标签:引擎 可扩展性 尺度 使用 通信 reg 能力 速度 中心
NVIDIA安倍架构
NVIDIA Ampere ArchitectureNVIDIA
The Heart of the World’s Highest-Performing, Elastic Data Centers
一.现代数据中心中AI和HPC的核心
科学家、研究人员和工程师我们这个时代的达芬奇和爱因斯坦正致力于用人工智能和高性能计算(HPC)解决世界上最重要的科学、工业和大数据挑战。与此同时,企业甚至整个行业都在寻求利用人工智能的力量,从海量数据集中(包括内部和云中)获取新的见解。NVIDIA安培架构是为弹性计算时代而设计的,它提供了下一个巨大的飞跃,在每一个尺度上都提供了无与伦比的加速,使这些创新者能够完成他们一生的工作。
二.突破性创新
英伟达安培芯片由540亿个晶体管制成,是有史以来最大的7纳米(nm)芯片,具有六项关键的突破性创新。
第三代张量核
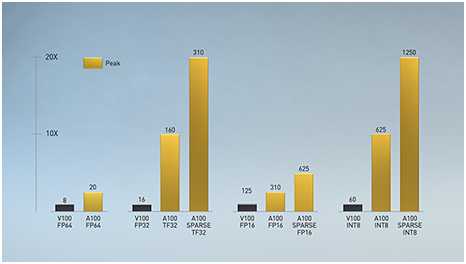
第一次在英伟达伏特加引入™ NVIDIA Tensor核心技术为人工智能带来了惊人的加速,将训练时间从几周缩短到几小时,并为推理提供了巨大的加速。NVIDIA安培架构在这些创新的基础上,引入了新的精度张量浮点(TF32)和浮点64(FP64),以加速和简化AI的采用,并将张量核的能力扩展到HPC。
TF32的工作原理和FP32一样,同时为AI提供高达20倍的加速,而不需要任何代码更改。使用NVIDIA自动混合精度,研究人员可以获得额外的2倍的性能与自动混合精度和FP16只添加几行代码。在支持bfloat16、INT8和INT4的情况下,NVIDIA A100张量核心gpu中的张量核心为人工智能训练和推理创建了一个极其通用的加速器。把张量核的能力带给HPC,A100还可以实现矩阵运算的完整性,IEEE认证,FP64精度。
三.多实例GPU(MIG)
每个AI和HPC应用程序都可以从加速中受益,但并不是每个应用程序都需要一个完整的A100 GPU的性能。使用MIG,每个A100可以被划分为多达7个GPU实例,在硬件级别完全隔离和安全,并具有自己的高带宽内存、缓存和计算核心。现在,开发人员可以访问所有应用程序的突破性加速,无论大小,并获得有保证的服务质量。IT管理员可以提供适当大小的GPU加速以实现最佳利用率,并在裸机和虚拟化环境中扩展对每个用户和应用程序的访问。

四.第三代NVLink
跨多个GPU扩展应用程序需要非常快速的数据移动。A100中的第三代NVIDIA®NVLink®将GPU到GPU的直接带宽提高了一倍,达到每秒600千兆字节(GB/s),几乎比PCIe Gen4高出10倍。与最新一代NVIDIA NVSwitch搭配使用时™,服务器中的所有gpu都可以以NVLink的全速相互通信,以实现难以置信的快速数据传输。
英伟达DGX™ A100和其他领先计算机制造商的服务器通过NVIDIA HGX利用NVLink和NVSwitch技术™ 100个基板,为HPC和AI工作负载提供更大的可扩展性。

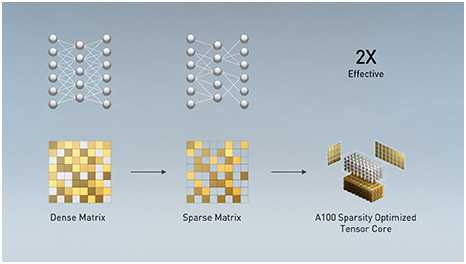
五.结构稀疏性
现代的人工智能网络越来越大,拥有数百万甚至数十亿个参数。并不是所有这些参数都需要精确的预测和推断,有些参数可以转换为零,使模型“稀疏”而不影响精度。A100中的张量核可以为稀疏模型提供高达2倍的性能。稀疏性特征有利于人工智能推理,同时也可以用来提高模型训练的性能。
六.更智能、更快的内存
A100正在给数据中心带来大量的计算。为了保持这些计算引擎的充分利用,它拥有一流的每秒1.6兆字节(TB/秒)的内存带宽,比上一代增加了67%。此外,A100的片上内存显著增加,包括一个40兆字节(MB)的2级缓存,比上一代大7倍,以最大限度地提高计算性能。

七.边缘收敛加速度
NVIDIA安培架构与NVIDIA Mellanox的ConnectX-6dx智能网卡在NVIDIA EGX中的结合™ A100带来了前所未有的计算和网络加速能力,可以处理边缘产生的大量数据。Mellanox SmartNIC包括安全卸载,可以高达200千兆比特/秒(Gb/s)的线速率解密和GPUDirect™ 它将视频帧直接传输到GPU存储器中进行人工智能处理。有了EGX A100,企业可以更安全、更高效地加速边缘的AI部署。

标签:引擎 可扩展性 尺度 使用 通信 reg 能力 速度 中心
原文地址:https://www.cnblogs.com/wujianming-110117/p/13037631.html