标签:class 输出 debug index search 微服务 指标 chm 无法
前面几章蜻蜓点水的介绍了elasticsearch、apm相关的内容。本片主要介绍怎么使用ELK Stack帮助我们打造一个支撑起日产TB级的日志监控系统
在企业级的微服务环境中,跑着成百上千个服务都算是比较小的规模了。在生产环境上,日志扮演着很重要的角色,排查异常需要日志,性能优化需要日志,业务排查需要业务等等。然而在生产上跑着成百上千个服务,每个服务都只会简单的本地化存储,当需要日志协助排查问题时,很难找到日志所在的节点。也很难挖掘业务日志的数据价值。那么将日志统一输出到一个地方集中管理,然后将日志处理化,把结果输出成运维、研发可用的数据是解决日志管理、协助运维的可行方案,也是企业迫切解决日志的需求。
通过上面的需求我们推出了日志监控系统。



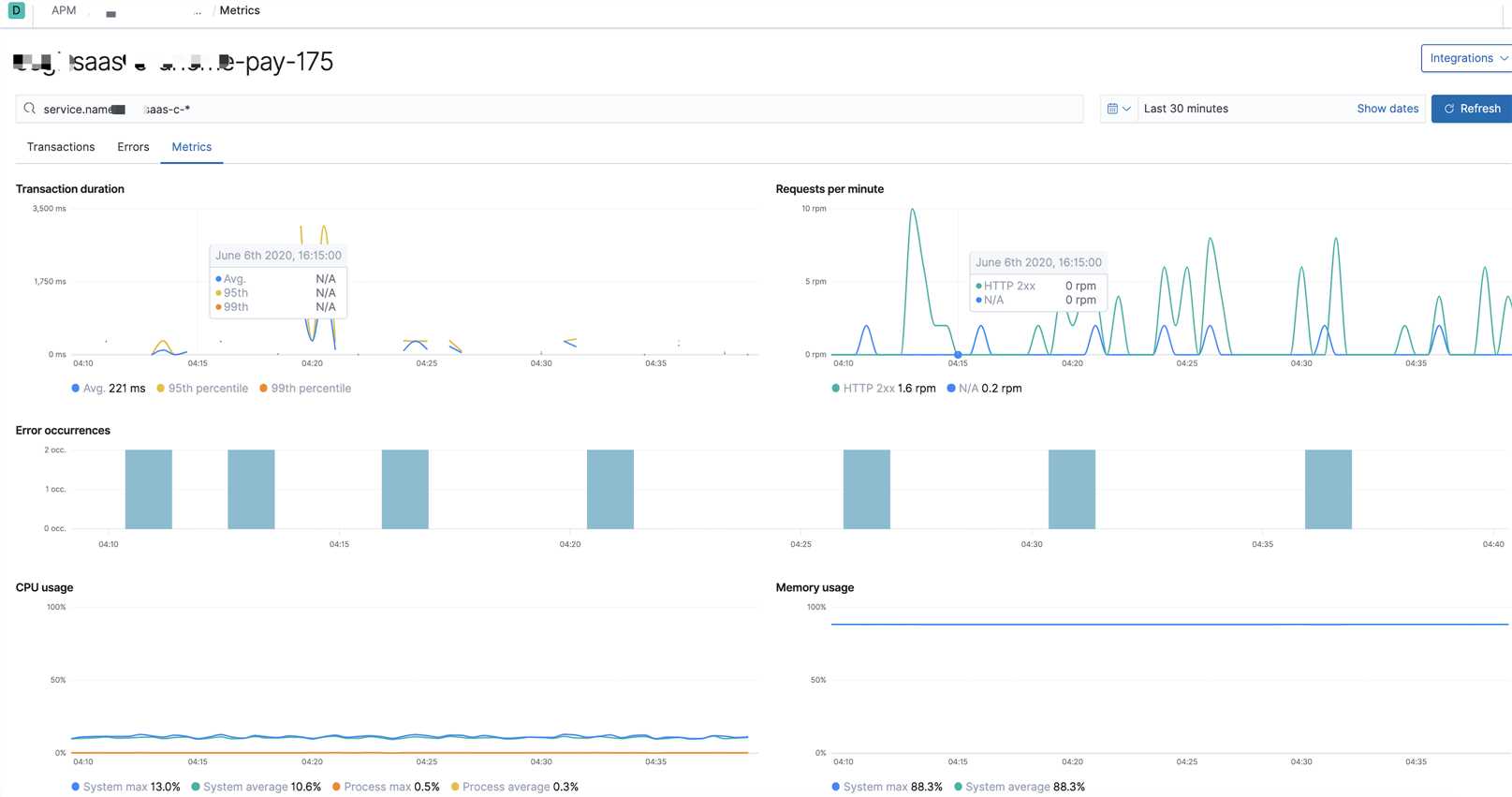
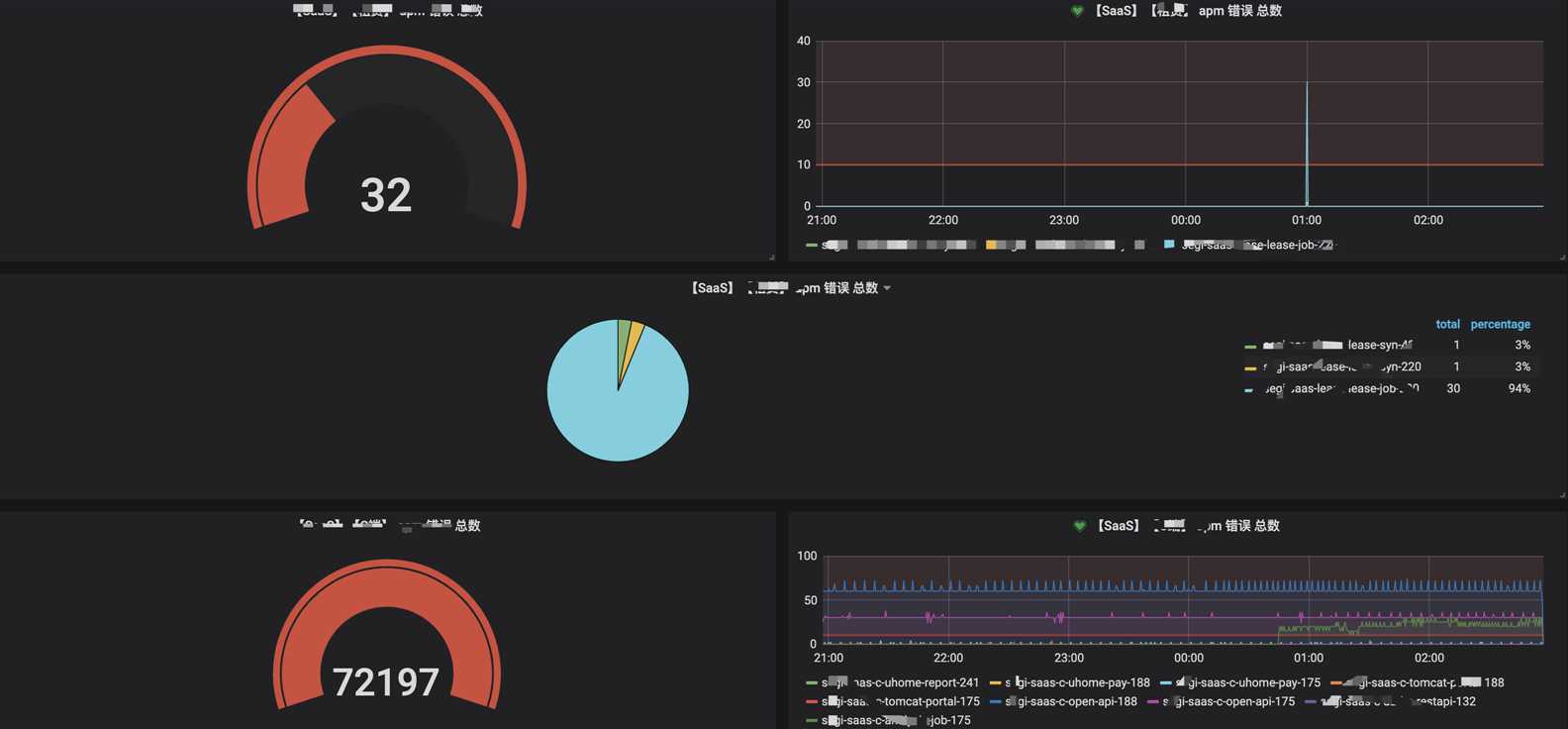
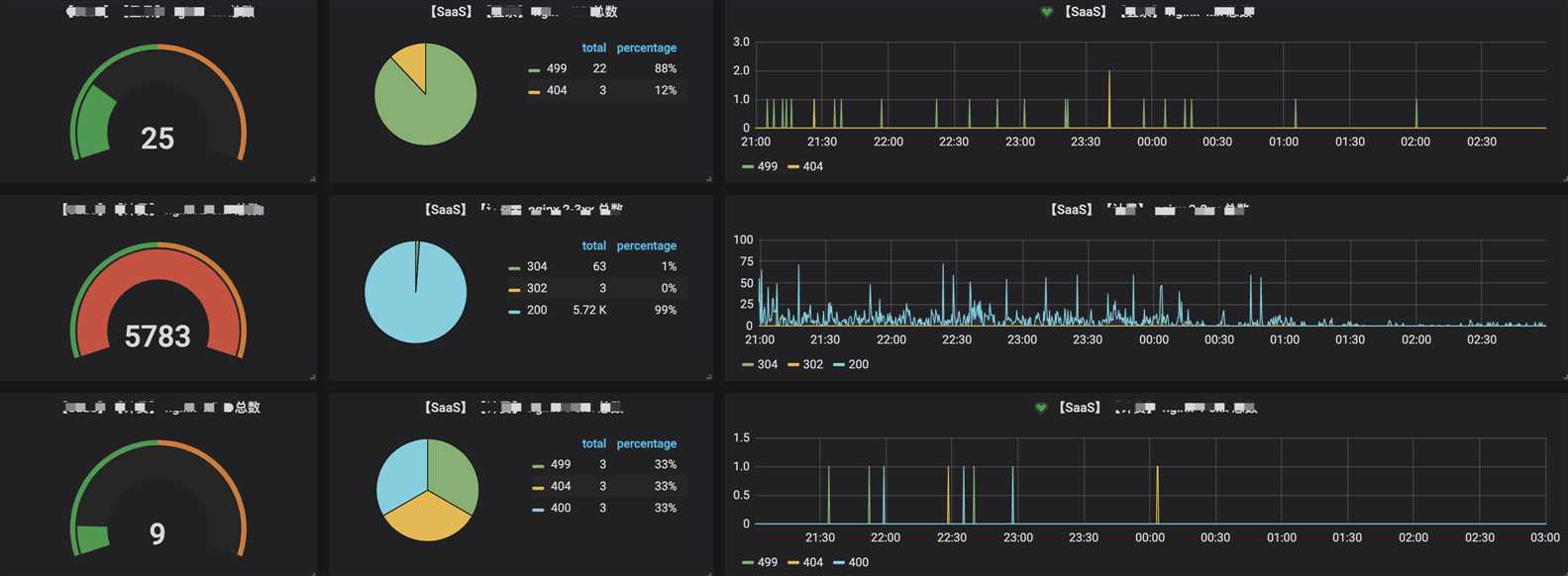
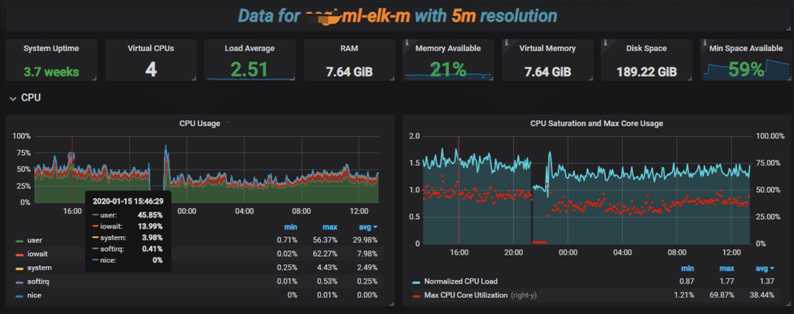
