标签:lap info 设计 求和 感知 数据治理 转换 流式 tor
在人口流量红利不再,获客成本越来越高的时代,精益创业、MVP 的概念已经深入人心,精细化运营也是大势所趋,而这些背后本质上都依赖数据化运营,那如何根据现有业务,快速从 0 开始打造一个契合业务的数据产品呢?本文将以某二手交易平台业务为基础,讲述整个数据平台从 0 到 1 的演进与实践,希望对大家能有所启发。1、背景
在某二手交易平台开始大数据平台建设之前,整个数据从需求提出到研发流程再到数据报表、数据产品,也是经历过一段非常混沌的时期,而且效率和质量往往很难得到保障,主要表现为以下几个方面:
(1)可用性差
比如经常出现计算延迟、异常,数据指标也常常数据对不上,很多相似的指标不清楚具体差异在哪,即使同一个指标也可能不同的同学开发的而对不上。另外数据波动无感知,比如日志格式出错,结果第二天才发现有问题。
(2)维护成本高
成百上千的日志模块,不知从何维护,出了问题也不知道从哪里可以追溯到源头和负责人。
(3)业务快速迭代,精细化、数据化运营需求和研发资源之间的矛盾
2、目标与方案
(1)目标
数据可管理、可维护、可扩展、高可用
及时、准确、直观的呈现业务数据与问题
降低使用门槛,提升使用效率
(2)方案
数据仓库化
数据平台化
3、数据仓库建设
结构化
层次化
主题化
模型化:用户模型/事件模型
ETL
ETL 是整个数据仓库的核心,正如业界流传的一句话:Garbage In, Garbage Out. 脏活累活都是在这一层完成,以便为上层业务提供口径、格式、逻辑统一的数据层,提升数据质量和稳定性,如果这一层没做好,上层的统计分析与数据挖掘无异于空中楼阁。ETL常见的工作如下:
无效数据
脏数据转换
数据模型/业务逻辑预处理
高可用:依赖、重试、告警、优先级
4、数据平台化与产品化
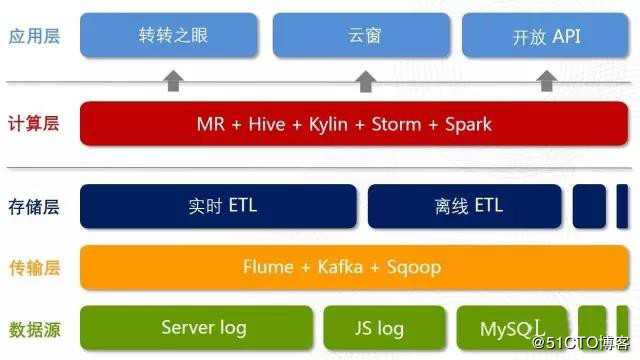
从数据体系和平台的层次来划分可以分为标准的五层结构:采集层、传输层、存储层、计算层、应用层
