标签:stc poll 很多 接口 端口 分布式 原因 批量提交 避免
今天给大家分享一个大数据里面很火的技术——Kafka,Kafka 是一个分布式的消息系统,其高性能在圈内很出名。本人阅读过多个大数据生态的开源技术的源码,个人感觉 Kafka 的源码质量是比较高的一个,如果有同学感兴趣的话,可以拿来阅读一下。网上也有不少的文章分析 Kafka 的性能为什么那么好,但是我感觉很多文章都没说到点上,所以今天借着这个机会跟大家交流一下 kafka 的性能为什么那么好?优秀设计之基于NIO编程
Kafka 底层的 IO 用的是 NIO,这个事虽然简单,但是也需要提一提。我们开发一个分布式文件系统的时候避免不了需要思考需要什么样的 IO?BIO 性能较差,NIO 性能要比 BIO 要好很多,而且编程难度也不算大,当然性能最好的那就是 AIO 了,但是 AIO 编程难度较大,代码设计起来较为复杂,所以 Kafka 选择的是 NIO,也是因为这些原因,目前我们看到很多开源的技术也都是用的 NIO。
优秀设计之高性能网络设计
个人认为 Kafka 的网络部分的代码设计是整个 Kafka 比较精华的部分。我们接下来一步一步分析一下 Kafka Server 端为了支持超高并发是如何设计其网络架构的?我们先不看 kafka 本身的网络架构,我们先简单了解一下 Reactor 模式:
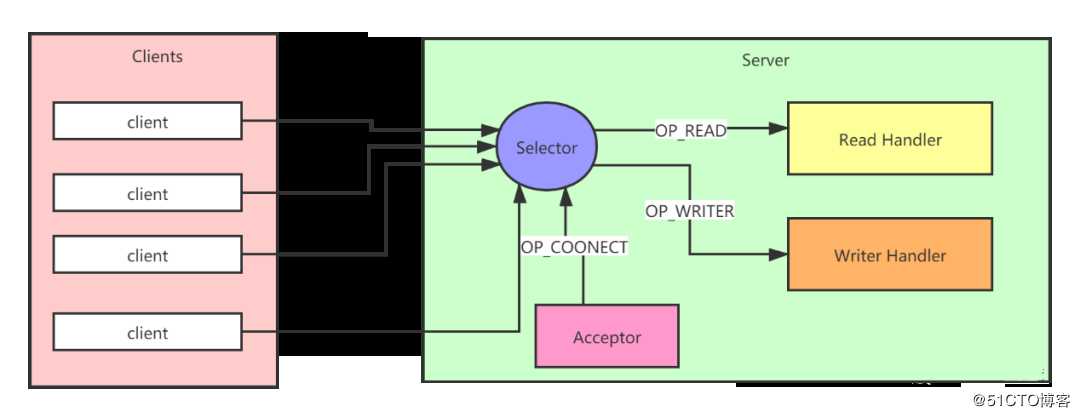
图1 Reactor模型
(1) 首先服务端创建了 ServerSocketChannel 对象并在 Selector 上注册了 OP_ACCEPT 事件,ServerSocketChannel 负责监听指定端口上的连接。
(2) 当客户端发起到服务端的网络连接请求时,服务端的 Selector 监听到 OP_ACCEPT 事件,会触发 Acceptor 来处理 OP_ACCEPT 事件.
