标签:alt 部分 close expand init nat inter 进一步 conv2
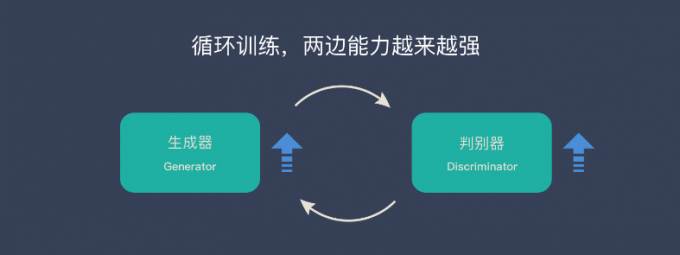
生成对抗网络(GAN)由2个重要的部分构成:
训练过程
公式中 \(p_i\) 和 \(q_i\) 为真实的样本分布和生成器的生成分布
假定 \(y_1\) 为正确样本分布,那么对应的( \(1-y_1\) )就是生成样本的分布。\(D\) 表示判别器,则 \(D(x_1)\) 表示判别样本为正确的概率, \(1-D(x_1)\) 则对应着判别为错误样本的概率。则有如下式子(这里仅仅是对当前情况下的交叉熵损失的具体化)。
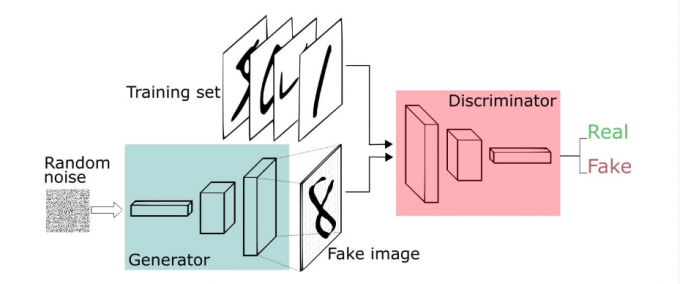
对于GAN中的样本点 \(x_i\) ,对应于两个出处,要么来自于真实样本,要么来自于生成器生成的样本 $\tilde{x} - G(z) $ ( 这里的 \(z\) 是服从于投到生成器中噪声的分布)。
对于来自于真实的样本,我们要判别为正确的分布 \(y_i\) 。来自于生成的样本我们要判别其为错误分布( \(1-y_i\) )。将上面式子进一步使用概率分布的期望形式写出(为了表达无限的样本情况,相当于无限样本求和情况),并且让 \(y_i\) 为 1/2 且使用 \(G(z)\) 表示生成样本可以得到如下公式:
对于论文中的公式
其实是与上面公式一样的,下面做解释
卷积对抗生成网络(DCGAN)是在GAN的基础上加入了CNN,主要是改进了网络结构,在训练过程中状态稳定,并且可以有效实现高质量图片的生成以及相关的生成模型应用。DCGAN的生成器网络结构如下图:
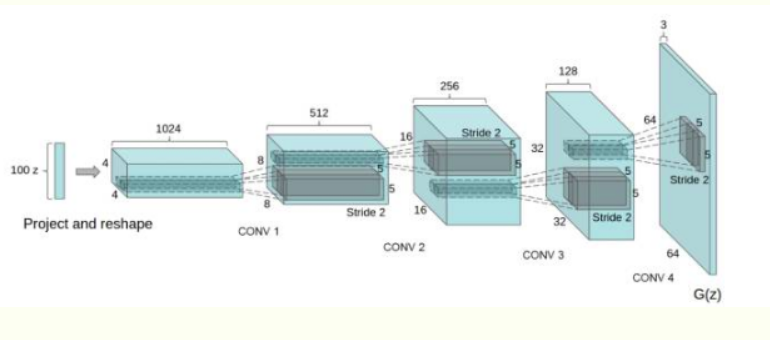
DCGAN的改进:
shenduimport numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import optimizers, losses, layers, Sequential, Model
class DCGAN():
‘‘‘
实现深度对抗神经网络
生成 MNIST 手写数字图片
输入的噪声为服从正态分布均值为 0 方差为 1 的分布, shape:(None, 100)
生成器(G)输入 噪声, 输出为 (None, 28, 28, 1)的图片
分类器(D)输入为 (None, 28, 28, 1)的图片,输出图片的分类真假
‘‘‘
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
optimizer = optimizers.Adam(0.0002)
# 构建编译分类器
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=‘binary_crossentropy‘,
optimizer=optimizer,
metrics=[‘accuracy‘])
# 构建编译生成器
self.generator = self.build_generator()
self.generator.compile(loss=‘binary_crossentropy‘, optimizer=optimizer)
# 生成器输入为噪音,生成图片
z = layers.Input(shape=(100,))
img = self.generator(z)
# 对于整个对抗网络模型只优化生成器的参数
self.discriminator.trainable = False
# 用生成的图片输入分类器判断
valid = self.discriminator(img)
# 对于整个对抗网络 输入噪音 => 生成图片 => 决定图片是否有效
self.combined = Model(z, valid)
self.combined.compile(loss=‘binary_crossentropy‘, optimizer=optimizer)
def build_generator(self):
‘‘‘
构建生成器
‘‘‘
noise_shape = (100,)
model = tf.keras.Sequential()
# 添加全连接层
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=noise_shape))
# 添加 BatchNormalization 层,对数据进行归一化
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
# 添加逆卷积层,卷积核大小为 5X5,数量 128, 步长为 1
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding=‘same‘, use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# 添加逆卷积层,卷积核大小为 5X5,数量 64, 步长为 2
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding=‘same‘, use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# 添加逆卷积层,卷积核大小为 5X5,数量 1, 步长为 2
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding=‘same‘, use_bias=False, activation=‘tanh‘))
