标签:https img 数据量 png 生成随机数 tail java code 查询条件
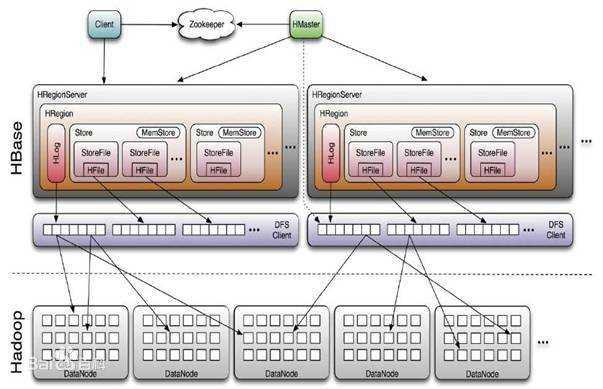
hbase在创建表的时候,一开始只有一个Region,当数据量越来越大时,此region不能承受数据量,就会进行split
这种方式有两种缺点:1.数据往一个region上写,会有写热点问题
2.region split会消耗宝贵的集群I/O资源
所以引入了预分区概念。
https://blog.csdn.net/javajxz008/article/details/51913471
rowkey的设计:一条数据存储于哪个分区,取决于rowkey处于哪个预分区的区间内,设计rowkey的目的,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。
rowkey的设计原则:
(1)唯一性原则
(2)长度原则(不能太长,不能太短)(满足查询条件下越短越好)(60-80字节,最大值是64k)
(3)散列原则(rowkey均匀分配)
1.生成随机数,hash,散列值
2.字符串反转(20170524000001-》10000042507102,20170524000002-》20000042507102,散列)
3.字符串拼接(20170524000001-》20170524000001_a12e,20170524000001-》20170524000001_93i7)
标签:https img 数据量 png 生成随机数 tail java code 查询条件
原文地址:https://www.cnblogs.com/18800105616a/p/13029688.html