(3) 当 Acceptor 接收到来自客户端的 socket 请求时会为这个连接创建对应的 SocketChannel,将这个 SocketChannel 设置为非阻塞模式,并在 Selector 上注册它关注的 I/O 事件。如:OP_WRITER,OP_READ 事件。此时客户端与服务端的 socket 连接正式建立完成。
(4) 当客户端通过上面建立好的 socket 连接向服务端发送请求时,服务端的 Selector 会监听到 OP_READ 事件,并触发对应的处理逻辑(read handler)。服务端像客户端发送响应时,服务端的 Selector 可以监听到 OP_WRITER 事件,并触发对应的处理逻辑(writer handler)。
我们看到这种设计就是将所有的事件处理都在同一个线程中完成。这样的设计适合用在客户端这种并发比较小的场景。如果并发量比较大,或者有个请求处理逻辑要较为复杂,耗时较长,那么就会影响到后续所有的请求,接着就会导致大量的任务超时。要解决这个问题,我们对上述的架构稍作调整,如下图所示:
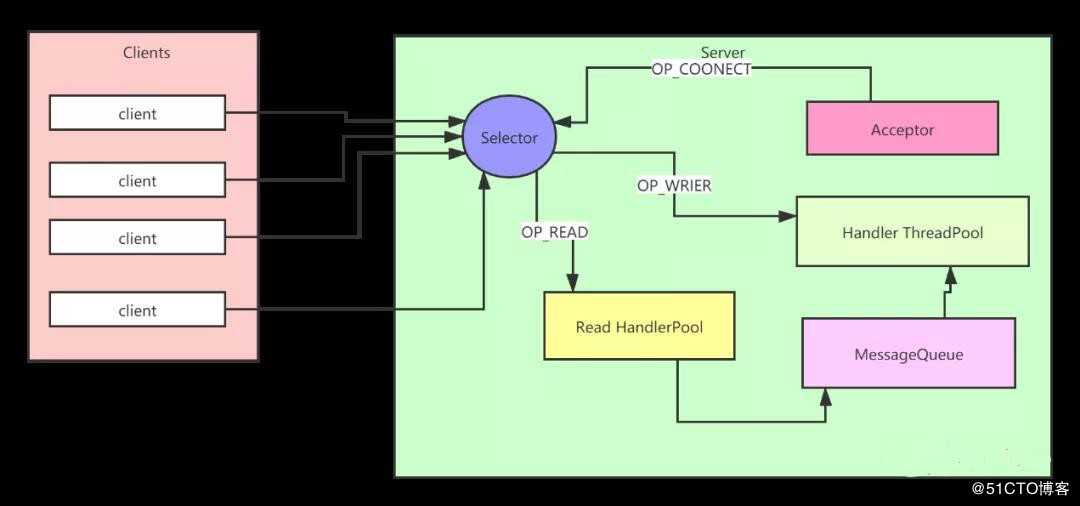
图2 Reactor 改进模型
Accept 单独运行在一个线程中,这个线程使用 ExecutorService 实现,因为这样的话,当 Accept 线程异常退出的时候,ExecutorService 也会创建新的线程进行补偿。Read handler 里面也是一个线程池,这个里面所有的线程都注册了 OP_READ 事件,负责接收客户端传过来的请求,当然也是一个线程对应了多个 socket 连接。Read handler 里的线程接收到请求以后把请求都存入到 MessageQueue 里面。Handler Poll 线程池中的线程就会从 MessageQueue 队列里面获取请求,然后对请求进行处理。这样设计的话,即使某个请求需要大量耗时,Handler Poll 线程池里的其它线程也会去处理后面的请求,避免了整个服务端的阻塞。当请求处理完了以后 handler Pool 中的线程注册 OP_WRITER 事件,实现往客户端发送响应的功能。通过这种设计就解决了性能瓶颈的问题,但是如果突然发生了大量的网络 I/O。单个 Selector 可能会在分发事件的时候成为性能瓶颈。所以我们很容易想的到应该将上面的单独的 Selector 扩展为多个,所以架构图就变成了如下的这幅图:
