标签:git creat lock 自己的 执行时间 部分 项目 分布 support
本文主要介绍TCC的原理,以及从代码的角度上分析如何实现的;不涉及具体使用示例。本文分析的是github中开源项目tcc-transaction的代码,地址为:https://github.com/changmingxie/tcc-transaction,当然github上有多个tcc项目,但是他们原理相近,所以不过多介绍,有兴趣的小伙伴自行阅读源码。一 TCC架构
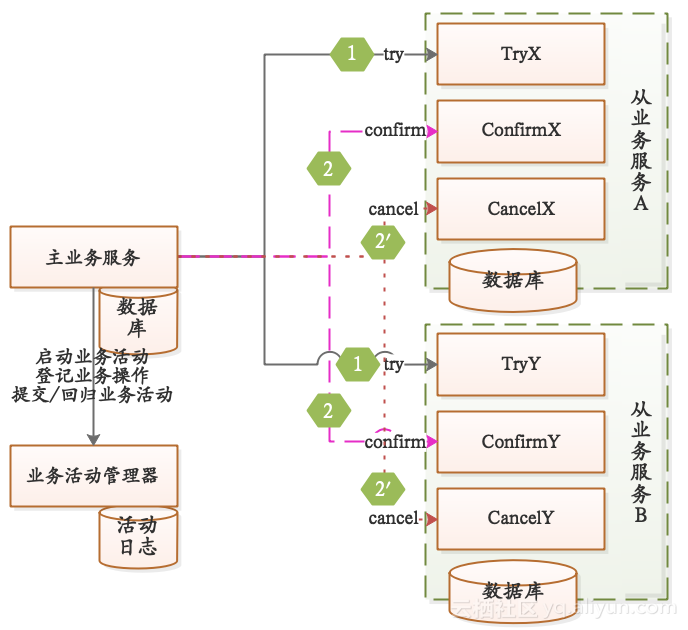
如上图所示:
- 一个完整的业务活动由一个主业务服务与若干从业务服务组成。
- 主业务服务负责发起并完成整个业务活动。
- 从业务服务提供TCC型业务操作。
- 业务活动管理器控制业务活动的一致性,它登记业务活动中的操作,并在业务活动提交时进行confirm操作,在业务活动取消时进行cancel操作
TCC和2PC/3PC很像,不过TCC的事务控制都是业务代码层面的,而2PC/3PC则是资源层面的。
TCC事务其实主要包含两个阶段:Try阶段、Confirm/Cancel阶段。
从TCC的逻辑模型上我们可以看到,TCC的核心思想是,try阶段检查并预留资源,确保在confirm阶段有资源可用,这样可以最大程度的确保confirm阶段能够执行成功。
完成所有业务检查(一致性)
预留必须业务资源(准隔离性)
真正执行业务
不作任何业务检查
只使用Try阶段预留的业务资源
Confirm操作必须保证幂等性
释放Try阶段预留的业务资源
Cancel操作必须保证幂等性
下面通过一个示例来讨论TCC事务。Tom需要给Tracy转10元,当使用TCC解决这种事务时,应该如何去做呢?
我们考虑一下这个转账过程面临的问题:
- 需要确保Tom账户余额不少于10元。
- 需要确保账户余额的正确性,例如:假设Tom只有10元钱,但是Tom同时给Tracy、Angle转账10元;Tom给其他人转账时,也可能收到其他人转过来的钱,此时账户的余额不能出现错乱(Tracy账户也面临过类似的问题)
- 当并发量比较大时,要能够确保性能。
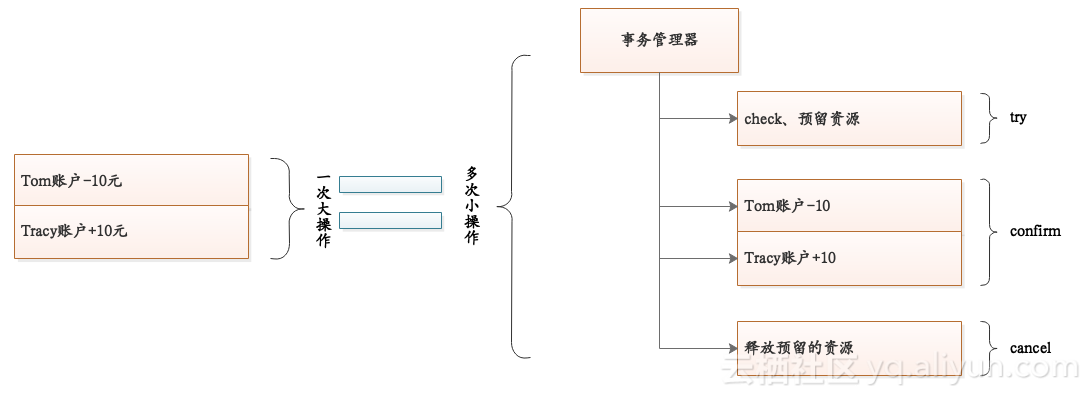
TCC解决分布式事物的思路是,一个大事务拆解成多个小事务。
使用TCC事务时,伪代码如下所示:
逻辑如下图所示:
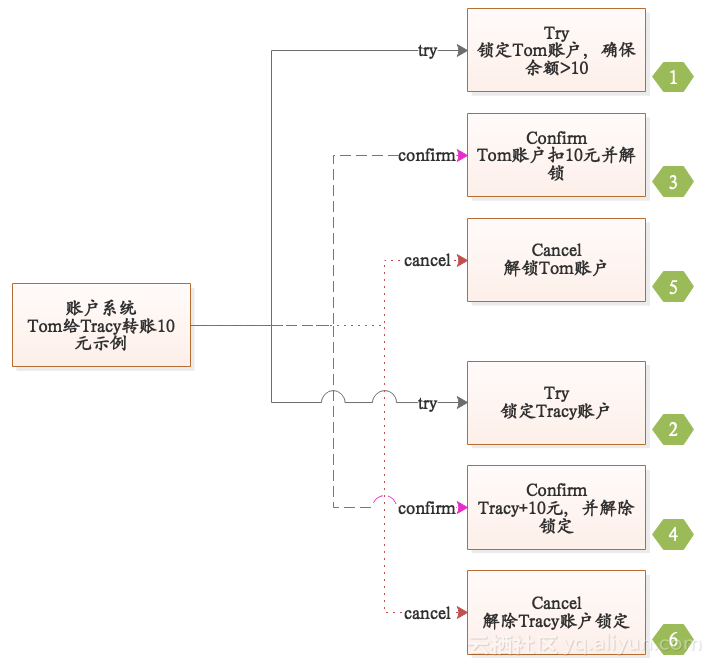
在Try逻辑中需要确保Tom账户的余额足够,并锁定需要使用的资源(Tom、Tracy账户);如果这一步操作执行成功(没有出现异常),那么将执行Confirm方法,如果执行失败,那么将执行Cancel方法。注意Confirm、Cancel需要做好幂等。
