标签:asp swf ring 没有 ota path 文档 embed length
@
一、制作word模版,${xxxx}是一会要替换的内容,最下面的表格是要插入数据,根据是否以$开头来判断是需要替换还是插入数据。
????????注意如果是需要插入数据,制作的表格模版需要一行空行,也只能有一行空行,原因可以看代码的逻辑,表格中${header}和${hearder2}是放入需要替换的图片
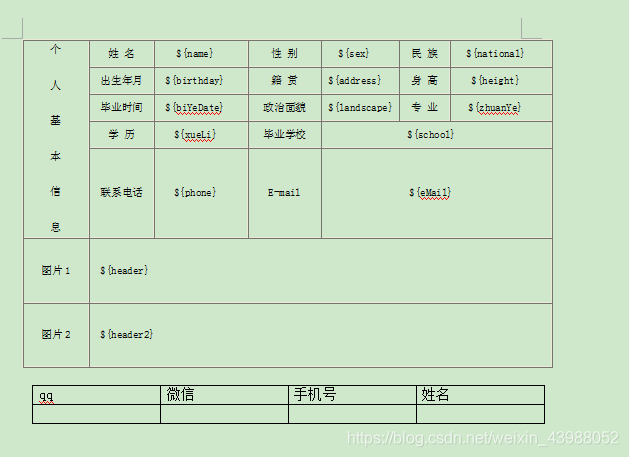
二、添加poi所需要的jar包文件,我用的maven对jar包进行管理
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.11</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.11</version>
</dependency>
三、由于poi自身bug,会出现图片无法显示问题,这里需要自定义一个类继承XWPFDocument类,接下来使用的都是我们自己创建的这个类来操作word对象,这个类对XWPFDocument进行了继承,所以不用担心会有什么问题
import java.io.InputStream;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.xmlbeans.XmlException;
import org.apache.xmlbeans.XmlToken;
import org.openxmlformats.schemas.drawingml.x2006.main.CTNonVisualDrawingProps;
import org.openxmlformats.schemas.drawingml.x2006.main.CTPositiveSize2D;
import org.openxmlformats.schemas.drawingml.x2006.wordprocessingDrawing.CTInline;
public class CustomXWPFDocument extends XWPFDocument {
public CustomXWPFDocument(InputStream in) throws java.io.IOException {
super(in);
}
public CustomXWPFDocument() {
super();
}
public CustomXWPFDocument(OPCPackage pkg)throws java.io.IOException {
super(pkg);
}
/**
* @param id
* @param width 宽
* @param height 高
* @param paragraph 段落
*/
public void createPicture(int id, int width, int height,XWPFParagraph paragraph) {
final int EMU = 9525;
width *= EMU;
height *= EMU;
String blipId = getAllPictures().get(id).getPackageRelationship().getId();
CTInline inline = paragraph.createRun().getCTR().addNewDrawing().addNewInline();
String picXml = ""
+"<a:graphic xmlns:a=\"http://schemas.openxmlformats.org/drawingml/2006/main\">"
+" <a:graphicData uri=\"http://schemas.openxmlformats.org/drawingml/2006/picture\">"
+" <pic:pic xmlns:pic=\"http://schemas.openxmlformats.org/drawingml/2006/picture\">"
+" <pic:nvPicPr>" + " <pic:cNvPr id=\""
+ id
+"\" name=\"Generated\"/>"
+" <pic:cNvPicPr/>"
+" </pic:nvPicPr>"
+" <pic:blipFill>"
+" <a:blip r:embed=\""
+ blipId
+"\" xmlns:r=\"http://schemas.openxmlformats.org/officeDocument/2006/relationships\"/>"
+" <a:stretch>"
+" <a:fillRect/>"
+" </a:stretch>"
+" </pic:blipFill>"
+" <pic:spPr>"
+" <a:xfrm>"
+" <a:off x=\"0\" y=\"0\"/>"
+" <a:ext cx=\""
+ width
+"\" cy=\""
+ height
+"\"/>"
+" </a:xfrm>"
+" <a:prstGeom prst=\"rect\">"
+" <a:avLst/>"
+" </a:prstGeom>"
+" </pic:spPr>"
+" </pic:pic>"
+" </a:graphicData>" + "</a:graphic>";
inline.addNewGraphic().addNewGraphicData();
XmlToken xmlToken = null;
try{
xmlToken = XmlToken.Factory.parse(picXml);
}catch(XmlException xe) {
xe.printStackTrace();
}
inline.set(xmlToken);
inline.setDistT(0);
inline.setDistB(0);
inline.setDistL(0);
inline.setDistR(0);
CTPositiveSize2D extent = inline.addNewExtent();
extent.setCx(width);
extent.setCy(height);
CTNonVisualDrawingProps docPr = inline.addNewDocPr();
docPr.setId(id);
docPr.setName("图片"+ id);
docPr.setDescr("测试");
}
}
四、接下来就是导出word的工具类了
import java.io.*;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.servlet.http.HttpServletResponse;
import org.apache.poi.xwpf.usermodel.*;
import org.springframework.stereotype.Component;
/*******************************************
