标签:连接 变化 origin 还需 阻塞 http 12c 缓存 拥塞避免
什么是流量控制?流量控制的目的?
如果发送者发送数据过快,接收者来不及接收,那么就会有分组丢失。为了避免分组丢失,控制发送者的发送速度,使得接收者来得及接收,这就是流量控制。流量控制根本目的是防止分组丢失,它是构成TCP可靠性的一方面。
如何实现流量控制?
由滑动窗口协议(连续ARQ协议)实现。滑动窗口协议既保证了分组无差错、有序接收,也实现了流量控制。主要的方式就是接收方返回的 ACK 中会包含自己的接收窗口的大小,并且利用大小来控制发送方的数据发送。
流量控制引发的死锁?怎么避免死锁的发生?
当发送者收到了一个窗口为0的应答,发送者便停止发送,等待接收者的下一个应答。但是如果这个窗口不为0的应答在传输过程丢失,发送者一直等待下去,而接收者以为发送者已经收到该应答,等待接收新数据,这样双方就相互等待,从而产生死锁。
为了避免流量控制引发的死锁,TCP使用了持续计时器。每当发送者收到一个零窗口的应答后就启动该计时器。时间一到便主动发送报文询问接收者的窗口大小。若接收者仍然返回零窗口,则重置该计时器继续等待;若窗口不为0,则表示应答报文丢失了,此时重置发送窗口后开始发送,这样就避免了死锁的产生。
拥塞控制:拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况;常用的方法就是:( 1 )慢开始、拥塞避免( 2 )快重传、快恢复。
流量控制:流量控制是作用于接收者的,它是控制发送者的发送速度从而使接收者来得及接收,防止分组丢失的。
我们在开始假定:1、数据是单方向传递,另一个窗口只发送确认;2、接收方的缓存足够大,因此发送方的大小的大小由网络的拥塞程度来决定。
(一)慢开始算法:
发送方维持一个叫做拥塞窗口cwnd(congestion window)的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞窗口,另外考虑到接受方的接收能力,发送窗口可能小于拥塞窗口。
慢开始算法的思路就是,不要一开始就发送大量的数据,先探测一下网络的拥塞程度,也就是说由小到大逐渐增加拥塞窗口的大小。
这里用报文段的个数作为拥塞窗口的大小举例说明慢开始算法,实际的拥塞窗口大小是以字节为单位的。如下图:
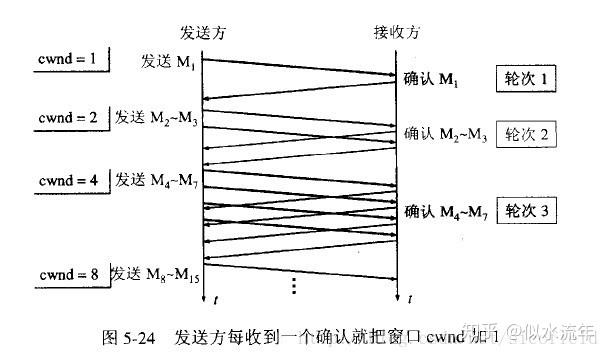
从上图可以看到,一个传输轮次所经历的时间其实就是往返时间RTT,而且没经过一个传输轮次(transmission round),拥塞窗口cwnd就加倍。
为了防止cwnd增长过大引起网络拥塞,还需设置一个慢开始门限ssthresh状态变量。ssthresh的用法如下:当cwnd<ssthresh时,使用慢开始算法。
当cwnd>ssthresh时,改用拥塞避免算法。
当cwnd=ssthresh时,慢开始与拥塞避免算法任意
注意,这里的“慢”并不是指cwnd的增长速率慢,而是指在TCP开始发送报文段时先设置cwnd=1,然后逐渐增大,这当然比按照大的cwnd一下子把许多报文段突然注入到网络中要“慢得多”。
(二)拥塞避免算法:
拥塞避免算法让拥塞窗口缓慢增长,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口按线性规律缓慢增长。
