标签:描述 etl nod 节点 code ati 官网 bin 文件
简介Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
优势
1)Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理
2)Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理
3)Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
4)Hadoop 还是可伸缩的,能够处理 PB 级数据
5)Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用
6)Hadoop是一个能够让用户轻松架构和使用的分布式计算平台,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序
它主要有以下几个优点:
1.高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖
2.高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中
3.高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快
4.高容错性:Hadoop能够自动保存数据的多个副本,也能够自动将失败的任务重新分配
5.低成本:hadoop是开源的,项目的软件成本因此会大大降低
6:Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的,Hadoop 上的应用程序也可以使用其他语言编写,如 C++
Hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里
准备三台Centos7虚拟机作为Hadoop集群的结点,配置IP地址和Hostname,关闭防火墙和selinux,同步时间,配置IP地址和hostname的映射
| hostname | ip |
|---|---|
| 192.168.29.143 | node1 |
| 192.168.29.142 | node2 |
| 192.168.29.144 | node3 |
配置ssh免密登录
[root@node1 ~]#ssh-keygen
[root@node2 ~]#ssh-keygen
[root@node3 ~]#ssh-keygen
[root@node1 ~]#ssh-copy-id root@192.168.29.142
[root@node1 ~]#ssh-copy-id root@192.168.29.143
[root@node1 ~]#ssh-copy-id root@192.168.29.144
[root@node2 ~]#ssh-copy-id root@192.168.29.142
[root@node2 ~]#ssh-copy-id root@192.168.29.143
[root@node2 ~]#ssh-copy-id root@192.168.29.144
[root@node3 ~]#ssh-copy-id root@192.168.29.143
[root@node3 ~]#ssh-copy-id root@192.168.29.144
[root@node3 ~]#ssh-copy-id root@192.168.29.142
#验证免密登录
[root@node1 ~]#ssh root@ip
[root@node2 ~]#ssh root@ip
[root@node3 ~]#ssh root@ip安装Java环境