* 通过word模板生成新的word工具类
*
* @Author Administrator
* @Date 2020/03/10
* @Version V1.0
*******************************************/
@Component
public class WordUtil {
/**
* 根据模板生成word
*
* @param path
* 模板的路径
* @param params
* 需要替换的参数
* @param tableList
* 需要插入的参数,里面的list为每个表的数据
* @param fileName
* 生成word文件的文件名
* @return 生成的word的路径
*/
public String getWord(String path, Map<String, Object> params, List<List<String[]>> tableList, String fileName,String outFileName) throws Exception {
File file = new File(path);
InputStream is = new FileInputStream(file);
CustomXWPFDocument doc = new CustomXWPFDocument(is);
this.replaceInPara(doc, params); // 替换文本里面的变量
this.replaceInTable(doc, params, tableList); // 替换表格里面的变量
// OutputStream os = response.getOutputStream();
// response.setContentType("application/x-download");
// response.setHeader("Content-disposition", "attachment; filename=" + fileName);
// doc.write(os);
File newFile = new File(outFileName);
OutputStream os = new FileOutputStream(newFile);
doc.write(os);
this.close(os);
this.close(is);
return outFileName;
}
/**
* 替换段落里面的变量
*
* @param doc
* 要替换的文档
* @param params
* 参数
*/
private void replaceInPara(CustomXWPFDocument doc, Map<String, Object> params) {
Iterator<XWPFParagraph> iterator = doc.getParagraphsIterator();
XWPFParagraph para;
while (iterator.hasNext()) {
para = iterator.next();
this.replaceInPara(para, params, doc);
}
}
/**
* 替换段落里面的变量
*
* @param para
* 要替换的段落
* @param params
* 参数
*/
private void replaceInPara(XWPFParagraph para, Map<String, Object> params, CustomXWPFDocument doc) {
List<XWPFRun> runs;
Matcher matcher;
if (this.matcher(para.getParagraphText()).find()) {
runs = para.getRuns();
int start = -1;
int end = -1;
String str = "";
for (int i = 0; i < runs.size(); i++) {
XWPFRun run = runs.get(i);
String runText = run.toString();
if (‘$‘ == runText.charAt(0) && ‘{‘ == runText.charAt(1)) {
start = i;
}
if ((start != -1)) {
str += runText;
}
if (‘}‘ == runText.charAt(runText.length() - 1)) {
if (start != -1) {
end = i;
break;
}
}
}
for (int i = start; i <= end; i++) {
para.removeRun(i);
i--;
end--;
}
if (params != null) {
for (Map.Entry<String, Object> entry : params.entrySet()) {
String key = entry.getKey();
if (str.indexOf(key) != -1) {
Object value = entry.getValue();
if (value instanceof String) {
str = str.replace(key, value.toString());
para.createRun().setText(str, 0);
break;
} else if (value instanceof Map) {
str = str.replace(key, "");
Map pic = (Map) value;
int width = Integer.parseInt(pic.get("width").toString());
int height = Integer.parseInt(pic.get("height").toString());
int picType = getPictureType(pic.get("type").toString());
byte[] byteArray = (byte[]) pic.get("content");
ByteArrayInputStream byteInputStream = new ByteArrayInputStream(byteArray);
try {
// int ind =
// doc.addPicture(byteInputStream,picType);
// doc.createPicture(ind, width , height,para);
doc.addPictureData(byteInputStream, picType);
doc.createPicture(doc.getAllPictures().size() - 1, width, height, para);
para.createRun().setText(str, 0);
break;
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
}
}
/**
* 为表格插入数据,行数不够添加新行
