最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索!
一、安装环境:

1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令是:pip install xlrd 2:安装pandas模块还需要一定的编码环境,所以我们自己在安装的时候,确保你的电脑有这些环境:Net.4 、VC-Compiler以及winsdk_web,如果大家没有这些软件~可以咨询我们的辅导员索要相关安装工具。 3:步骤1和2 准备好了之后,我们就可以开始安装pandas了,安装命令是:pip install pandas 一切准备就绪,就可以开始愉快的玩耍咯! ps:在这个过程中,可能会遇到安装不顺利的情况,万能的度娘有N种解决方案,你这么大应该要学着自己解决问题。
二、pandas操作Excel表单
数据准备,有一个Excel文件:lemon.xlsx有两个表单,表单名分别为:Python 以及student,
Python的表单数据如下所示:
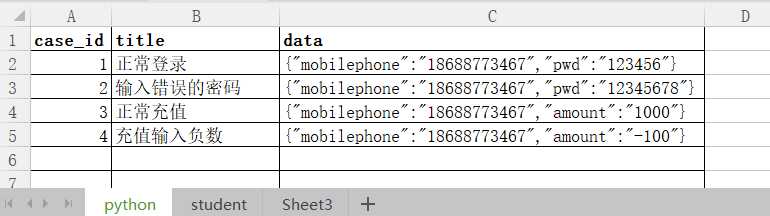
student的表单数据如下所示:
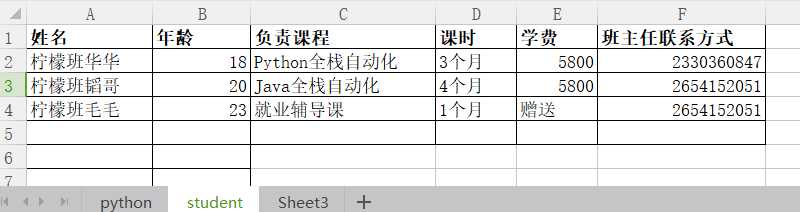
1:在利用pandas模块进行操作前,可以先引入这个模块,如下:
import pandas as pd
2:读取Excel文件的两种方式:
#方法一:默认读取第一个表单
df=pd.read_excel(‘lemon.xlsx‘)#这个会直接默认读取到这个Excel的第一个表单 data=df.head()#默认读取前5行的数据 print("获取到所有的值:\n{0}".format(data))#格式化输出
得到的结果是一个二维矩阵,如下所示:
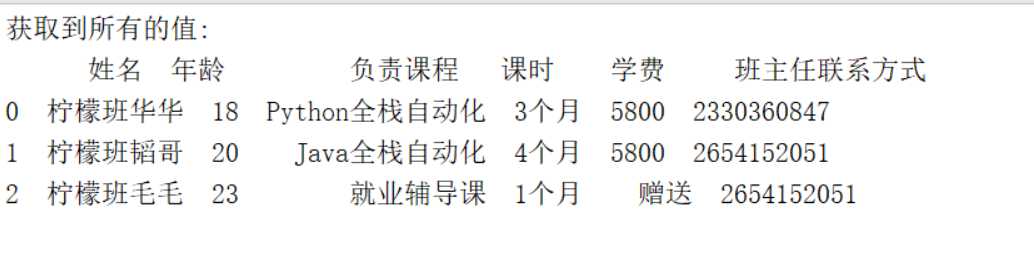
#方法二:通过指定表单名的方式来读取 df=pd.read_excel(‘lemon.xlsx‘,sheet_name=‘student‘)#可以通过sheet_name来指定读取的表单 data=df.head()#默认读取前5行的数据 print("获取到所有的值:\n{0}".format(data))#格式化输出
得到的结果如下所示,也是一个二维矩阵:
#方法三:通过表单索引来指定要访问的表单,0表示第一个表单 #也可以采用表单名和索引的双重方式来定位表单 #也可以同时定位多个表单,方式都罗列如下所示 df=pd.read_excel(‘lemon.xlsx‘,sheet_name=[‘python‘,‘student‘])#可以通过表单名同时指定多个 # df=pd.read_excel(‘lemon.xlsx‘,sheet_name=0)#可以通过表单索引来指定读取的表单 # df=pd.read_excel(‘lemon.xlsx‘,sheet_name=[‘python‘,1])#可以混合的方式来指定 # df=pd.read_excel(‘lemon.xlsx‘,sheet_name=[1,2])#可以通过索引 同时指定多个 data=df.values#获取所有的数据,注意这里不能用head()方法哦~ print("获取到所有的值:\n{0}".format(data))#格式化输出
具体结果是怎样的,同学们可以自己一个一个的去尝试,这个结果是非常有意思的,但是同时同学们也发现了,这个数据是一个二维矩阵,对于我们去做自动化测试,并不能很顺利的处理,所以接下来,我们就会详细的讲解,如何来读取行号和列号以及每一行的内容 以及制定行列的内容。
三、pandas操作Excel的行列
1:读取指定的单行,数据会存在列表里面
#1:读取指定行
df=pd.read_excel(‘lemon.xlsx‘)#这个会直接默认读取到这个Excel的第一个表单 data=df.ix[0].values#0表示第一行 这里读取数据并不包含表头,要注意哦! print("读取指定行的数据:\n{0}".format(data))
2:读取指定的多行,数据会存在嵌套的列表里面:
df=pd.read_excel(‘lemon.xlsx‘) data=df.ix[[1,2]].values#读取指定多行的话,就要在ix[]里面嵌套列表指定行数 print("读取指定行的数据:\n{0}".format(data))
3:读取指定的行列:
