标签:提升 param 特征 任务 研究 问题: mic cti ext
文章内容主要整理自Sinno Jialin Pan and Qiang Yang的论文《A survey on transfer Learning》。
在机器学习、深度学习和数据挖掘的大多数任务中,我们都会假设training和inference时,采用的数据服从相同的分布(distribution)、来源于相同的特征空间(feature space)。但在现实应用中,这个假设很难成立,往往遇到一些问题:
1、带标记的训练样本数量有限。比如,处理A领域(target domain)的分类问题时,缺少足够的训练样本。同时,与A领域相关的B(source domain)领域,拥有大量的训练样本,但B领域与A领域处于不同的特征空间或样本服从不同的分布。
2、数据分布会发生变化。数据分布与时间、地点或其他动态因素相关,随着动态因素的变化,数据分布会发生变化,以前收集的数据已经过时,需要重新收集数据,重建模型。
这时,知识迁移(knowledge transfer)是一个不错的选择,即把B领域中的知识迁移到A领域中来,提高A领域分类效果,不需要花大量时间去标注A领域数据。迁移学习,做为一种新的学习范式,被提出用于解决这个问题。
迁移学习的研究来源于一个观测:人类可以将以前的学到的知识应用于解决新的问题,更快的解决问题或取得更好的效果。迁移学习被赋予这样一个任务:从以前的任务当中去学习知识(knowledge)或经验,并应用于新的任务当中。换句话说,迁移学习目的是从一个或多个源任务(source tasks)中抽取知识、经验,然后应用于一个目标领域(target domain)当中去。
自1995年以来,迁移学习吸引了众多的研究者的目光,迁移学习有很多其他名字:学习去学习(Learning to learn)、终身学习(life-long learning)、推导迁移(inductive transfer)、知识强化(knowledge consolidation)、上下文敏感性学习(context-sensitive learning)、基于知识的推导偏差(knowledge-based inductive bias)、累计/增量学习(increment / cumulative learning)等。
领域(domain)和任务(task)定义:
领域由两个部分组成:特征空间(feature space)X和特征空间的边缘分布P(x),其中,x={x1,x2......xn} 属于X。如果两个领域不同,它们的特征空间或边缘概率分布不同。领域表示成D={X,P(x)}。
任务组成:给定一个领域D={X,P(x)}的情况下,一个任务也包含两个部分:标签空间Y和一个目标预测函数f(.)。一个任务表示为:T={Y,f(.)}。目标预测函数不能被直接观测,但可以通过训练样本学习得到。从概率论角度来看,目标预测函数f(.)可以表示为P(Y|X)。任务表示成T={Y,P(Y|X)}
一般情况下,只考虑只存在一个source domain Ds 和一个target domain Dt的情况。其中,源领域Ds = {(xs1,ys1),(xs2,ys2)......(xsns,ysns)},xsi 属于Xs,表示源领域的观测样本,ysi属于Ys,表示源领域观测样本xsi对应的标签。目标领域Dt = {(xt1,yt1),(xt2,yt2).......(xtnt,ytnt)},xti属于Xt,表示目标领域观测样本,ysi属于Yt,表示目标领域xti对应的输出。通常情况下,源领域观测样本数目ns与目标领域观测样本数目nt存在如下关系:1<= nt << ns。