*
* @param table
* 需要插入数据的表格
* @param tableList
* 插入数据集合
*/
private static void insertTable(XWPFTable table, List<String[]> tableList) {
// 创建行,根据需要插入的数据添加新行,不处理表头
for (int i = 0; i < tableList.size(); i++) {
XWPFTableRow row = table.createRow();
}
// 遍历表格插入数据
List<XWPFTableRow> rows = table.getRows();
int length = table.getRows().size();
//i为表格标题行数
for (int i = 2; i < length - 1; i++) {
XWPFTableRow newRow = table.getRow(i);
newRow.setHeight(600); //设置表格行高
List<XWPFTableCell> cells = newRow.getTableCells();
for (int j = 0; j < cells.size(); j++) {
XWPFTableCell cell = cells.get(j);
cell.getParagraphs().get(0).setAlignment(ParagraphAlignment.CENTER); //设置单元格居中显示
String s = tableList.get(i - 2)[j]; //i减去的数字也为表格行数
cell.setText(s);
}
}
}
/**
* 替换表格里面的变量
*
* @param doc
* 要替换的文档
* @param params
* 参数
*/
private void replaceInTable(CustomXWPFDocument doc, Map<String, Object> params, List<List<String[]>> tableList) {
Iterator<XWPFTable> iterator = doc.getTablesIterator();
XWPFTable table;
List<XWPFTableRow> rows;
List<XWPFTableCell> cells;
List<XWPFParagraph> paras;
int i = 0;
while (iterator.hasNext()) {
table = iterator.next();
if (table.getRows().size() > 1) {
// 判断表格是需要替换还是需要插入,判断逻辑有$为替换,表格无$为插入
if (this.matcher(table.getText()).find()) {
rows = table.getRows();
for (XWPFTableRow row : rows) {
cells = row.getTableCells();
for (XWPFTableCell cell : cells) {
paras = cell.getParagraphs();
for (XWPFParagraph para : paras) {
this.replaceInPara(para, params, doc);
}
}
}
} else {
if (tableList != null) {
insertTable(table, tableList.get(i)); // 插入数据
i++;
}
}
}
}
}
/**
* 正则匹配字符串
*
* @param str
* @return
*/
private Matcher matcher(String str) {
Pattern pattern = Pattern.compile("\\$\\{(.+?)\\}", Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(str);
return matcher;
}
/**
* 根据图片类型,取得对应的图片类型代码
*
* @param picType
* @return int
*/
private static int getPictureType(String picType) {
int res = CustomXWPFDocument.PICTURE_TYPE_PICT;
if (picType != null) {
if (picType.equalsIgnoreCase("png")) {
res = CustomXWPFDocument.PICTURE_TYPE_PNG;
} else if (picType.equalsIgnoreCase("dib")) {
res = CustomXWPFDocument.PICTURE_TYPE_DIB;
} else if (picType.equalsIgnoreCase("emf")) {
res = CustomXWPFDocument.PICTURE_TYPE_EMF;
} else if (picType.equalsIgnoreCase("jpg") || picType.equalsIgnoreCase("jpeg")) {
res = CustomXWPFDocument.PICTURE_TYPE_JPEG;
} else if (picType.equalsIgnoreCase("wmf")) {
res = CustomXWPFDocument.PICTURE_TYPE_WMF;
}
}
return res;
}
/**
* 将输入流中的数据写入字节数组
*
* @param in
* @return
*/
public static byte[] inputStream2ByteArray(InputStream in, boolean isClose) {
byte[] byteArray = null;
try {
int total = in.available();
byteArray = new byte[total];
in.read(byteArray);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (isClose) {
try {
in.close();
} catch (Exception e2) {
e2.getStackTrace();
}
}
}
return byteArray;
}
/**
* 关闭输入流
*
* @param is
*/
private void close(InputStream is) {
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 关闭输出流
*
* @param os
*/
private void close(OutputStream os) {
if (os != null) {
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
五、最后就是进行测试了,我是用的是ssm框架,这里放出测试代码
