内存是用于存放数据的硬件
程序执行前需要先放到内存中才能被cpu处理
如果计算机"按字节编址", 每个存储单元大小为8 bit
如果计算机"按字编址", 每个存储单元大小为16 bit
指令的编指一般采用逻辑地址, 即相对地址
物理地址 = 起始地址 + 逻辑地址 (理解)
编译 : 由编译程序将用户源代码编译成若干个目标模块
链接 : 由连接程序将编译后形成的一组目标模块以及所需函数连接在一起, 形成一个完整的装入模块
链接的三种方式 :
装入 : 由装入程序将装入模块装入内存运行
装入的三种方式:
绝对装入 : 在编译时, 如果知道程序将放到内存的哪个位置, 编译程序将产生绝对地址的目标代码, 装入程序按照装入模块中的地址, 将程序和数据装入内存 ------灵活性低, 只适合单道程序环境
静态重定位 : 又称为可重定位装入. 编译, 链接后的装入模块地址都是从0开始的, 指令中使用的地址和数据存放的地址都是相对于起始地址而言的逻辑地址. 可以根据内存的当前状况将装入模块装入到内存的适当位置. 装入时对地址进行"重定位", 逻辑地址变换为物理地址(地址变换是在装入时一次完成的).
动态重定位 : 装入程序把装入模块装入内存后不会立即把逻辑地址转换为物理地址, 而是把地址转换推迟到程序真正要执行时才进行. 因此装入内存后所有的地址依然是逻辑地址. 这种方式需要一个重定位寄存器(存放装入模块的起始位置)的支持
进程应该放在内存的哪里?
操作系统如何记录哪些内存区域已经被分配了, 哪些还空闲?
当进程运行结束之后, 如何将进程占用的内存空间释放?
操作系统负责内存空间的分配与回收
操作系统需要提供某种技术从逻辑上对内存空间进行扩充
操作系统需要实现地址转换功能, 负责程序的逻辑地址和物理地址的转换
操作系统需要提供内存保护功能, 保证各进程在各自存储空间内运行, 互不干扰
实现内存保护的两种方法:
覆盖, 交换, 虚拟存储技术常用于实现内存空间的扩充
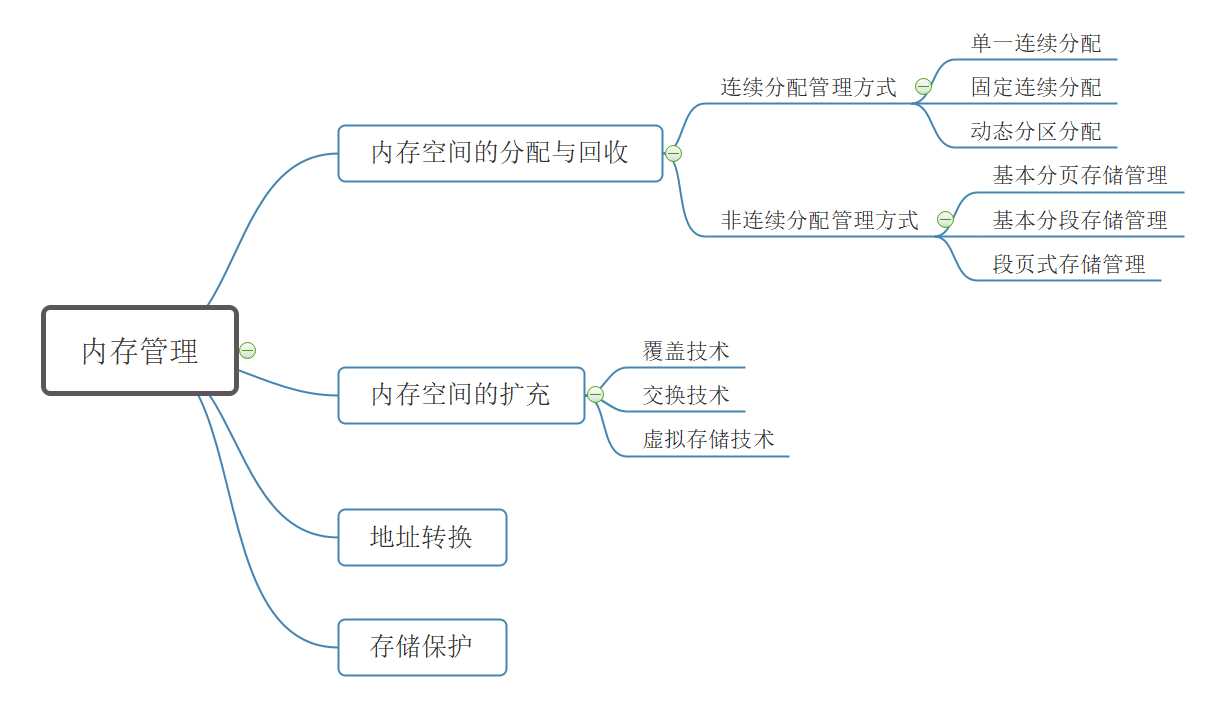
覆盖技术的思想 : 将程序分为多个段, 常用的段常驻内存, 不常用的段在需要的时候调入内存
内存中分为一个"固定区" 和若干个"覆盖区", 常用的段放在固定区, 不常用的段放在覆盖区
缺点 : 必须由程序员声明覆盖结构, 对用户不透明, 增加了用户的编程负担, 覆盖技术只用于早期的操作系统中.