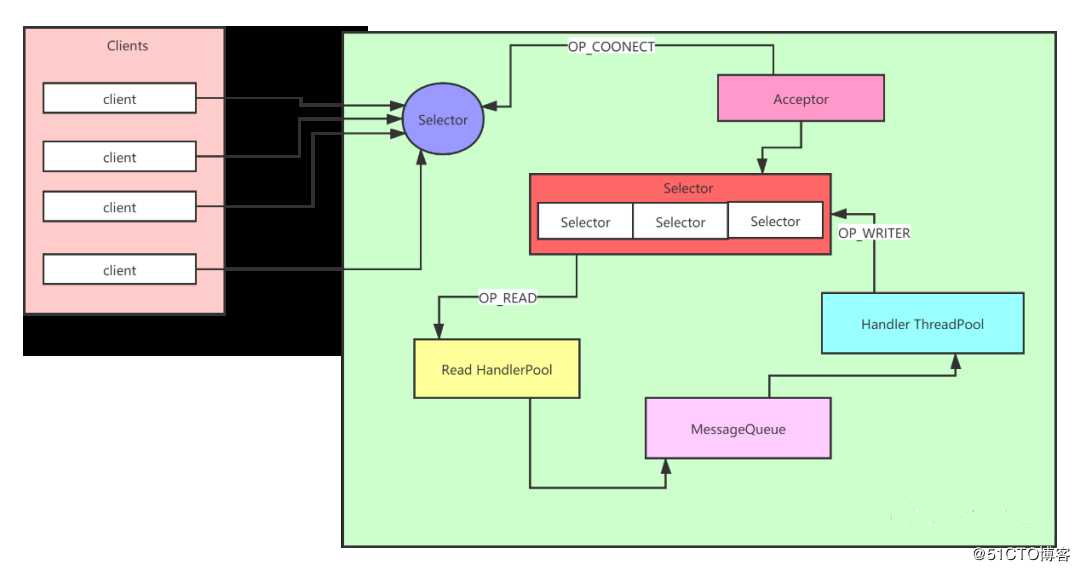
图3 Reactor 改进模型
如果我们理解了上面的设计以后,再去理解 Kafka 的网络架构就简单多了,如下图所示:
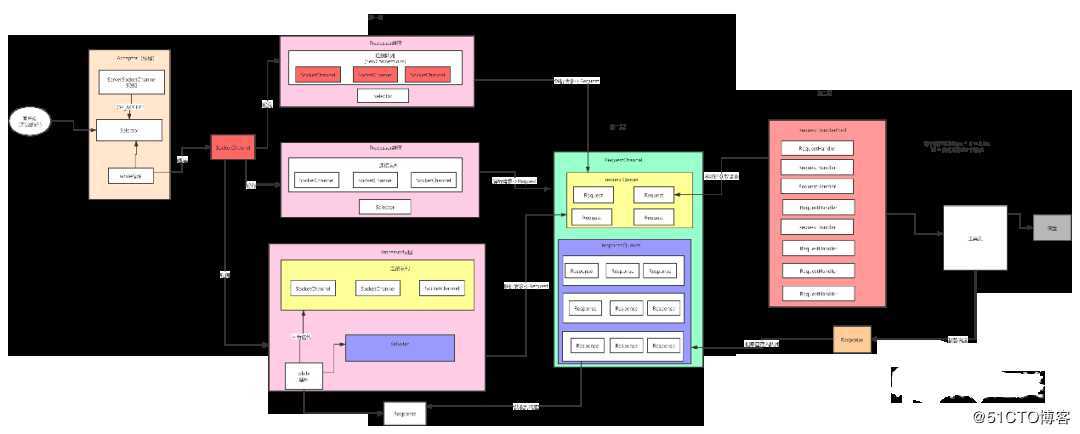
图4 Kafka 网络模型
这个就是 Kafka 的 Server 端的网络架构设计,就是按照前面的网路架构演化出来的。Accepetor 启动了以后接收连接请求,接收到了请求以后把请求发送给一个线程池(Processor)线程池里的每个线程获取到请求以后,把请求封装为一个个 SocketChannel 缓存在自己的队列里面。接下来给这些 SocketChannel 注册上 OP_READ 事件,这样就可以接收客户端发送过来的请求了,Processor 线程就把接收到的请求封装成 Request 对象存入到 RequestChannel 的 RequestQueue 队列。接下来启动了一个线程池,默认是 8 个线程来对队列里面的请求进行处理。处理完了以后把对应的响应放入到对应 ReponseQueue 里面。每个 Processor 线程从其对应的 ReponseQueue 里面获取响应,注册 OP_WRITER 事件,最终把响应发送给客户端。个人觉得 Kafka 的网络设计部分代码设计得很漂亮,就是因为这个网络架构,保证了 kafka 的高性能。
优秀设计之顺序写
一开始很多人质疑 kafka,大家认为一个架构在磁盘之上的系统,性能是如何保证的。这点需要跟大家解释一下,客户端写入到 Kafka 的数据首先是写入到操作系统缓存的(所以很快),然后缓存里的数据根据一定的策略再写入到磁盘,并且写入到磁盘的时候是顺序写,顺序写如果磁盘的个数和转数跟得上的话,都快赶上写内存的速度了!
优秀设计之跳表、稀松索引、零拷贝
上面我们看到 kafka 通过顺序写的设计保证了高效的写性能,那读数据的高性能又是如何设计的呢?kafka 是一个消息系统,里面的每个消息都会有 offset,如果消费者消费某个 offset 的消息的时候是如何快速定位呢?