assert model.output_shape == (None, 28, 28, 1)
model.summary()
noise = layers.Input(shape=noise_shape)
img = model(noise)
# 返回 Model 对象,输入为 噪声, 输出为 图像
return keras.Model(noise, img)
def build_discriminator(self):
‘‘‘
构建分类器
‘‘‘
img_shape = (self.img_rows, self.img_cols, self.channels)
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding=‘same‘,
input_shape=img_shape))
model.add(layers.LeakyReLU())
# 添加 Dropout 层,减少参数数量
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding=‘same‘))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
# 把数据铺平
model.add(layers.Flatten())
model.add(layers.Dense(1))
model.summary()
img = layers.Input(shape=img_shape)
validity = model(img)
return keras.Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
‘‘‘
网络训练
‘‘‘
# 加载 数据集
(X_train, _), (_, _) = keras.datasets.mnist.load_data()
# 把数据缩放到 [-1, 1]
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
# 添加通道维度
X_train = np.expand_dims(X_train, axis=3)
half_batch = int(batch_size / 2)
for epoch in range(epochs):
# ---------------------
# 训练分类器
# ---------------------
# 随机的选择一半的 batch 数量图片
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (half_batch, 100))
# 生成一半 batch 数量的 图片
gen_imgs = self.generator.predict(noise)
# 分类器损失
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# 训练生成器
# ---------------------
noise = np.random.normal(0, 1, (batch_size, 100))
# The generator wants the discriminator to label the generated samples
# as valid (ones)
# 对于生成器,希望分类器把更多的图片判为 有效 (用 1 表示)
valid_y = np.array([1] * batch_size)
# 训练生成器
g_loss = self.combined.train_on_batch(noise, valid_y)
# 打印训练进度
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# 每个 save_interval 周期保存一张图片
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, 100))
gen_imgs = self.generator.predict(noise)
# 把图片数据缩放到 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap=‘gray‘)
axs[i,j].axis(‘off‘)
cnt += 1
fig.savefig("dcgan/images/mnist_%d.png" % epoch)
plt.close()
if __name__ == ‘__main__‘:
dcgan = DCGAN()
dcgan.train(epochs=10000, batch_size=32, save_interval=200)
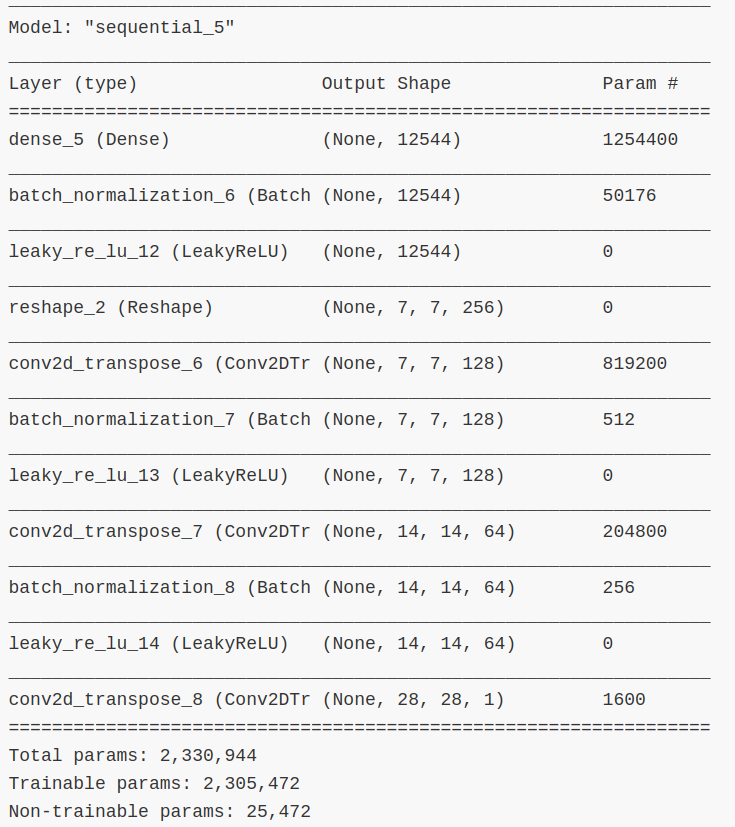
网络参数信息

下面是循环了 10000 次 epoch 后,从开始每隔 2000 个 epoch 生成器生成的图片
可以看到,刚开始全部都是噪声,随着训练的进行,图片逐渐清晰
生成的图片还是不太清晰,一方面的原因是我训练的 epoch 周期太少,因为自己电脑性能问题,太耗时间,所以训练的epoch 周期少,如果有条件后提高训练周期应该会好很多。另一方面或许因为我构建的网络还有不合理之,后期还需要改进。






标签:alt 部分 close expand init nat inter 进一步 conv2
原文地址:https://www.cnblogs.com/jsfantasy/p/13055267.html