标签:机器 跨语言 context 固定 sof end 搜索 gen ado
tracing

Wikipedia 中,对 Tracing 的定义 是,在软件工程中,Tracing 指使用特定的日志记录程序的执行信息,与之相近的还有两个概念,它们分别是 Logging 和 Metrics。
同时这三种定义相交的情况也比较常见。
针对每种分析需求,我们都有非常强大的集中式分析工具。
早在 2005 年,Google 就在内部部署了一套分布式追踪系统 Dapper,并发表了一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,阐述了该分布式追踪系统的设计和实现,可以视为分布式追踪领域的鼻祖。随后出现了受此启发的开源实现,如 Zipkin、SourceGraph 开源的 Appdash、Red Hat 的 Hawkular APM(Application Performance Management)、Uber 开源的 Jaeger 等。但各家的分布式追踪方案是互不兼容的,这才诞生了 OpenTracing。OpenTracing 是一个 Library,定义了一套通用的数据上报接口,要求各个分布式追踪系统都来实现这套接口。这样一来,应用程序只需要对接 OpenTracing,而无需关心后端采用的到底什么分布式追踪系统,因此开发者可以无缝切换分布式追踪系统,也使得在通用代码库增加对分布式追踪的支持成为可能。
OpenTracing 于 2016 年 10 月加入 CNCF 基金会
它是一个中立的(厂商无关、平台无关)分布式追踪的 API 规范,提供统一接口,可方便开发者在自己的服务中集成一种或多种分布式追踪的实现
主流的分布式追踪实现基本都已经支持 OpenTracing,包括 Jaeger、Zipkin、Appdash 等,具体可参考官方文档 《Supported Tracer Implementations》。
这部分在 OpenTracing 的规范中写的非常清楚,下面只大概翻译一下其中的关键部分,细节可参考原始文档 《The OpenTracing Semantic Specification》。
Causal relationships between Spans in a single Trace
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)
Trace 是调用链,每个调用链由多个 Span 组成。Span 的单词含义是范围,可以理解为某个处理阶段。Span 和 Span 的关系称为 Reference。上图中,总共有标号为 A-H 的 8 个阶段。
Temporal relationships between Spans in a single Trace
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]
上图是按照时间顺序呈现的调用链。
每个阶段(Span)包含如下状态:
阶段(Span)可以有 ChildOf 和 FollowsFrom 两种引用关系。ChildOf 用于表示父子关系,即在某个阶段中发生了另一个阶段,是最常见的阶段关系,典型的场景如调用 RPC 接口、执行 SQL、写数据。FollowsFrom 表示跟随关系,意为在某个阶段之后发生了另一个阶段,用来描述顺序执行关系。
如果对原理比较感兴趣,建议读一下 OpenTracing 的规范文档和 Go 语言的实现。
Twitter公司开源的一个分布式追踪工具,被Spring Cloud Sleuth集成,使用广泛而稳定
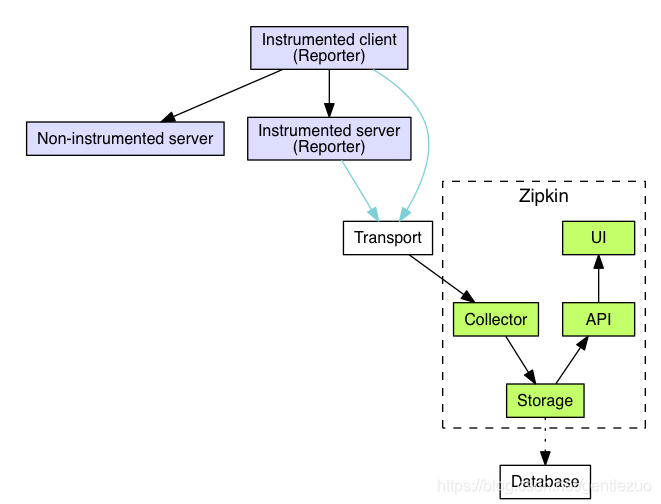