01 / 跳 表
如下截图是我们线上的 kafka 的存储文件,里面有两个重要的文件,一个是 index 文件,一个是 log 文件。
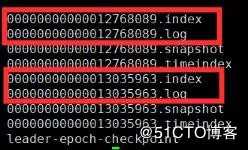
图5 Kafka 存储文件
log 文件里面存储的是消息,index 存储的是索引信息,这两个文件的文件名都是一样的,成对出现的,这个文件名是以 log 文件里的第一条消息的 offset 命名的,如下第一个文件的文件名叫 00000000000012768089,代表着这个文件里的第一个消息的 offset 是 12768089,也就是说第二条消息就是 12768090 了。
在 kafka 的代码里,我们一个的 log 文件是存储是 ConcurrentSkipListMap 里的,是一个 map 结构,key 用的是文件名(也就是 offset),value 就是 log 文件内容。而 ConcurrentSkipListMap 是基于跳表的数据结构设计的。
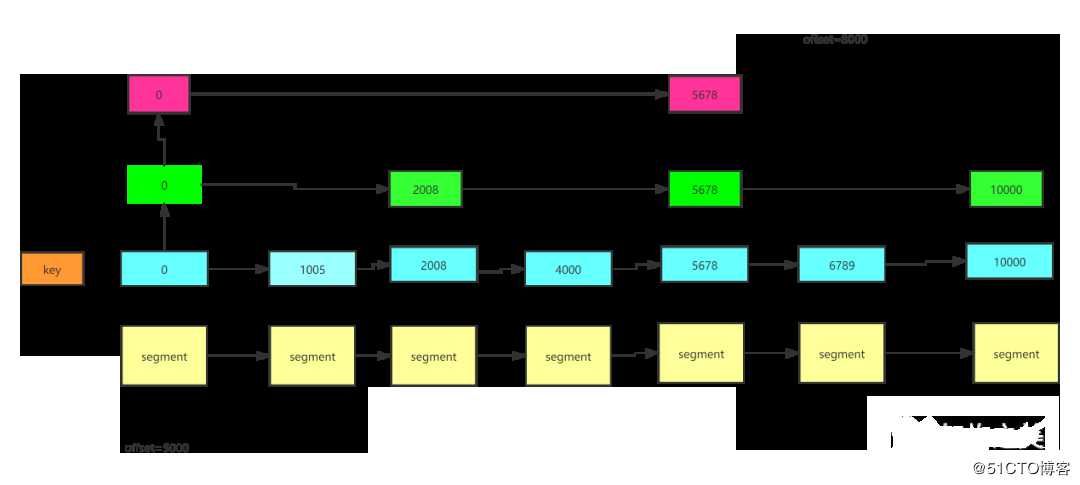
图6 concurrentSkipListMap设计
这样子,我们想要消费某个大小的 offset,可以根据跳表快速的定位到这个 log 文件了。
02 / 稀松索引经过上面的步骤,我们仅仅也就是定位了 log 文件而已,但是要消费的数据具体的物理位置在哪儿?,我们就得靠 kafka 的稀松索引了。假设刚刚我们定位要消费的偏移量是在 00000000000000368769.log 文件里,如果说要整个文件遍历,然后一个 offset 一个 offset 比对,性能肯定很差。这个时候就需要借助刚刚我们看到的 index 文件了,这个文件里面存的就是消息的 offset 和其对应的物理位置,但 index 不是为每条消息都存一条索引信息,而是每隔几条数据才存一条 index 信息,这样 index 文件其实很小,也就是这个原因我们就管这种方式叫稀松索引。
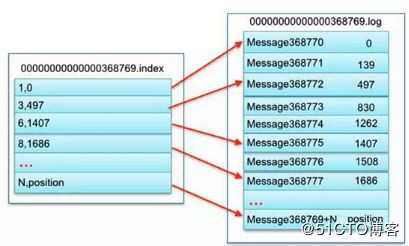
图7 稀松索引
比如现在我们要消费 offset 等于 368776 的消息,如何根据 index 文件定位呢?
