标签:des style blog http io color ar os 使用
block_dump
Linux 内核里提供了一个 block_dump 参数用来把 block 读写(WRITE/READ)状况转存(dump)到日志里,这样可以通过 dmesg 命令来查看。
该参数表示是否打开Block Debug模式,用于记录所有的读写及Dirty Block写回动作。 缺省设置:0,表示禁用Block Debug
将这个值设置为非零值,则在dmesg里记录各进程的block IO状况
dirty_background_bytes
当脏页所占的内存数量超过dirty_background_bytes时,内核的pdflush线程开始回写脏页。
dirty_background_ratio
默认值 :10
参数意义:当脏页所占的百分比(相对于所有可用内存,即空闲内存页+可回收内存页)达到dirty_background_ratio时内核的pdflush线程开始回写脏页。增大会使用更多内存用于缓冲,可以提高系统的读写性能。当需要持续、恒定的写入场合时,应该降低该数值。
注意:dirty_background_bytes参数和dirty_background_ratio参数是相对的,只能指定其中一个。当其中一个参数文件被写入时,会立即开始计算脏页限制,并且会将另一个参数的值清零。
dirty_bytes
当脏页所占的内存数量达到dirty_bytes时,执行磁盘写操作的进程自己开始回写脏数据。
注意:dirty_bytes参数和dirty_ratio参数是相对的,只能指定其中一个。当其中一个参数文件被写入时,会立即开始计算脏页限制,并且会将另一个参数的值清零
dirty_ratio
默认值:40
参数意义:当脏页所占的百分比(相对于所有可用内存,即空闲内存页+可回收内存页)达到dirty_ratio时,进程pdflush会自己开始回写脏数据。增大会使用更多系统内存用于缓冲,可以提高系统的读写性能。当需要持续、恒定的写入场合时,应该降低该数值。
dirty_background_ratio与dirty_ratio比较
dirty_ratio是属于强制性的回写,也就是说当一个内存区的脏页达到这个比例时就会触发内核内存管理把脏页强制回写的流程,但dirty_background_ratio是属于软性的行为,因为这是透过pdflush内核线程进行的流程,可以在后台执行对这些脏页面回写,并不会因此影响到当下正在执行中的过程。 所以看Linux内核中预设的比例是脏页达到5%的比例时就会先透过pdflush内核线程进行回写,当脏页达到10%比例时,就等于是一个很严重的状况,此时就会在平衡脏页面流程中触发强制的回写,让系统可以回复到原本预设合理的状态。
dirty_expire_centisecs
默认值:2999参数意义:用来指定内存中数据是多长时间才算脏(dirty)数据。指定的值是按100算做一秒计算。只有当超过这个值后,才会触发内核进程pdflush将dirty数据写到磁盘。
dirty_writeback_centisecs
默认值:499这个参数会触发pdflush回写进程定期唤醒并将old数据写到磁盘。每次的唤醒的间隔,是以数字100算做1秒。如果将这项值设为500就相当5秒唤醒pdflush进程。如果将这项值设为0就表示完全禁止定期回写数据。
drop_caches
向/proc/sys/vm/drop_caches文件中写入数值可以使内核释放page cache,dentries和inodes缓存所占的内存。
只释放pagecache:
echo 1 > /proc/sys/vm/drop_caches
只释放dentries和inodes缓存:
echo 2 > /proc/sys/vm/drop_caches
释放pagecache、dentries和inodes缓存:
echo 3 > /proc/sys/vm/drop_caches
这个操作不是破坏性操作,脏的对象(比如脏页)不会被释放,因此要首先运行sync命令。
注:这个只能是手动释放
laptop_mode
Linux 内核在 I/O 系统上支持一种“笔记本模式”。在“笔记本模式”下,内核更智能的使用 I/O 系统,它会尽量使磁盘处于低能耗的状态下。“笔记本模式”会将许多的 I/O 操作组织在一起,一次完成,而在每次的磁盘 I/O 之间是默认长达 10 分钟的非活动期,这样会大大减少磁盘启动的次数。为了完成这么长时间的非活动期,内核就要在一次活动期时完成尽可能多的 I/O 任务。在一次活动期间,要完成大量的预读,然后将所有的缓冲同步。在非活动期间,写操作会被阻挡在内存中(读操作如果无法在 Cache 中满足,则无法阻挡,因为用户无法忍受这么长时间的延迟)。
0:表示没有启用
非0:表示启用
legacy_va_layout
该文件表示是否使用最新的32位共享内存mmap()系统调用,Linux支持的共享内存分配方式包括mmap(),Posix,System VIPC。
0,使用最新32位mmap()系统调用。
1,使用2.4内核提供的系统调用。
lowmem_reserve_ratio
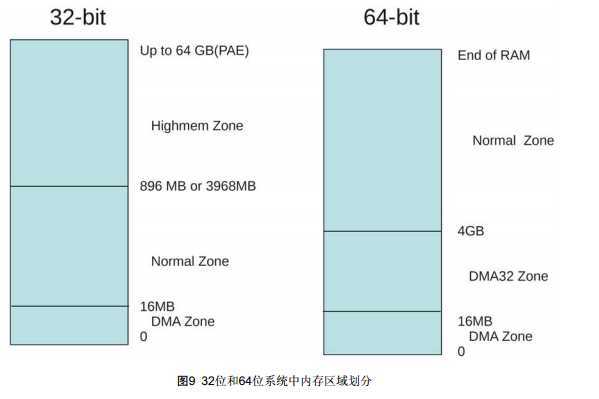
保留的lowmem,3列分别为DMA/normal/HighMem