df=pd.read_excel(‘lemon.xlsx‘) data=df.ix[1,2]#读取第一行第二列的值,这里不需要嵌套列表 print("读取指定行的数据:\n{0}".format(data))
4:读取指定的多行多列值:
df=pd.read_excel(‘lemon.xlsx‘) data=df.ix[[1,2],[‘title‘,‘data‘]].values#读取第一行第二行的title以及data列的值,这里需要嵌套列表 print("读取指定行的数据:\n{0}".format(data))
5:获取所有行的指定列
df=pd.read_excel(‘lemon.xlsx‘) data=df.ix[:,[‘title‘,‘data‘]].values#读所有行的title以及data列的值,这里需要嵌套列表 print("读取指定行的数据:\n{0}".format(data))
6:获取行号并打印输出
df=pd.read_excel(‘lemon.xlsx‘) print("输出行号列表",df.index.values) 输出结果是: 输出行号列表 [0 1 2 3]
7:获取列名并打印输出
df=pd.read_excel(‘lemon.xlsx‘) print("输出列标题",df.columns.values) 运行结果如下所示: 输出列标题 [‘case_id‘ ‘title‘ ‘data‘]
8:获取指定行数的值:
df=pd.read_excel(‘lemon.xlsx‘) print("输出值",df.sample(3).values)#这个方法类似于head()方法以及df.values方法 输出值 [[2 ‘输入错误的密码‘ ‘{"mobilephone":"18688773467","pwd":"12345678"}‘] [3 ‘正常充值‘ ‘{"mobilephone":"18688773467","amount":"1000"}‘] [1 ‘正常登录‘ ‘{"mobilephone":"18688773467","pwd":"123456"}‘]]
9:获取指定列的值:
df=pd.read_excel(‘lemon.xlsx‘) print("输出值\n",df[‘data‘].values)
四:pandas处理Excel数据成为字典
我们有这样的数据,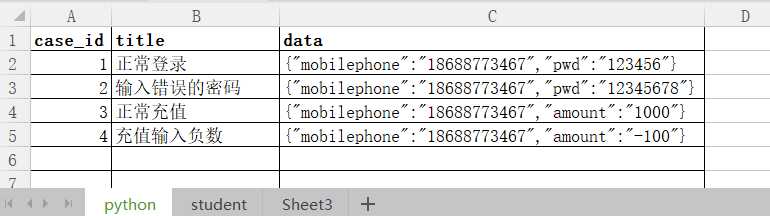 ,处理成列表嵌套字典,且字典的key为表头名。
,处理成列表嵌套字典,且字典的key为表头名。
实现的代码如下所示:
df=pd.read_excel(‘lemon.xlsx‘) test_data=[] for i in df.index.values:#获取行号的索引,并对其进行遍历: #根据i来获取每一行指定的数据 并利用to_dict转成字典 row_data=df.ix[i,[‘case_id‘,‘module‘,‘title‘,‘http_method‘,‘url‘,‘data‘,‘expected‘]].to_dict() test_data.append(row_data) print("最终获取到的数据是:{0}".format(test_data))
最后得到的结果是:
最终获取到的数据是: [{‘title‘: ‘正常登录‘, ‘case_id‘: 1, ‘data‘: ‘{"mobilephone":"18688773467","pwd":"123456"}‘}, {‘title‘: ‘输入错误的密码‘, ‘case_id‘: 2, ‘data‘: ‘{"mobilephone":"18688773467","pwd":"12345678"}‘}, {‘title‘: ‘正常充值‘, ‘case_id‘: 3, ‘data‘: ‘{"mobilephone":"18688773467","amount":"1000"}‘}, {‘title‘: ‘充值输入负数‘, ‘case_id‘: 4, ‘data‘: ‘{"mobilephone":"18688773467","amount":"-100"}‘}]
sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
df = pd.read_excel(xls, sheet_name=[0], keep_default_na=‘‘) df -> (0, df) dict(df) {0:df}