(1)首先在 index 文件里找,index 文件存储的数据都是成对出现的,比如我们到的 1,0 代表的意思是,offset=368769+1=368770 这条信息存储的物理位置是 0 这个位置。那现在我们现在想要定位的消息是 368776 这条消息,368776 减去 368769 等于 7,我们就在 index 文件里找 offset 等于 7 对应的物理位置,但是因为是稀松索引,我们没找到,不过我们找到了 offset 等于 6 的物理值 1407。
(2)接下来就到 log 文件里读取文件的 1407 的位置,然后遍历后面的 offset,很快就可以遍历到 offset 等于 7(368776)的数据了,然后从这儿开始消费即可。
03 / 零拷贝接下来消费者读取数据的流程用的是零拷贝技术,我们先看一下如下是非零拷贝的流程:
(1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存;
(2)应用程序将数据从内核空间读入用户空间缓冲区;
(3)应用程序将读到数据写回内核空间并放入 socket 缓冲区;
(4)操作系统将数据从 socket 缓冲区复制到网卡接口,此时数据才能通过网络发送。
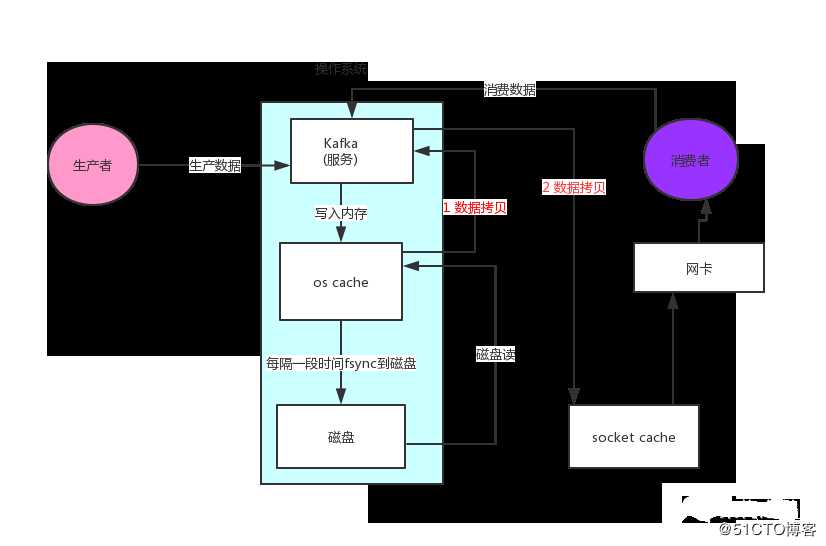
图8 非零拷贝流程
上图我们发现里面会涉及到两次数据拷贝,Kafka 这儿为了提升性能,所以就采用了零拷贝,零拷贝”只用将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面缓存),避免了重复复制操作,提升了整个读数据的性能。
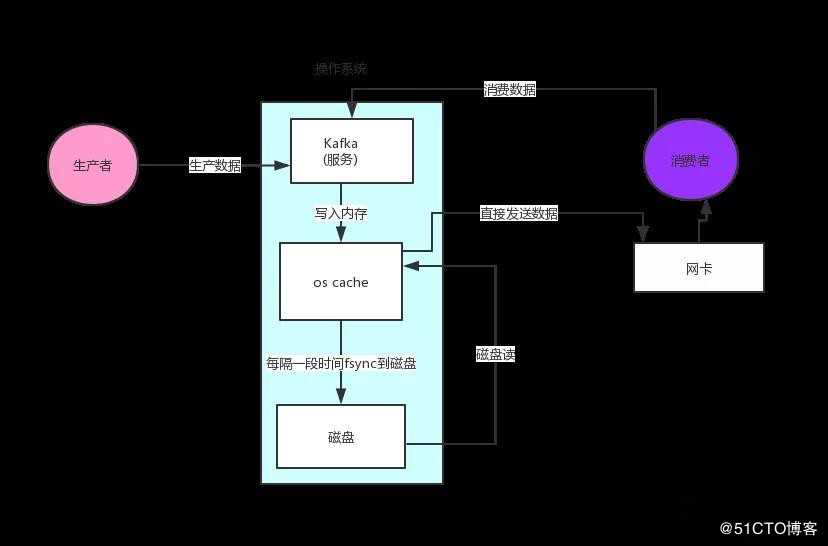
图9 零拷贝流程
优秀设计之批处理
在 kafka-0.8 版本的设计中,生产者往服务端发送数据,是一条发送一次,这样吞吐量低,后来的版本里面加了缓冲区和批量提交的概念,一下子吞吐量提高了很多。下图就是修改过后的生产者发送消息的原理图:
(1) 消费先被封装成为 ProducerRecord 对象.