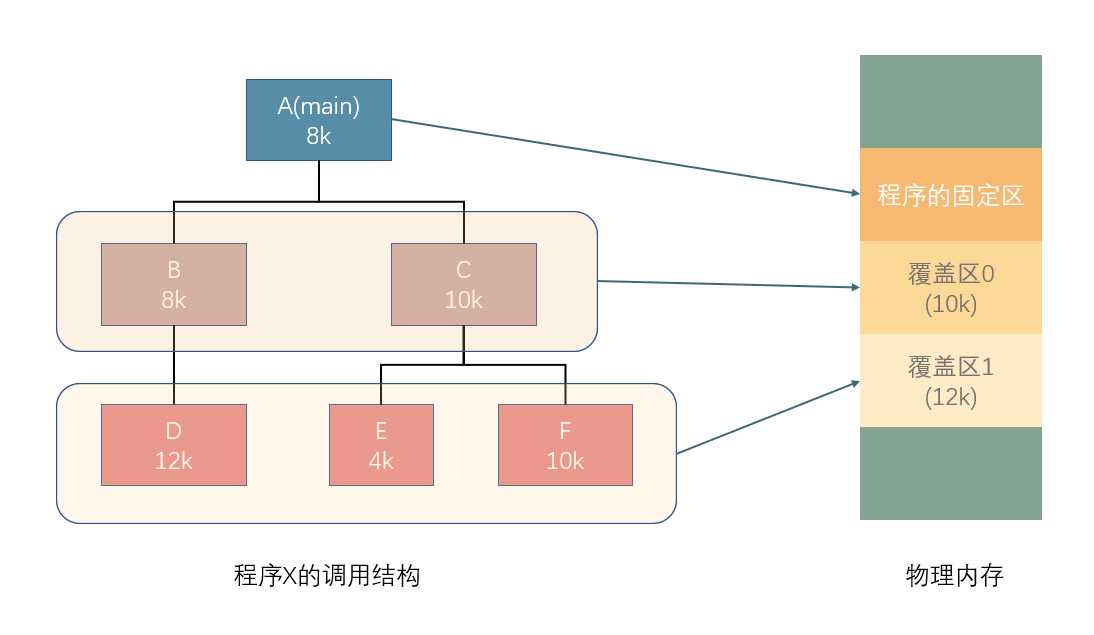
交换技术的思想 : 内存空间紧张时, 系统将内存中某些进程暂时换出外存, 把外存中某些已具备运行条件的进程换入内存(即进程在内存与磁盘间动态调度)
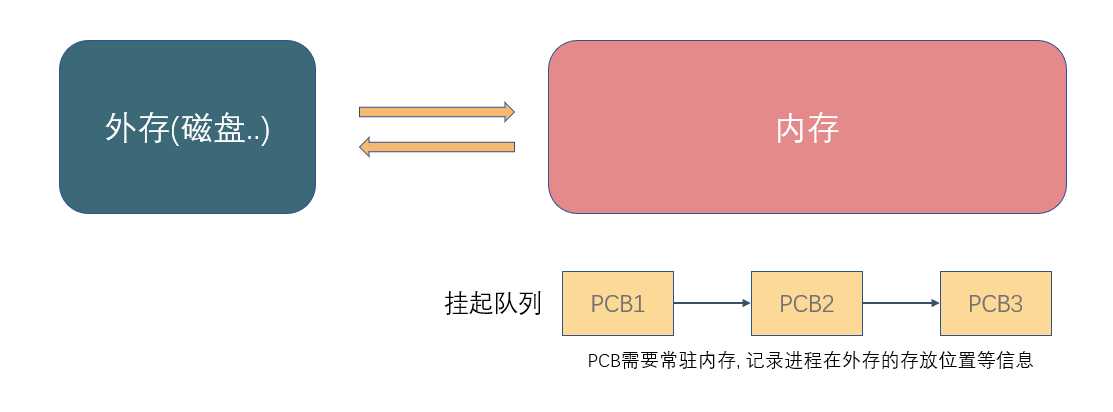
在单一连续分配的方式中, 内存被分为系统区和用户区, 系统区用于存放操作系统的相关数据, 用户区用于存放用户进程的相关数据, 内存中只能有一道用户程序, 用户程序独占整个用户区空间.
优点 : 实现简单, 无外部碎片; 可以采用覆盖技术扩充内存; 不一定需要采取内存保护
缺点 : 只能用于单用户, 单任务的操作系统中; 有内部碎片; 存储器利用率极低
内部碎片 : 分配给某进程的内存区域有一部分没有用上, 即存在" 内部碎片 ".
外部碎片 : 内存中的某些空闲分区由于太小而难以利用

在产生了支持多道程序的系统后, 为了能在内存中装入多道程序而互相之间不产生干扰, 将整个用户区划分为若干个固定大小的分区(分区大小可以相等也可以不相等), 在每个分区中只能装入一道作业, 形成了最早的可运行多道程序的内存管理方式.