基于以上的符号定义,给出正式的迁移学习的定义:在给定源领域Ds和源领域学习任务Ts、目标领域Dt和目标领域任务Tt的情况,且Ds 不等于Dt或Ts不等于Tt,情况下;迁移学习使用源领域Ds和Ts中的知识提升或优化目标领域Dt中目标预测函数ft(.)的学习效果。
通过以上的定义可以发现:
1)、领域D=(X,P(x)),当源和目标领域D不同时,存在两种情况:(1)Xs不等于XT,源领域和目标领域的特征空间不同;(2)P(xs)不等于P(xt),即源空间和目标空间的特征空间相同,但观测样本X的边缘分布不同。
2)任务T={Y,P(Y|X)},当源和目标领域T不同时,存在两种情况:(1)Ys不等于Yt,源领域的标签空间与目标领域的标签空间不同;(2)P(Ys|Xs)不等于P(Yt|Xt),即源领域和目标领域的条件概率分布不同。
在迁移学习领域有三个研究问题:(1)、迁移什么;(2)、如何迁移;(3)、什么时候迁移。
1)迁移什么:那一部分知识可以在多个领域或任务之间迁移,即多个领域或任务知识的共同部分,通过从源领域学习这部分共同的知识,提升目标领域任务的效果。
关注迁移什么知识时,需要注意negative transfer问题:当源领域和目标领域之间没有关系,却要在之间强制迁移知识是不可能成功的。极端情况下,反倒会影响目标领域任务学习的效果,这种情况称为负迁移(negative transfer),需要尽力避免。
2)找到了迁移什么,接下来需要解决如何迁移:怎么做知识迁移。什么时候迁移:在什么情况下、什么时候,可以做知识的迁移。
推导学习(inductive learning)与转导学习(tranductive learning)的区别:
推到学习:需要先用一些样本(training set)建立一个模型,再基于建立好的模型去去预测新的样本(testing set)的类型。以分类为例,推到学习就是一个经典的贝叶斯决策,通过贝叶斯共识:P(Y|X)=P(X|Y)*P(Y)/ P(X),建立后验概率分布P(Y|X),进而预测测试样本类别。缺点就是必须先建立一个模型,很多时候建立效果好的模型并不容易,特别是当带标记的训练样本少、无标记的测试样本非常多时。那么能否直接利用大量无标记的测试样本来识别样本类别呢?由此产生了转到学习方法。
转导学习:不需要建立后验概率模型,直接从无标记的测试样本X出发,构建P(X)的分布,对测试样本分类。与推到学习相比,转到学习也有它的缺点:因为是直接基于P(X)处理,转导学习的测试样本必须预先已知。
基于迁移学习的定义中源领域和目标领域D和任务T的不同,迁移学习可以分成三类:推导迁移学习(inductive transfer learning),转导迁移学习(tranductive transfer learning)和无监督迁移学习(unsupervised transfer learning)
1、推导迁移学习定义:给定源领域Ds和源领域学习任务Ts、目标领域Dt和目标领域任务Tt的情况,且Ts不等于Tt,情况下;推导迁移学习使用源领域Ds和Ts中的知识提升或优化目标领域Dt中目标预测函数ft(.)的学习效果。
可见,在推导迁移学习中,源任务(source task)与目标任务(target task)一定不同,目标领域Dt与源领域Ds可以相同,也可以不同。在这种情况下,目标领域需要一部分带标记的数据用于建立目标领域的预测函数ft(.)。根据源领域中是否含有标记样本,可以把推导迁移学习分为两个类:
(1)、当源领域中有很多标记样本时,推导迁移学习与多任务学习(multitask learning)类似。区别在于,通过从源领域迁移知识,推导迁移学习只注重提升目标领域的效果;但多任务学习注重同时提升源领域和目标领域的效果。
(2)当源领域没有标记样本时,推导迁移学习与自学习类似。