@RequestMapping("exportWordData")
public void exportWordData(HttpServletRequest request,HttpServletResponse response){
WordUtils wordUtil=new WordUtils();
Map<String, Object> params = new HashMap<String, Object>();
params.put("${position}", "java开发");
params.put("${name}", "段然涛");
params.put("${sex}", "男");
params.put("${national}", "汉族");
params.put("${birthday}", "生日");
params.put("${address}", "许昌");
params.put("${height}", "165cm");
params.put("${biYeDate}", "1994-02-03");
params.put("${landscape}", "团员");
params.put("${zhuanYe}", "社会工作");
params.put("${xueLi}", "本科");
params.put("${school}", "江西科技师范大学");
params.put("${phone}", "177");
params.put("${eMail}", "157");
try{
Map<String,Object> header = new HashMap<String, Object>();
header.put("width", 100);
header.put("height", 150);
header.put("type", "jpg");
header.put("content", WordUtils.inputStream2ByteArray(new FileInputStream("C:/Users/Administrator/Desktop/jar包/11.jpg"), true));
params.put("${header}",header);
Map<String,Object> header2 = new HashMap<String, Object>();
header2.put("width", 100);
header2.put("height", 150);
header2.put("type", "jpg");
header2.put("content", WordUtils.inputStream2ByteArray(new FileInputStream("C:/Users/Administrator/Desktop/jar包/22.jpg"), true));
params.put("${header2}",header2);
List<List<String[]>> list = new ArrayList<List<String[]>>();
List<String[]> testList = new ArrayList<String[]>();//一个需要插入的表是一个集合
testList.add(new String[]{"1","1AA","1BB","1CC"});
testList.add(new String[]{"2","2AA","2BB","2CC"});
testList.add(new String[]{"3","3AA","3BB","3CC"});
testList.add(new String[]{"4","4AA","4BB","4CC"}); list.add(testList);
String path="C:/Users/Administrator/Desktop/jar包/mobanFile.docx"; //模板文件位置
String fileName= new String("测试文档.docx".getBytes("UTF-8"),"iso-8859-1"); //生成word文件的文件名
wordUtil.getWord(path,params,list,fileName,newFilePath);
}catch(Exception e){
e.printStackTrace();
}
}
原文链接:https://www.cnblogs.com/duanrantao/p/8682897.html
WORD转PDF所需jar包:
https://yangtaotao.lanzous.com/ice1jlc
PDF转图片所需jar包:
https://yangtaotao.lanzous.com/ice169c
word转pdf使用的是ASPOSE.word,它的licence需要收费,百度有的文章中有,大家可以自行百度,这里就不放了。调用时传入word的路径和生成后的pdf的路径就行。
注意:在linux下不可以直接FileOutputSteram(path)生成文件,所以需要先new File(path),如果生成之后的文件中文乱码,可能是服务器没有字库,安装一个就可以了
package com.biolims.report.service;
import java.io.FileOutputStream;
import java.io.InputStream;
import com.aspose.words.Document;
import com.aspose.words.License;
import com.aspose.words.SaveFormat;
/**
*
* 由于ASPOSE比较吃内存,操作大一点的文件就会堆溢出,所以请先设置好java虚拟机参数:-Xms512m -Xmx512m(参考值)<br>
* 如有疑问,请在CSDN下载界面留言,或者联系QQ569925980<br>
*
* @author Spark
*
*/
public class Test {
/**
* 获取license
*
* @return
*/
public static boolean getLicense() {
boolean result = false;
try {
InputStream is = Test.class.getClassLoader().getResourceAsStream("\\license.xml");
License aposeLic = new License();
aposeLic.setLicense(is);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
public static void savedocx(String inPath, String outPath) {
if (!getLicense()) {
return;
}
try {
long old = System.currentTimeMillis();
Document doc = new Document(inPath);// 原始word路径