从官网下载jdk压缩包并解压
三个结点均要安装java环境
#添加环境变量
[root@node1 ~]# vi /etc/profile
JAVA_HOME=/usr/local/java
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASS_PATH
#重新读取环境变量
[root@node1 ~]# source /etc/profile
#查看java环境配置情况
[root@node1 ~]# java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)从Hadoop官网下载Hadoop二进制压缩包并解压
#解压
[root@node1 ~]# tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local/hadoop
#添加环境变量方便启动Hadoop集群
[root@node1 ~]# vi /etc/profile
PATH=$PATH:/usr/local/hadoop/bin:$JAVA_HOME/bin:/usr/local/hadoop/sbin
export PATH JAVA_HOME CLASS_PATH
#重新加载环境变量
[root@node1 ~]# source /etc/profilenode1配置Hadoop
配置hadoop-env.sh
#添加JAVA环境变量
[root@node1 ~]# vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/java配置yarn-env.sh
#添加JAVA环境变量
[root@node1 ~]# vi /usr/local/hadoop/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/local/java配置core-site.xml
[root@node1 ~]# vi /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.29.143:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
#需要提前创建文件夹
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>配置hdfs-site.xml
[root@node1 ~]# vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.29.143:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
#设置秘书结点
<value>192.168.29.142:50090</value>
</property>
</configuration>配置mapred-site.xml
[root@node1 ~]# vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1500</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3000</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1200m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2600m</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置yarn-site.xml