无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有按时收到确认,虽然没有收到确认可能是其他原因的分组丢失,但是因为无法判定,所以都当做拥塞来处理),就把慢开始门限ssthresh设置为出现拥塞时的发送窗口大小的一半(但不能小于2)。然后把拥塞窗口cwnd重新设置为1,执行慢开始算法。这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
整个拥塞控制的流程如下图:
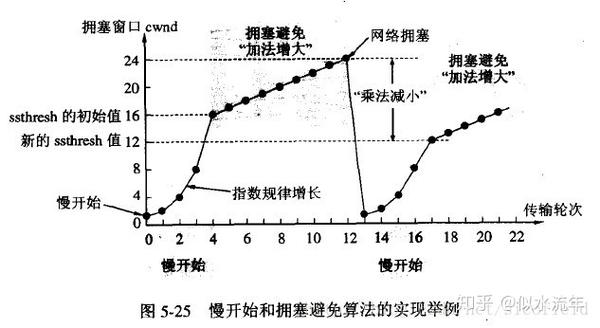
(1)拥塞窗口cwnd初始化为1个报文段,慢开始门限初始值为16
(2)执行慢开始算法,指数规律增长到第4轮,即cwnd=16=ssthresh,改为执行拥塞避免算法,拥塞窗口按线性规律增长
(3)假定cwnd=24时,网络出现超时(拥塞),则更新后的ssthresh=12,cwnd重新设置为1,并执行慢开始算法。当cwnd=12=ssthresh时,改为执行拥塞避免算法
关于 乘法减小(Multiplicative Decrease)和加法增大(Additive Increase):
“乘法减小”指的是无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞,就把慢开始门限ssthresh设置为出现拥塞时的发送窗口大小的一半,并执行慢开始算法,所以当网络频繁出现拥塞时,ssthresh下降的很快,以大大减少注入到网络中的分组数。“加法增大”是指执行拥塞避免算法后,使拥塞窗口缓慢增大,以防止过早出现拥塞。常合起来成为AIMD算法。
注意:“拥塞避免”并非完全能够避免了阻塞,而是使网络比较不容易出现拥塞。
(三)快重传算法:
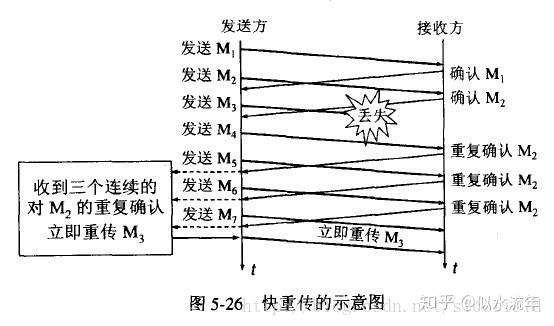
快重传要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方,可提高网络吞吐量约20%)而不要等到自己发送数据时捎带确认。快重传算法规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。如下图:
(四)快恢复算法:
快重传配合使用的还有快恢复算法,有以下两个要点:
当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半(为了预防网络发生拥塞)。但是接下去并不执行慢开始算法
考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh减半后的值,然后执行拥塞避免算法,使cwnd缓慢增大。如下图:TCP Reno版本是目前使用最广泛的版本。
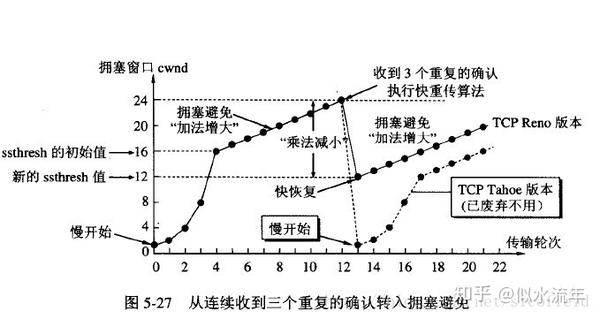
注意:在采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络出现超时时才使用
标签:连接 变化 origin 还需 阻塞 http 12c 缓存 拥塞避免
原文地址:https://www.cnblogs.com/wsw-seu/p/13040544.html