File file = new File(outPath);
FileOutputStream fileOS = new FileOutputStream(file );
doc.save(fileOS, SaveFormat.PDF);
long now = System.currentTimeMillis();
System.out.println("共耗时:" + ((now - old) / 1000.0) + "秒");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 支持DOC, DOCX, OOXML, RTF, HTML, OpenDocument, PDF, EPUB, XPS, SWF等相互转换<br>
*
* @param args
*/
public static void main(String[] args) {
// 验证License
if (!getLicense()) {
return;
}
try {
long old = System.currentTimeMillis();
Document doc = new Document("D:\\home\\lims\\报告管理需求 - 20190905.docx");// 原始word路径
String pdfFile = "D:\\home\\ff.pdf";
FileOutputStream fileOS = new FileOutputStream(pdfFile);
doc.save(fileOS, SaveFormat.PDF);
long now = System.currentTimeMillis();
System.out.println("共耗时:" + ((now - old) / 1000.0) + "秒");
} catch (Exception e) {
e.printStackTrace();
}
}
}
公司大佬说这种防止修改的方法在pdf有多页时可能会出问题,也没测试过,试过的朋友帮忙评论一下
public static String pdf2Image(String PdfFilePath) throws Exception {
File file = new File(PdfFilePath);
PdfDocument template_writer_pdfdoc = new PdfDocument(new PdfReader(PdfFilePath));
Rectangle size=template_writer_pdfdoc.getFirstPage().getPageSize();
int pages = template_writer_pdfdoc.getNumberOfPages();
PDDocument pdDocument;
String pdfPath="";
try {
String imgPDFPath = file.getParent();
int dot = file.getName().lastIndexOf(‘.‘);
String imagePDFName = file.getName().substring(0, dot); // 获取图片文件名
pdDocument = PDDocument.load(file);
PDFRenderer renderer = new PDFRenderer(pdDocument);
/* dpi越大转换后越清晰,相对转换速度越慢 */
StringBuffer imgFilePath = null;
List<String> pathList=new ArrayList<String>();
for (int i = 0; i < pages; i++) {
String imgFilePathPrefix = imgPDFPath + File.separator + imagePDFName;
imgFilePath = new StringBuffer();
imgFilePath.append(imgFilePathPrefix);
imgFilePath.append("_");
imgFilePath.append(String.valueOf(i + 1));
imgFilePath.append(".jpg");
File dstFile = new File(imgFilePath.toString());
BufferedImage image = renderer.renderImageWithDPI(i, 300);
ImageIO.write(image, "jpg", dstFile);
pathList.add(imgFilePath.toString());
}
template_writer_pdfdoc.close();
File file2 = new File(imgPDFPath + File.separator + file.getName());
// 第一步:创建一个document对象。
com.itextpdf.text.Document document = new com.itextpdf.text.Document();
document.setMargins(0, 0, 0, 0);
// 第二步:
// 创建一个PdfWriter实例,
com.itextpdf.text.pdf.PdfWriter.getInstance(document, new FileOutputStream(file2));
// 第三步:打开文档。
document.open();
for(String s:pathList) {
com.itextpdf.text.Image img = com.itextpdf.text.Image.getInstance(s);
img.setAlignment(com.itextpdf.text.Image.ALIGN_CENTER);
img.scaleAbsoluteHeight(size.getHeight());
img.scaleAbsoluteWidth(size.getWidth());
// 根据图片大小设置页面,一定要先设置页面,再newPage(),否则无效
document.setPageSize(new com.itextpdf.text.Rectangle(size.getWidth(), size.getHeight()));
document.newPage();
document.add(img);
}
document.close();
pdfPath=imgPDFPath + File.separator + file.getName();
} catch (IOException e) {
e.printStackTrace();
}finally {
}
return pdfPath;
}
POI根据模板导出word文件,以及word转PDF,PDF转图片再插入PDF中(防止PDF被修改)
标签:asp swf ring 没有 ota path 文档 embed length
原文地址:https://www.cnblogs.com/yang-TaoTao/p/13042892.html