在有高端内存的机器上,从低端内存域给应用层进程分配内存是很危险的,因为这些内存可以通过mlock()系统锁定,或者变成不可用的swap空间。在有大量高端内存的机器上,缺少可以回收的低端内存是致命的。因此如果可以使用高端内存,Linux页面分配器不会使用低端内存。这意味着,内核会保护一定数量的低端内存,避免被用户空间锁定。
这个参数同样可以适用于16M的ISA DMA区域,如果可以使用低端或高端内存,则不会使用该区域。
lowmem_reserve_ratio参数决定了内核保护这些低端内存域的强度。预留的内存值和lowmem_reserve_ratio数组中的值是倒数关系,如果值是256,则代表1/256,即为0.39%的zone内存大小。如果想要预留更多页,应该设更小一点的值。
min_free_kbytes
这个参数用来指定强制Linux VM保留的内存区域的最小值,单位是kb。VM会使用这个参数的值来计算系统中每个低端内存域的watermark[WMARK_MIN]值。每个低端内存域都会根据这个参数保留一定数量的空闲内存页。
一部分少量的内存用来满足PF_MEMALLOC类型的内存分配请求。如果进程设置了PF_MEMALLOC标志,表示不能让这个进程分配内存失败,可以分配保留的内存。并不是所有进程都有的。kswapd、direct reclaim的process等在回收的时候会设置这个标志,因为回收的时候它们还要为自己分配一些内存。有了PF_MEMALLOC标志,它们就可以获得保留的低端内存。
如果设置的值小于1024KB,系统很容易崩溃,在负载较高时很容易死锁。如果设置的值太大,系统会经常OOM。
max_map_count
进程中内存映射区域的最大数量。在调用malloc,直接调用mmap和mprotect和加载共享库时会产生内存映射区域。虽然大多数程序需要的内存映射区域不超过1000个,但是特定的程序,特别是malloc调试器,可能需要很多,例如每次分配都会产生一到两个内存映射区域。默认值是65536。
mmap_min_addr
指定用户进程通过mmap可使用的最小虚拟内存地址,以避免其在低地址空间产生映射导致安全问题;如果非0,则不允许mmap到NULL页,而此功能可在出现NULL指针时调试Kernel;mmap用于将文件映射至内存;该设置意味着禁止用户进程访问low 4k地址空间
nr_pdflush_threads
当前pdfflush线程数量,为read-only。
oom_dump_tasks
如果启用,在内核执行OOM-killing时会打印系统内进程的信息(不包括内核线程),信息包括pid、uid、tgid、vm size、rss、nr_ptes,swapents,oom_score_adj和进程名称。这些信息可以帮助找出为什么OOM killer被执行,找到导致OOM的进程,以及了解为什么进程会被选中。
如果将参数置为0,不会打印系统内进程的信息。对于有数千个进程的大型系统来说,打印每个进程的内存状态信息并不可行。这些信息可能并不需要,因此不应该在OOM的情况下牺牲性能来打印这些信息。
如果设置为非零值,任何时候只要发生OOM killer,都会打印系统内进程的信息。
默认值是1(启用)。
OOM killer(Out-Of-Memory killer):监控那些占用内存过大,尤其是瞬间很快消耗大量内存的进程,为了防止内存耗尽而内核会把该进程杀掉
oom_kill_allocating_task
控制在OOM时是否杀死触发OOM的进程。
如果设置为0,OOM killer会扫描进程列表,选择一个进程来杀死。通常都会选择消耗内存内存最多的进程,杀死这样的进程后可以释放大量的内存。
如果设置为非零值,OOM killer只会简单地将触发OOM的进程杀死,避免遍历进程列表(代价比较大)。如果panic_on_oom被设置,则会忽略oom_kill_allocating_task的值。
默认值是0。
panic_on_oom
控制内核在OOM发生时时是否panic。
如果设置为0,内核会杀死内存占用过多的进程。通常杀死内存占用最多的进程,系统就会恢复。
如果设置为1,在发生OOM时,内核会panic。然而,如果一个进程通过内存策略或进程绑定限制了可以使用的节点,并且这些节点的内存已经耗尽,oom-killer可能会杀死一个进程来释放内存。在这种情况下,内核不会panic,因为其他节点的内存可能还有空闲,这意味着整个系统的内存状况还没有处于崩溃状态。
如果设置为2,在发生OOM时总是会强制panic,即使在上面讨论的情况下也一样。即使在memory cgroup限制下发生的OOM,整个系统也会panic。
默认值是0。
将该参数设置为1或2,通常用于集群的故障切换。选择何种方式,取决于你的故障切换策略。
overcommit_memory
默认值为:0从内核文档里得知,该参数有三个值,分别是:0:当用户空间请求更多的的内存时,内核尝试估算出剩余可用的内存。
1:当设这个参数值为1时,内核允许超量使用内存直到用完为止,主要用于科学计算
2:当设这个参数值为2时,内核会使用一个决不过量使用内存的算法,即系统整个内存地址空间不能超过swap+50%的RAM值,50%参数的设定是在overcommit_ratio中设定。