(2)对消息进行序列化(因为涉及到网络传输).
(3)使用分区器进行分区(到这儿就决定了这个消息要被发送到哪儿了).
(4)接着下来这条消息不着急被发送出去,而是被存到缓冲区里.
(5)会有一个 sender 线程,从缓冲区里取数据,把多条数据封装成一个批次,再一把发送出去,因为有了这个批量发送的设计,吞吐量成倍的提升了。
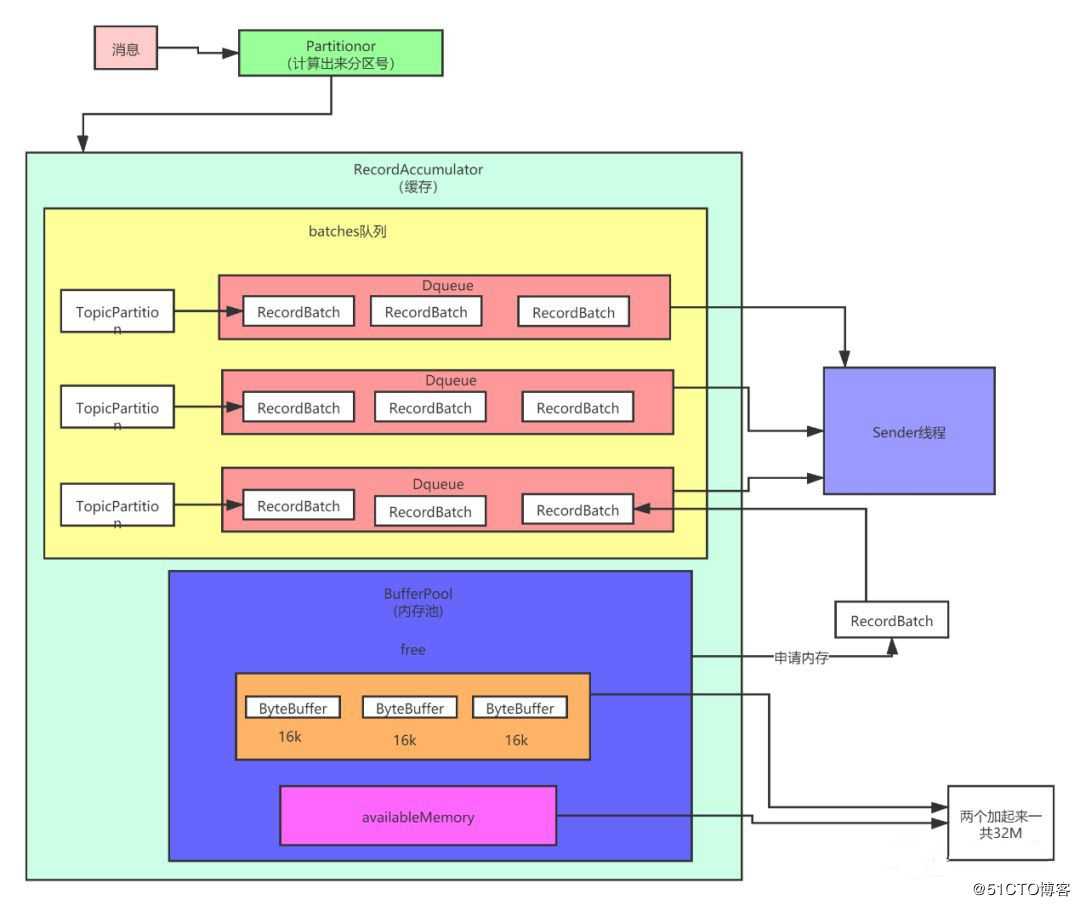
图10 缓存区设计
这个缓存区里的代码技术含量很高,感兴趣的同学,可以自己去阅读以下源码。今天 Kafka 就先给大家分析到这儿了!
更多免费资料及视频
标签:stc poll 很多 接口 端口 分布式 原因 批量提交 避免
原文地址:https://blog.51cto.com/jssforever/2501375