2、转导迁移学习定义:给定源领域Ds和源领域学习任务Ts、目标领域Dt和目标领域任务Tt的情况,且Ts等于Tt、Ds不等于Dt,情况下;转导迁移学习使用源领域Ds和Ts中的知识提升或优化目标领域Dt中目标预测函数ft(.)的学习效果。此外,模型训练师,目标领域Dt中必须提供一些无标记的数据。
可见,在转导迁移学习中,源任务Ts和目标任务Tt相同,但领域Ds与Dt不同。这种情况下,源领域有大量标记样本,但目标领域没有标记样本。根据Ds和Dt的不同,可以把转到学习分为两个类:(1)、源领域和目标领域特征空间不同,即Xs不等于Xt。(2)、特征空间相同,但边缘概率不同,即P(xs)不等于P(xt)。在(2)情况下,转导迁移学习与领域适应性(domain adaptation)、协方差偏移(covariate shift)问题相同。
3、无监督迁移学习定义:给定源领域Ds和源领域学习任务Ts、目标领域Dt和目标领域任务Tt的情况,且Ts不等于Tt、标签空间Yt和Ys不可观测,情况下;转导迁移学习使用源领域Ds和Ts中的知识提升或优化目标领域Dt中目标预测函数ft(.)的学习效果。
在无监督迁移学习中,目标任务与源任务不同但却相关。此时,无监督迁移学习主要解决目标领域中的无监督学习问题,类似于传统的聚类、降维和密度估计等机器学习问题。
由此可以得到迁移学习的分类,以及和其他机器学习方法之间的关系图1所示。
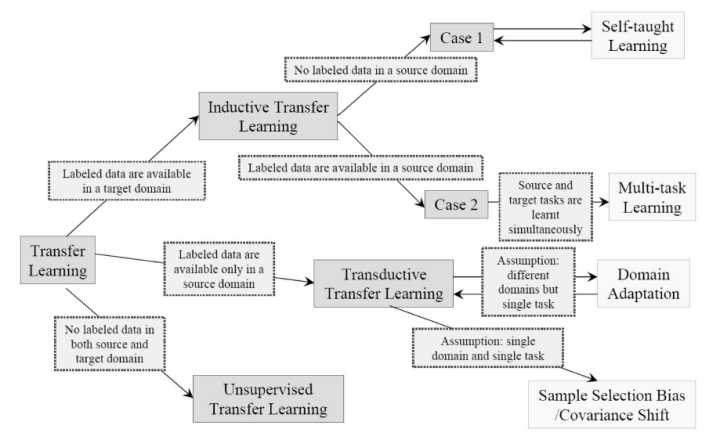
图1 基于定义的迁移学习分类
根据迁移的内容,迁移学习可以分为四类:
基于实例的迁移学习(instance-based transfer learning):源领域(source domain)中的数据(data)的某一部分可以通过reweighting的方法重用,用于target domain的学习。
基于特征表示的迁移学习(feature-representation transfer learning):通过source domain学习一个好的(good)的特征表示,把知识通过特征的形式进行编码,并从suorce domain传递到target domain,提升target domain任务效果。
基于参数的迁移学习(parameter-transfer learning):target domain和source domian的任务之间共享相同的模型参数(model parameters)或者是服从相同的先验分布(prior distribution)。
基于关系知识迁移学习(relational-knowledge transfer learning):相关领域之间的知识迁移,假设source domain和target domain中,数据(data)之间联系关系是相同的。
前三类迁移学习方式都要求数据(data)独立同分布假设。同时,四类迁移学习方式都要求选择的sourc doma与target domain相关,
表1给出了迁移内容的迁移学习分类:

表1 基于迁移内容的迁移学习分类
将基于定义迁移学习分类和基于迁移内容的迁移学习分类结合,得到迁移学习分类结果如表2所示:

表2 基于定义迁移学习分类和基于迁移内容的迁移学习分类结合
从表2可以发现,迁移学习大多数的研究工作都集中于推导迁移学习和转导迁移学习上,无监督的迁移学习模式,在未来会吸引更多研究者关注。
用于情感分类,图像分类,命名实体识别,WiFi信号定位,自动化设计,中文到英文翻译等问题。
领域自适应(Domain Adaptation)是迁移学习中的一种代表性方法,详细关系见下图。
领域自适应问题定义为:源域(source domain)和目标域(target domain)共享相同的特征和类别,但是特征分布不同,如何利用信息丰富的源域样本来提升目标域模型的性能。源域表示与测试样本不同的领域,具有丰富的监督标注信息;目标域表示测试样本所在的领域,无标签或者只有少量标签。源域和目标域往往属于同一类任务,但是分布不同。
