary_) 15 print(" ") 16 17 #经过停用词过滤后的文档向量化 18 import nltk 19 nltk.download(‘stopwords‘) 20 stopwords = nltk.corpus.stopwords.words(‘english‘) 21 print (stopwords) 22 23 print(" ") 24 vectorizer =CountVectorizer(stop_words=‘english‘) 25 print("after stopwords removal:\n", vectorizer.fit_transform(corpus).todense()) 26 print("after stopwords removal:\n", vectorizer.vocabulary_) 27 28 print(" ") 29 #采用ngram模式进行文档向量化 30 vectorizer =CountVectorizer(ngram_range=(1,2)) #表示从1-2,既包括unigram,也包括bigram 31 print("N-gram mode:\n",vectorizer.fit_transform(corpus).todense()) #转化为完整特征矩阵 32 print(" ") 33 print("N-gram mode:\n",vectorizer.vocabulary_)
未经停用词过滤的文档向量化:

所有的停用词:

经过停用词过滤的文档向量化:
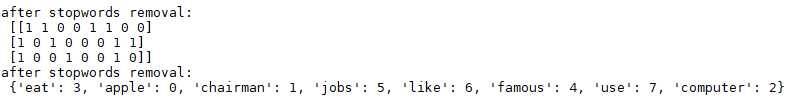
采用n-gram模式进行文档向量化:

标签:stop learn info mamicode pre ike 包括 voc rem
原文地址:https://www.cnblogs.com/cxq1126/p/13025452.html