[root@node1 ~]# vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.29.143</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>22528</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1500</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
</configuration>配置workers
注:hadoop-2.x为slaves
[root@node1 ~]# vi /usr/local/hadoop/etc/hadoop/workers
192.168.29.143
192.168.29.142
192.168.29.144把配置好的Hadoop直接传到node2和node3上
[root@node1 ~]# scp -r /usr/local/hadoop root@192.168.29.142:/usr/local/hadoop
[root@node1 ~]# scp -r /usr/local/hadoop root@192.168.29.144:/usr/local/hadoop#在node1结点启动集群
[root@node1 ~]# start-all.sh
#查看集群启动状态
#node1结点
[root@node1 ~]# jps
3154 ResourceManager
3651 Jps
2586 NameNode
3293 NodeManager
2718 DataNode
#node2结点
[root@node2 ~]# jps
2203 NodeManager
2315 Jps
2013 DataNode
2109 SecondaryNameNode
#node3结点
[root@node3 ~]# jps
2126 NodeManager
2015 DataNode
2239 Jps
#结点分布情况和配置文件一致,集群部署成功
#关闭集群
[root@node1 ~]# stop-all.sh访问node1:8088查看集群状态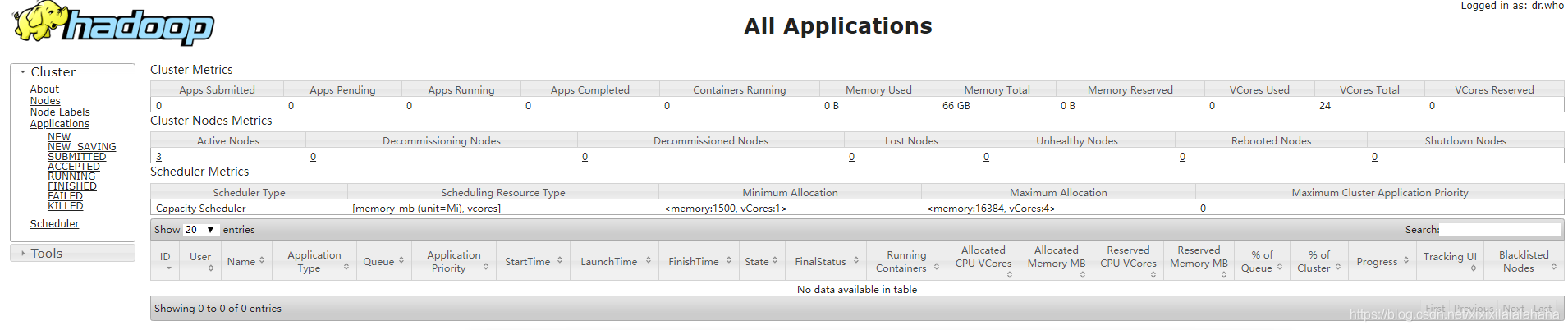
访问node1:50070可查看集群的概况和hdfs的存储内容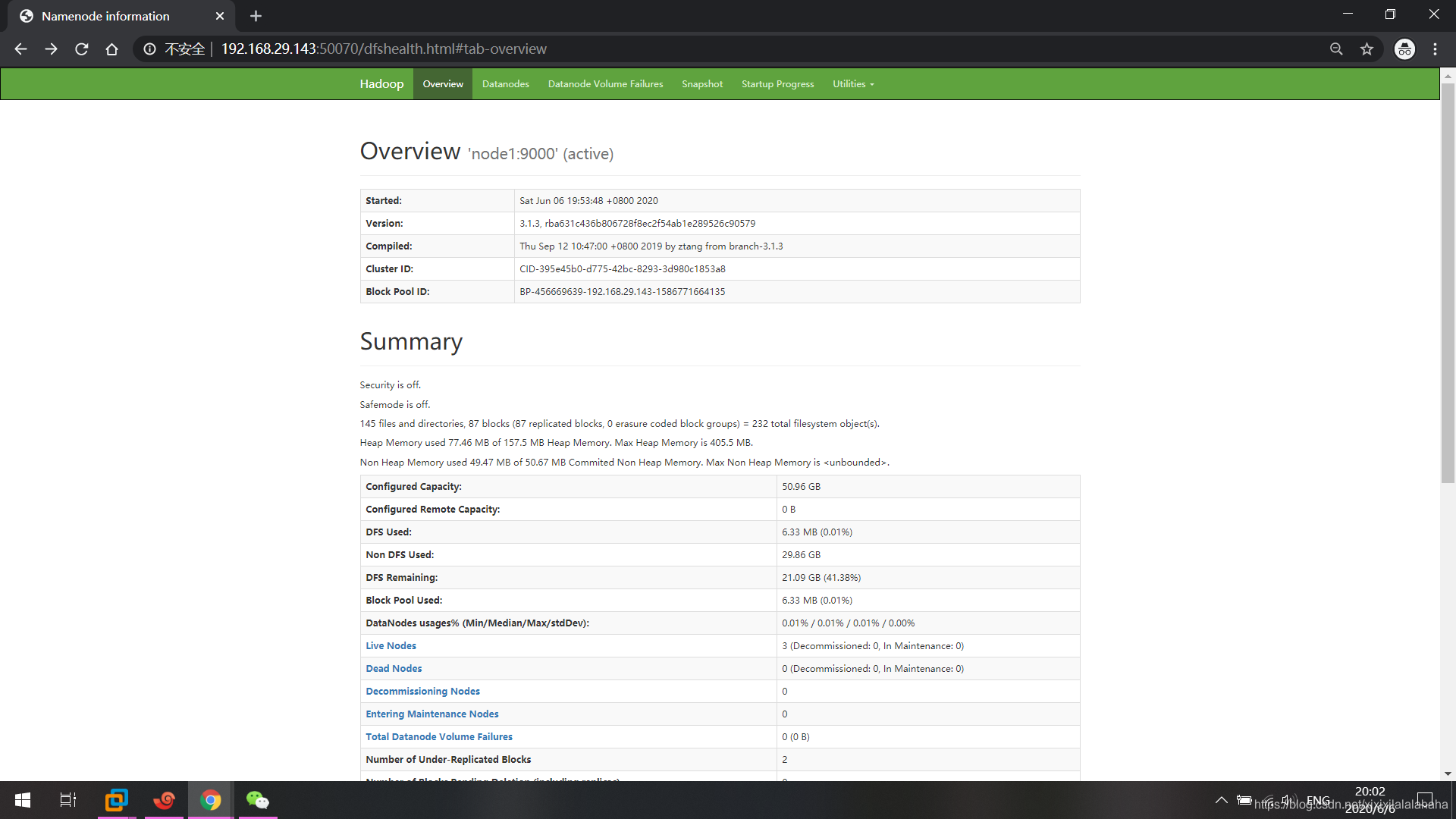
点击Browse the file system可查看文件系统存储内容,也可上传文件到文件系统以及从文件系统下载文件
Hadoop官方提供了计算π值的测试模板
#执行hadoop程序
[root@node1 ~]# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 20 50
#通过命令行查看运行程序结果
Job Finished in 172.314 seconds
2020-06-06 20:13:54,426 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Estimated value of Pi is 3.14800000000000000000
web页面查看执行过程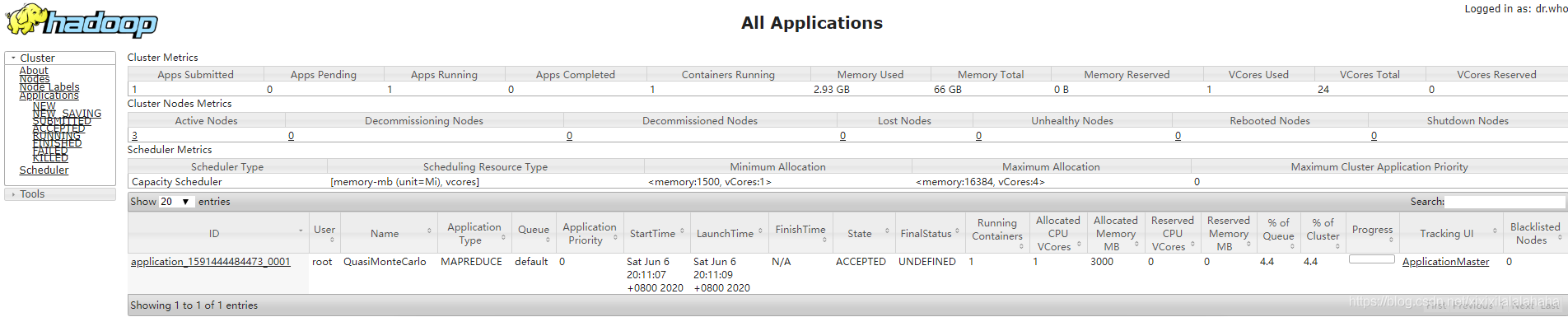
web页面查看执行结果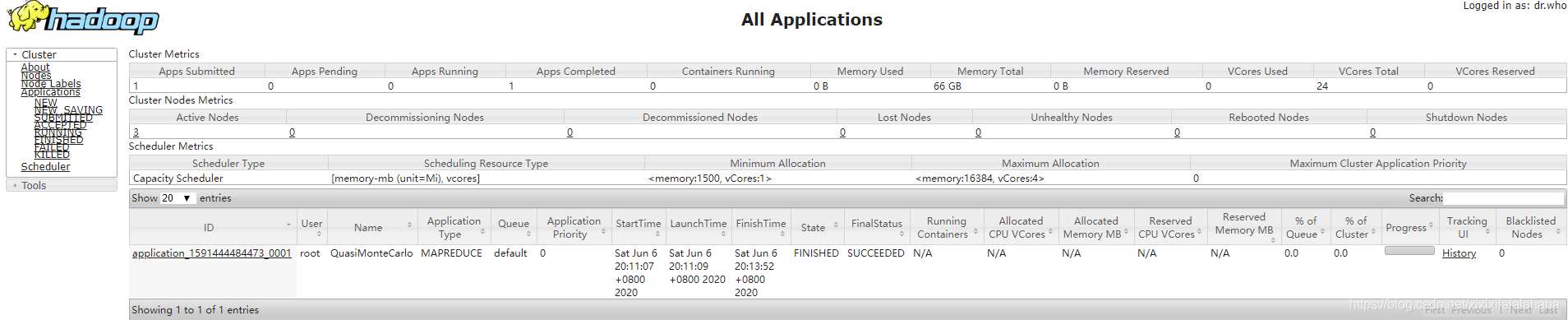
自此Hadoop集群环境部署成功
标签:描述 etl nod 节点 code ati 官网 bin 文件
原文地址:https://blog.51cto.com/14832653/2502003