在上面的TCC事务中,转账操作其实涉及六次操作,实际项目中,在任何一个步骤都可能失败,那么当任何一个步骤失败时,TCC框架是如何做到数据一致性的呢?
以下为TCC的处理流程图,他可以确保不管是在try阶段,还是在confirm/cancel阶段都可以确保数据的一致性。
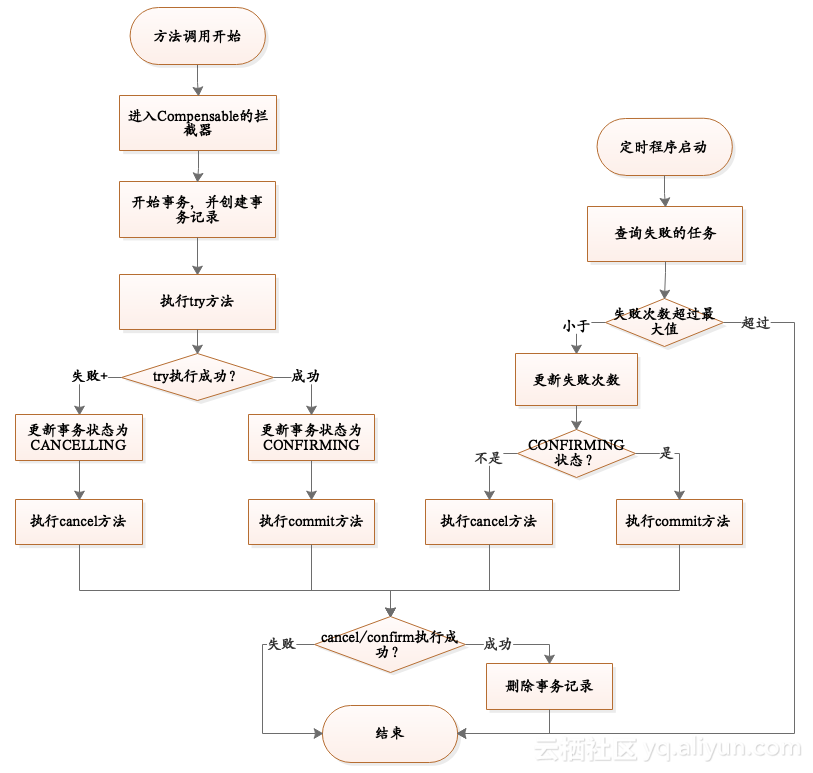
从流程图上可以看到,TCC依赖于一条事务处理记录,在开始TCC事务前标记创建此记录,然后在TCC的每个环节持续更新此记录的状态,这样就可以知道事务执行到那个环节了,当一次执行失败,进行重试时同样根据此数据来确定当前阶段,并判断应该执行什么操作。
因为存在失败重试的逻辑,所以cancel、commit方法必须实现幂等。其实在分布式开发中,凡是涉及到写操作的地方都应该实现幂等。
因为使用了@Compensable注解,所以当调用transferTry方法前,首先进入代理类中。在TCC中有两个Interceptor会对@Compensable标注的方法生效,他们分别是:CompensableTransactionInterceptor(TCC主要逻辑在此Interceptor中完成)、ResourceCoordinatorInterceptor(处理资源相关的事宜)。
CompensableTransactionInterceptor#interceptCompensableMethod是TCC的核心处理逻辑。interceptCompensableMethod封装请求数据,为TCC事务做准备,源码如下:
rootMethodProceed是TCC和核心处理逻辑,实现了对Try、Confirm、Cancel的执行,源码如下,重点注意标红加粗部分:
在这个方法中我们看到,首先执行的是@Compensable注解标注的方法(try),如果抛出异常,那么执行rollback方法(cancel),否则执行commit方法(cancel)。
考虑到在try、cancel、confirm过程中都可能发生异常,所以在任何一步失败时,系统都能够要么回到最初(未转账)状态,要么到达最终(已转账)状态。下面讨论一下TCC代码层面是如何保证一致性的。
在前面的代码中,可以看到执行try之前,TCC通过transactionManager.begin()开启了一个事务,这个begin方法的核心是:
- 创建一个记录,用于记录事务执行到那个环节了。
- 注册当前事务到TransactionManager中,在confirm、cancel过程中可以使用此Transaction来commit或者rollback。
TransactionManager#begin方法