随着业务的不断迭代,业务逐渐复杂、数据量也急剧膨胀后,每一层都会遭遇挑战,比如采集层,如何在高并发的情况下,保证日志能稳定落地到磁盘而不重不丢不延时?是采用开源的 Nginx+Lua 方案还是自研组件造轮子?数防止数据的无限膨胀,据仓库元数据怎么管理?如何减小维护成本?计算层的任务调度如何解决依赖关系,又如何做到分布式调度高可用?以上这些问题,早期我们大部分都采用开源的解决方案,但在后续的易用性、扩展性和维护性都遭遇了不少问题,总体成本一点都不低,因此最后我们大部分还是采用自研的解决方案(这块话题比较广,细节比较多,本文暂时不展开详述,有机会后续将会单独展开分享)。又如计算层的 OLAP 引擎我们该如何选取?比如 MR 适合大规模数据集的批处理,Hive 适合灵活的探索式即席查询,Kylin 适合多维实时统计分析,Storm 适合实时流式计算,Spark 适合内存迭代型计算,到底该选谁?可以看到的是没有所谓的银弹和通用解决方案,需要结合自身的业务场景和需求来技术选型和架构。
整体技术栈与架构如下:
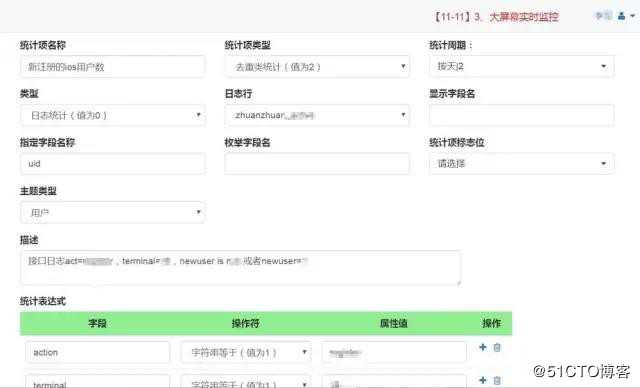
数据产品化方面主要是对数据需求与报表的抽象,最终形成通用的自动化报表工具,比如:
业务需求抽象分类:求和、求平均、TOP K、最大最小、去重、过滤
多样性的解决方案:离线、实时、单维、多维
基于这些抽象,我们比较容易实现基于报表、统计项和日志、日志行之间的逻辑映射关系,形成通用的自助化配置报表,极大释放开发资源。
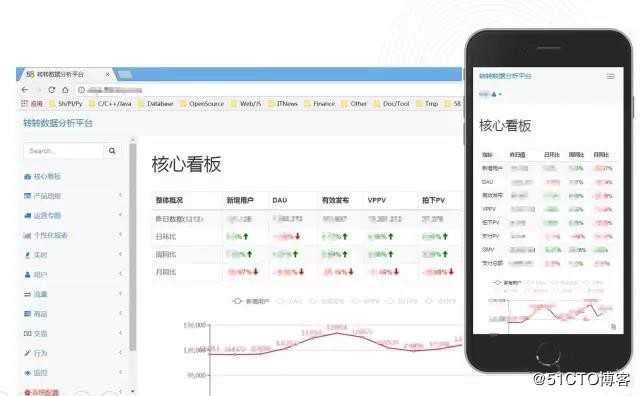
另外产品、运营、BOSS可能随时需要关注业务运营状态、利用数据做各种分析和业务决策,我们需要考虑到平台的移动化与跨终端,这里我们在技术选型时就考虑到了这一点,利用比较流行的响应式布局框架可以近乎 0 代价实现跨平台,而不用单独去开发 iOS 或 android 客户端。
5、数据指标体系化、分析框架与方法论