7. 可视化界面我们主要使用grafana,它支持的众多数据源中,其中就有普罗米修斯和elasticsearch,与普罗米修斯可谓是无缝对接。而kibana我们主要用于apm的可视分析
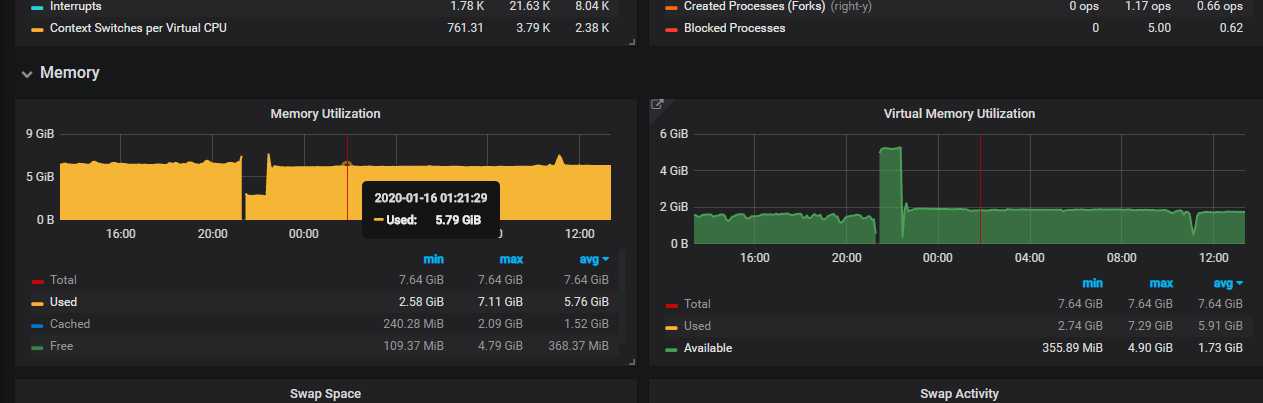
出于安全考虑,公司线上可视化数据不便于使用,以下只是简单的上几张开发环境的效果图