zipkin分为zipkin服务端和客户端,每一个被监控的服务都是客户端。
组件:
中国人吴晟(华为)开源的一款分布式追踪,分析,告警的工具,现在是Apache旗下开源项目
https://github.com/apache/skywalking
:大众点评开源的一款分布式链路追踪工具。

从 Jaeger 的前端界面上可以清晰的看到某个请求的所有阶段和内部调用,以及每个阶段所耗费的时间。展开某个阶段,还能看到这个阶段是在哪台机器(或容器)上执行的,也可以针对请求阶段增加的自定义标记,例如标记错误原因
Uber Jaeger 是 Uber 工程团队开源的分布式追踪系统。自 2016年 起,Jaeger 在 Uber 内部实现大范围应用。Uber 同时开发了一种适用于 RPC 的网络多路复用和框架协议 —— TChannel | Support: Node.js,Python,Go,Java,该协议融入了分布式追踪能力。
TChannel 协议规范在二进制格式中直接定义了追踪字段:“ spanid:8 parentid:8 traceid:8 traceflags:1 ”。
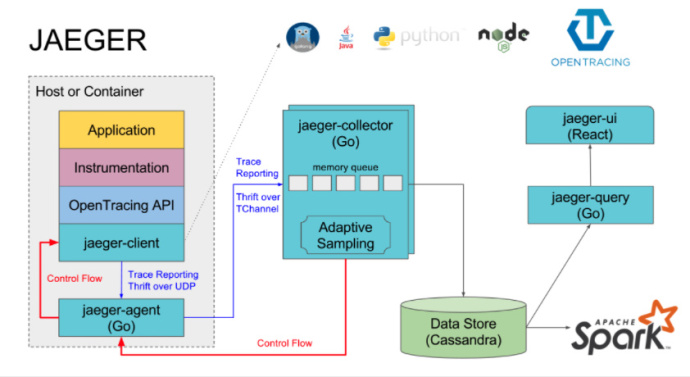
分布式追踪系统大体分为三个部分,数据采集、数据持久化、数据展示。
数据采集是指在代码中埋点,设置请求中要上报的阶段,以及设置当前记录的阶段隶属于哪个上级阶段。
数据持久化则是指将上报的数据落盘存储,例如 Jaeger 就支持多种存储后端,可选用 Cassandra 或者 Elasticsearch。
数据展示则是前端根据 Trace ID 查询与之关联的请求阶段,并在界面上呈现。
Q: 做的异步处理,如何表达?比如一个request提前返回,但是后台还在做别的处理
除了通过修改应用程序代码增加分布式追踪之外,还有一种不需要修改代码的非入侵的方式,那就是 Service Mesh。
Service Mesh 一般会被翻译成服务啮合层,它是在网络层面做文章,通过 Sidecar 的方式为 Pod 增加一层代理,通过这层网络代理来实现一些服务治理的功能,因为是工作在网络层面,可以做到跨语言、非入侵。
Istio 则是目前最成熟的 Service Mash 工具,支持启用分布式追踪服务。
Istio 会修改微服务之间发送的网络请求,在请求中注入 Trace 和 Span 标记,再将采集到的数据发送到支持 OpenTracing 的分布式追踪服务中,从而拿到请求在微服务中的调用链。当然这种方式也有缺点,它无法追踪某个微服务内部的调用过程,并且目前阶段 Istio 只能追踪 HTTP 请求,能够覆盖的范围比较有限。如果想追踪更详细的数据,还是需要在中间件和代码中埋点,不过好在埋点的过程并不复杂,不会成为一个额外的负担。
https://aras-p.info/blog/2017/01/23/Chrome-Tracing-as-Profiler-Frontend/
基于跨度的跟踪表示形式缺少对范围及其关系的含义的精确定义,并且表示形式与同步RPC编程模型紧密耦合
基于事件的跟踪模型起源于Leslie Lamport关于分布式计算机系统中事件排序的著作之一。我也承认,这里提出的大多数想法都是Facebook在2017 年的一份研究论文中发表的。(对于那些喜欢看书的人,我推荐这张聚会录像,Facebook工程师Edison Gao和Michael Bevilacqua-Linn做了简短的介绍。到天篷。)
标签:机器 跨语言 context 固定 sof end 搜索 gen ado
原文地址:https://www.cnblogs.com/cutepig/p/13058218.html