overcommit_ratio
默认值为:50这个参数值只有在vm.overcommit_memory=2的情况下,这个参数才会生效。该值为物理内存比率,当overcommit_memory=2时,进程可使用的swap空间不可超过PM * overcommit_ratio/100
page-cluster
该参数控制一次写入或读出swap分区的页面数量。它是一个对数值,如果设置为0,表示1页;如果设置为1,表示2页;如果设置为2,则表示4页。如果设置为0,则表示完全禁止预读取。
默认值是3(一次8页)。如果swap比较频繁,调整该值的收效不大。
该参数的值越小,在处理最初的页面错误时延迟会越低。但如果随后的页面错误对应的页面也是在连续的页面中,则会有I/O延迟。
percpu_pagelist_fraction
This is the fraction of pages at most (high mark pcp->high) in each zone that are allocated for each per cpu page list.
The min value for this is 8. It means that we don‘t allow more than 1/8th of pages in each zone to be allocated in any single per_cpu_pagelist.
This entry only changes the value of hot per cpu pagelists. User can specify a number like 100 to allocate 1/100th of each zone to each per cpu page list.
The batch value of each per cpu pagelist is also updated as a result. It is set to pcp->high/4. The upper limit of batch is (PAGE_SHIFT * 8)
The initial value is zero. Kernel does not use this value at boot time to set the high water marks for each per cpu page list. If the user writes ‘0‘ to this sysctl, it will revert to this default behavior.
stat_interval
VM信息更新频率,默认每1秒更新一次
scan_unevictable_pages
非零:扫描所有可回收的节点放到回收列表里
Swappiness
该参数控制是否使用swap分区,以及使用的比例。设置的值越大,内核会越倾向于使用swap。如果设置为0,内核只有在看空闲的和基于文件的内存页数量小于内存域的高水位线(应该指的是watermark[high])时才开始swap。
默认值是60。
vfs_cache_pressure
控制内核回收dentry和inode cache内存的倾向。
默认值是100,内核会根据pagecache和swapcache的回收情况,让dentry和inode cache的内存占用量保持在一个相对公平的百分比上。
减小vfs_cache_pressure会让内核更倾向于保留dentry和inode cache。当vfs_cache_pressure等于0,在内存紧张时,内核也不会回收dentry和inode cache,这容易导致OOM。如果vfs_cache_pressure的值超过100,内核会更倾向于回收dentry和inode cache。
下面是pdflush线程(用于下刷缓存)根据部分参数执行的过程:
pdflush 的行为受/proc/sys/vm中的参数控制
/proc/sys/vm/dirty_writeback_centisecs(200):1/100秒,多长时间唤醒pdflush将缓存页数据写入磁盘。默认5秒唤醒2个或更多线程。
pdflush的第一件事是读取
/proc/sys/vm/dirty_expire_centisecs(300)
1/100秒。脏数据的过期时间(旧数据),在下一个周期内被写入磁盘。
第二件事是判断内存是否到了要写入磁盘的限额,有参数决定:
/proc/sys/vm/dirty_background_ratio(5:4G的大约是168M)
百分值,保留过期页缓存的最大值。是以MmeFree+Cached-Mapped的值为基准的
以下参数也会影响到pdflush
/proc/sys/vm/dirty_ratio(default
(10)
总内存的最大百分比,系统所能拥有的最大脏页缓存的总量。超过这个值,开启pdflush写入磁盘。如果cached增长快于pdflush,那么整个系统在40%的时候遇到I/O瓶颈,所有的I/O都要等待cache被pdflush进磁盘后才能重新开始。
标签:des style blog http io color ar os 使用
原文地址:http://www.cnblogs.com/yuzhaoxin/p/4083612.html