CachableTransactionRepository#create创建一个用于标识事务执行环节的记录,然后将transaction放到缓存中区。代码如下:
CachableTransactionRepository有多个子类(FileSystemTransactionRepository、JdbcTransactionRepository、RedisTransactionRepository、ZooKeeperTransactionRepository),通过这些类可以实现记录db、file、redis、zk等的解决方案。
在commit、rollback中,都有这样一行代码,用于更新事务状态:
这行代码将当前事务的状态标记为commit/rollback,如果失败会抛出异常,不会执行后续的confirm/cancel方法;如果成功,才会执行confirm/cancel方法。
如果在try/commit/rollback过程中失败了,请求(transferTry方法)将会立即返回,TCC在这里引入了重试机制,即通过定时程序查询执行失败的任务,然后进行补偿操作。具体见:
TransactionRecovery#startRecover查询所有异常事务,然后逐个进行处理。注意重试操作有一个最大重试次数的限制,如果超过最大重试次数,此事务将会被忽略。
目前解决分布式事务的方案中,最稳定可靠的方案有:TCC、2PC/3PC、最终一致性。这三种方案各有优劣,有自己的适用场景。下面我们简单讨论一下TCC主要的优缺点。
因为Try阶段检查并预留了资源,所以confirm阶段一般都可以执行成功。
资源锁定都是在业务代码中完成,不会block住DB,可以做到对db性能无影响。
TCC的实时性较高,所有的DB写操作都集中在confirm中,写操作的结果实时返回(失败时因为定时程序执行时间的关系,略有延迟)。
从源码分析中可以看到,因为事务状态管理,将产生多次DB操作,这将损耗一定的性能,并使得整个TCC事务时间拉长。
事务涉及方越多,Try、Confirm、Cancel中的代码就越复杂,可复用性就越底(这一点主要是相对最终一致性方案而言的)。另外涉及方越多,这几个阶段的处理时间越长,失败的可能性也越高。
TCC-Transaction源码以及使用文档参考:https://github.com/changmingxie/tcc-transaction
最终一致性解决方案,参考《RocketMQ实践》
标签:git creat lock 自己的 执行时间 部分 项目 分布 support
原文地址:https://www.cnblogs.com/lipengsheng-javaweb/p/13038692.html