权限认证


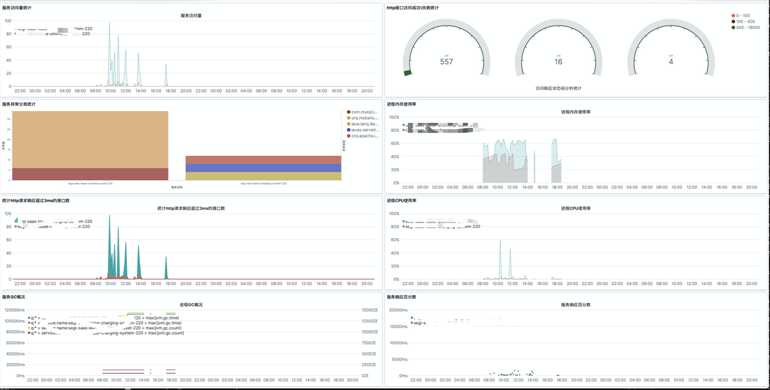
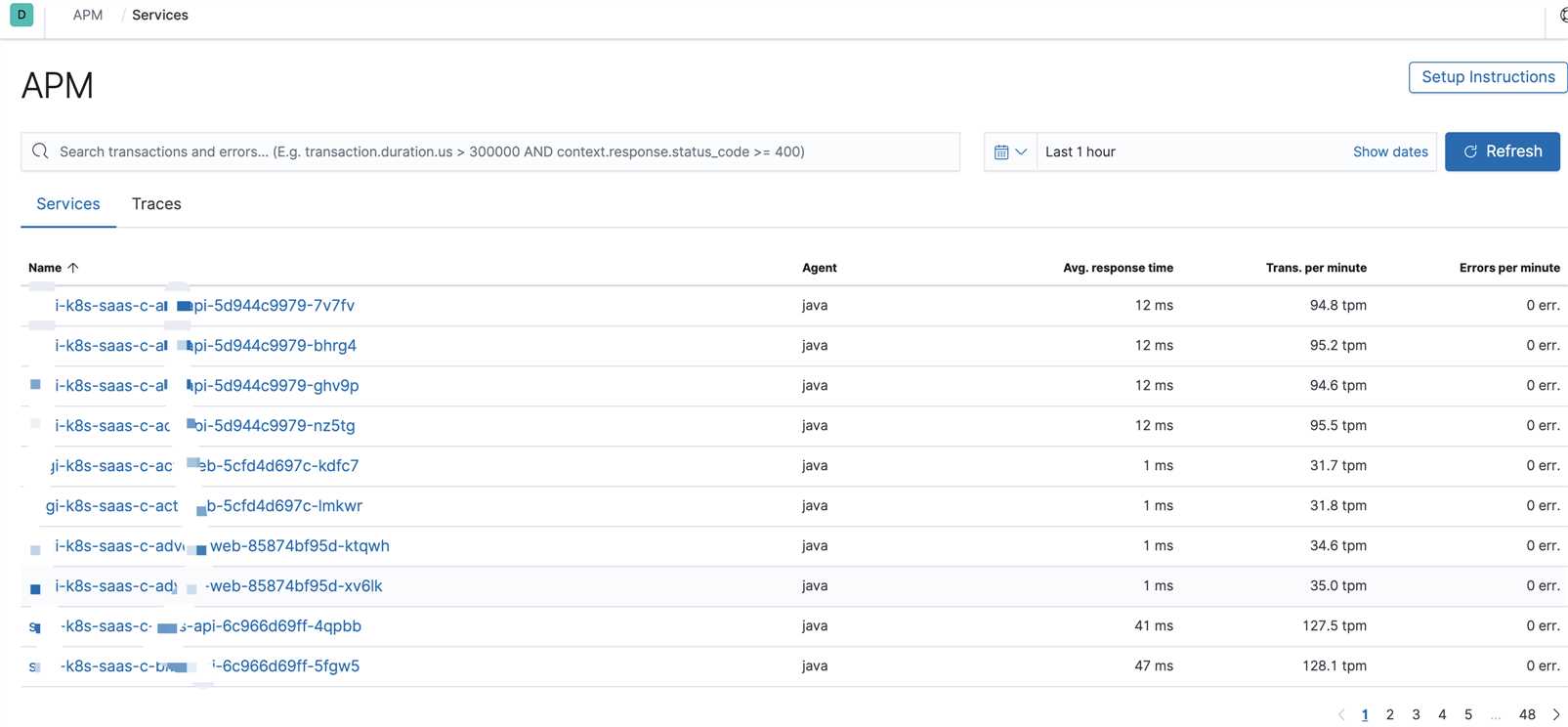
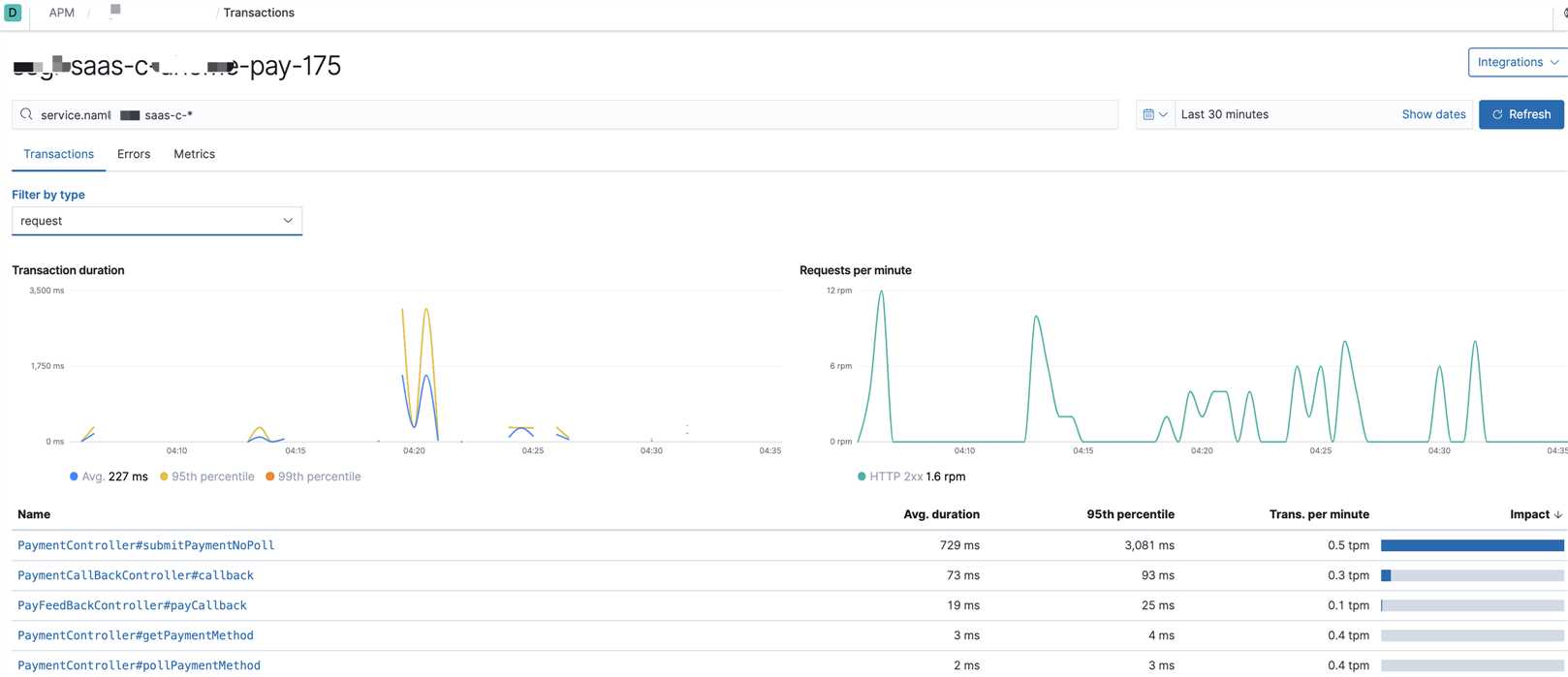
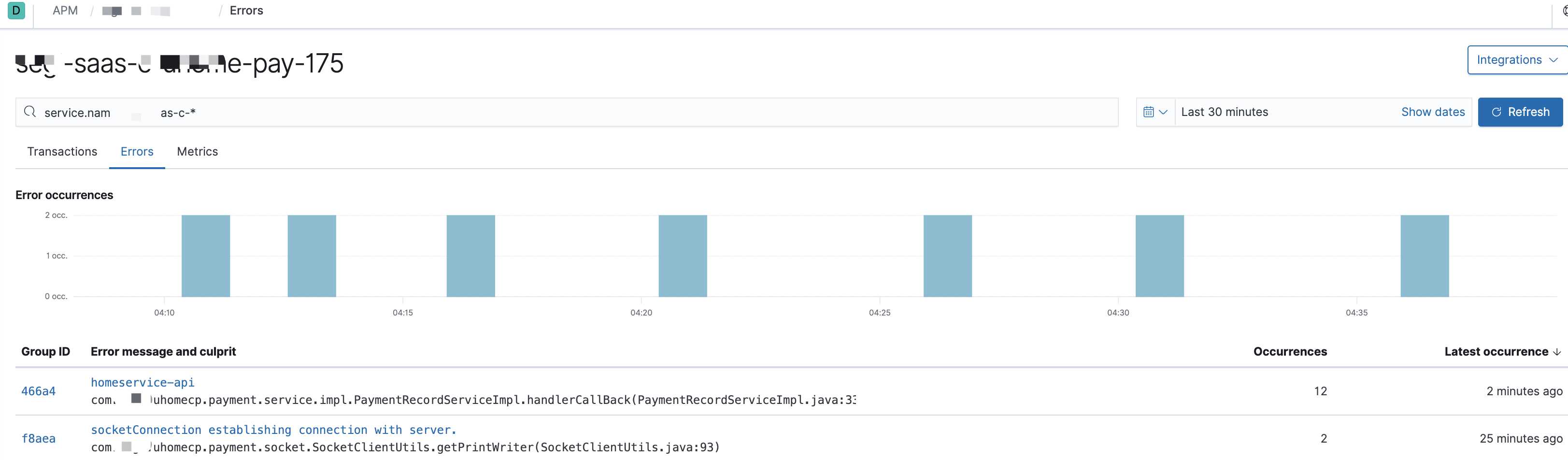
分析可视化
声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文链接,否则保留追究法律责任的权利
标签:class 输出 debug index search 微服务 指标 chm 无法
原文地址:https://www.cnblogs.com/dengbangpang/p/12961593.html