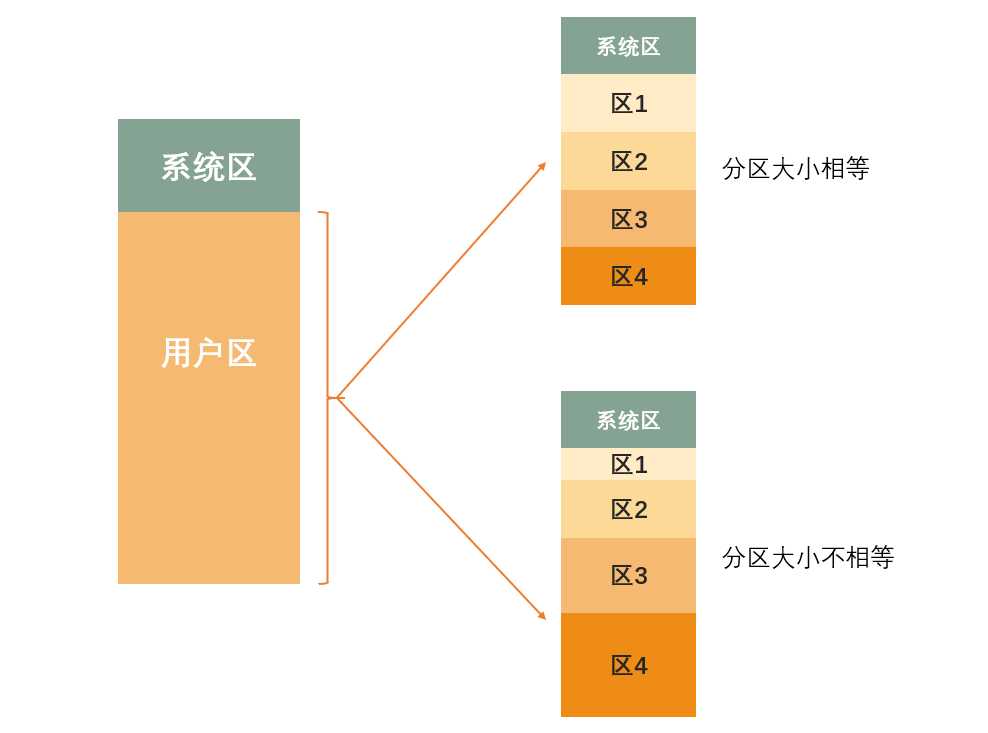
操作系统建立一个数据结构----分区说明表, 来实现各个分区的分配和回收, 每个表对应一个分区, 通常按分区大小排列. 每个表项包括对应分区的大小, 起始地址, 状态
优点 : 实现简单, 无外部碎片;
缺点 : 有内部碎片; 存储器利用率不高;
动态分区分配又称为可变分区分配, 这种分配方式不会预先划分内存分区. 而是在进程装入内存时根据进程大小动态地建立分区, 并使得分区的大小正好适合进程的需要.
几个问题 :
- 系统用什么数据结构记录内存的使用情况?
- 当多个空闲分区都满足需求应该选择哪个分区进行分配?
- 如何进行分区的分配和回收操作?
常用的数据结构 :
空闲分区表, 空闲分区链
动态分配不会产生内部碎片, 而会产生外部碎片, 外部碎片可以通过" 紧凑"的方式解决(把基地址迁移)
每次都从低地址开始查找, 找到第一个能满足大小的空闲分区
实现 : 把空闲分区按地址递增的次序排列.
每次分配内存时顺序地查找空闲分区链, 找到大小能满足要求的第一个空闲分区.
优先使用小的空闲分区
实现 : 空闲分区按容量递增次序链接.
每次分配内存时顺序查找空闲分区链, 找到大小能满足要求的第一个空闲分区
缺点 : 每次都选择最小的分区进行分配, 会留下越来越多的容量很小难以利用的内存块, 即产生很多的外部碎片
优先使用大的空闲分区
实现 : 空闲分区按容量递减次序链接
缺点 : 每次都选用最大的分区进行分配, 当较大的连续空闲区被小号之后, 如果有大进程到来则没有内存分区可以利用
在首次适应算法的基础上, 每次都从上次查找结束的位置开始查找空闲分区链(表), 找到大小能满足的第一个空闲分区
缺点 : 邻近适应算法导致无论低地址还是高地址的空闲分区都有相同的概率被使用, 也就导致了高地址部分的大分区更可能被使用划分为小分区, 最后导致没有大分区可用
综合来看, 首次适应算法的性能最好
算法开销大 : 最佳适应法, 最坏适应法 ( 需要经常排序)
算法开销小 : 首次适应算法, 邻近适应算法
ref : https://www.bilibili.com/video/BV1YE411D7nH?p=36
王道考研视频的学习笔记, 顺便重新用ppt画了一下图, 主要是学习一下ppt作图..
原文地址:https://www.cnblogs.com/roccoshi/p/13052164.html