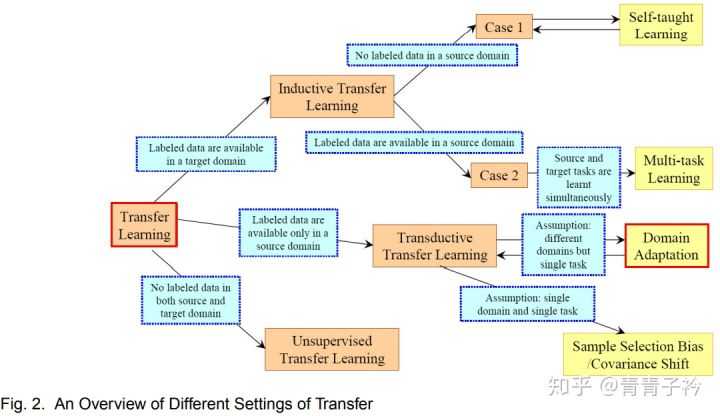 迁移
迁移
此图源自杨强大佬的文章《A Survey on Transfer Learning》。
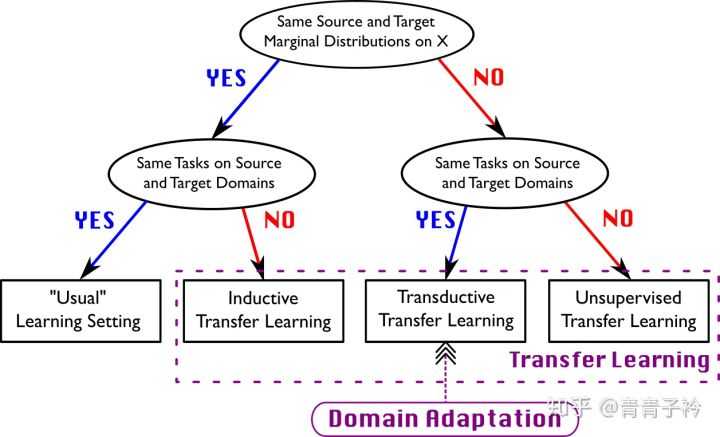
另外wiki上的Domain Adaptation词条也有类似的图片描述:
参考论文:
[1] A survey on transfer Learning. IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 22, NO. 10, OCTOBER 2010
[2] Learning to Learn. S. Thrun and L. Pratt, eds. Kluwer Academic Publishers, 1998.
[3] R. Caruana, “Multitask Learning,” Machine Learning, vol. 28, no. 1, pp. 41-75, 1997.
[4] R. Raina, A. Battle, H. Lee, B. Packer, and A.Y. Ng, “Self-Taught Learning: Transfer Learning from Unlabeled Data,” Proc. 24th Int’l Conf. Machine Learning, pp. 759-766, June 2007.
[5] H. Daume´ III and D. Marcu, “Domain Adaptation for Statistical Classifiers,” J. Artificial Intelligence Research, vol. 26, pp. 101-126, 2006.
[6] B. Zadrozny, “Learning and Evaluating Classifiers under Sample Selection Bias,” Proc. 21st Int’l Conf. Machine Learning, July 2004.
[7] H. Shimodaira, “Improving Predictive Inference under Covariate Shift by Weighting the Log-Likelihood Function,” J. Statistical Planning and Inference, vol. 90, pp. 227-244, 2000.
[8] W. Dai, Q. Yang, G. Xue, and Y. Yu, “Self-Taught Clustering,” Proc. 25th Int’l Conf. Machine Learning, pp. 200-207, July 2008.
[9] Z. Wang, Y. Song, and C. Zhang, “Transferred Dimensionality Reduction,” Proc. European Conf. Machine Learning and Knowledge Discovery in Databases (ECML/PKDD ’08), pp. 550-565, Sept. 2008.
https://www.cnblogs.com/jinjidexuetu/p/11097626.html
迁移学习及领域自适应 Transfer Learning & Domain Adaptation
标签:提升 param 特征 任务 研究 问题: mic cti ext
原文地址:https://www.cnblogs.com/jins-note/p/13052569.html