数据指标和维度成千上万,如何基于业务去展开分析,又如何去量化运营效果,评估业务,其实是需要建立一套科学的分析框架和指标体系的,否则只会迷失在数据的海洋里,或者盲人摸象得出错误的结论,以某二手交易平台的业务体系为例,咱们可以看下某二手交易平台的数据指标体系:
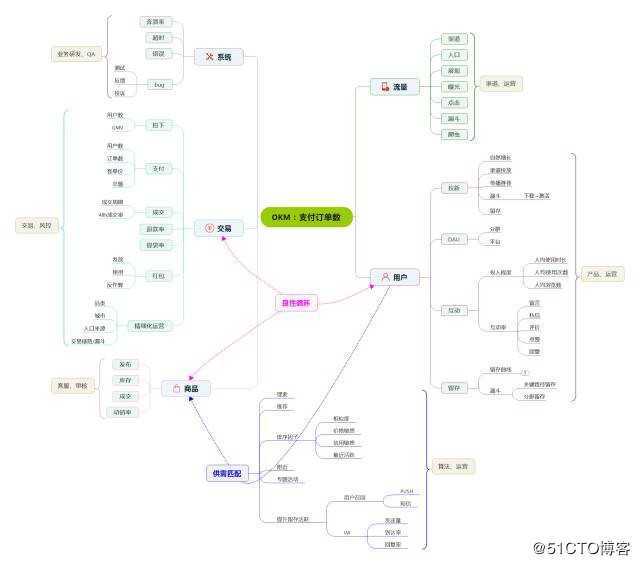
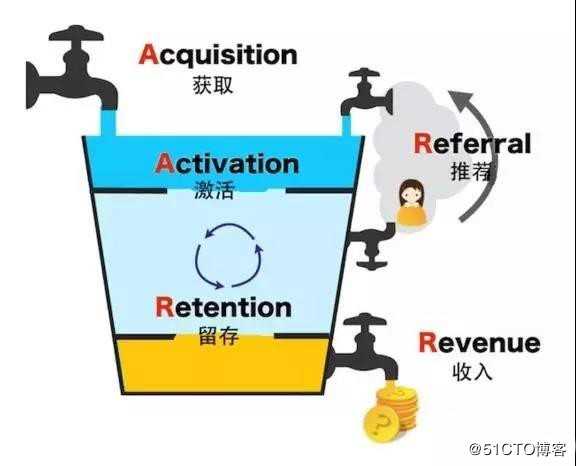
另外基于此我们设计了一些常用的数据模型与分析框架,供业务方快速的分析决策,评估效果,比如留存、漏斗模型,精益创业里的 AARRR 分析框架,基于用户事件模型,我们还实现了自助化的漏斗、留存分析工具,供业务方自助化的配置任意想关注的路径漏斗或行为留存。
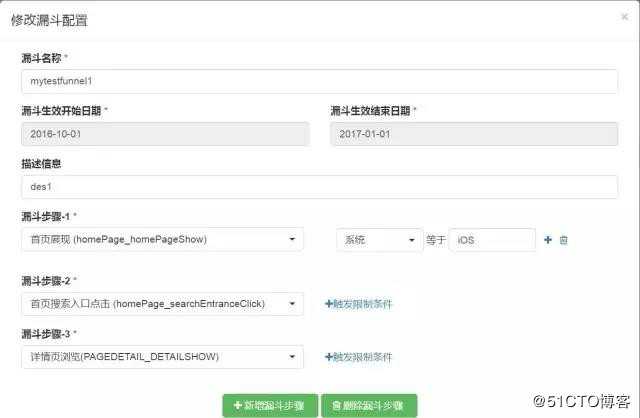
6、整个数据平台及其体系化的重难点
漏斗透传机制:这个属于日志埋点问题,如果不解决,一些通用的数据模型如漏斗分析就无法进行,因此我们设计了一套 Session 级别的透传机制,确保用户每个页面或动作的访问能够被串联分析,追溯来源入口,精细化分析改善现有产品和有针对性的运营。
数据治理:数据质量的体系化建设,数据仓库、实时监控是两个不错的解决方案。
业务级别的元数据管理:将元数据细化到业务层次,降低业务方的使用门槛,提升决策效率。
数据生命周期管理:哪些是热数据哪些是冷数据,核心和非核心,长期和短期,防止数据的无限膨胀,带来繁重的存储、维护成本和计算资源的浪费。
大数据场景下的实时多维分析:比如大数据场景下的实时去重计算,我们会依据不同的场景,选取不同的方案,如bitmap、分布式缓存、基数估计等等,在计算代价和时效性、准确性三方面去做 tradeoff。
7、总结:如何根据现有业务,快速从 0 开始打造一个契合业务的数据产品?
走进业务
抽象业务诉求
换位思考,走在需求的前面
站在巨人的肩膀上
万变不离其宗的方法论
更多免费技术资料及视频
标签:lap info 设计 求和 感知 数据治理 转换 流式 tor
原文地址:https://blog.51cto.com/jssforever/2501969